tensorflow 车牌识别项目(一)
目录
- 吐槽
- 前言
- 一 数据解析
- 二 level 1训练
- 三 level 2训练
- 四 测试
- 五 demo
吐槽
最近为了找工作,丰富自己的项目经历就做了一个车牌识别的项目,思想大致是参考https://blog.csdn.net/u011995719/article/details/79435615的思想,但是他是用的caffe框架,对caffe一窍不通的我当然不能妥协去学caffe。于是自己走上了tensorflow的折腾之路。复现嘛,我就用教程上的网络结构,我开始试着用tensorflow写mobilinet。什么深度卷积、点卷积一大堆东西现学。自己也尝试写了一个版本,MobileNet V2 tensorflow复现.
后来训练了很久效果也是极差,开始怀疑人生,就是那种半夜三点还在写BUG的感觉。后来越想越不靠谱,就去学习了YOLO,MTCNN来试着做这个,又是漫长的看源码的过程。不得不说别人写的代码是真的难读,但风格又是我需要学习的。mtcnn的源码是真的多,估计上万行了,头大…。将整个mtcnn流程走完一通后绝望地发现有漏检的情况,而且只是粗糙地定位到车牌区域,角点预测并不好。整天脑子里都是放弃吧,放弃吧…。自己就休息了两天,打打Lol,陪陪妹子逛逛街吃吃饭,泪流满面地发现这样的生活才是我想要的o(╥﹏╥)o,qtmd程序猿。

好了不说了,我爸还在努力,我再坚持一下,咳咳,继续搬砖(T_T)
前言
车牌识别主要分成两个步骤,一是定位车牌位置。二是识别出车牌字符。
此博客仅记录自己摸索的过程中的一些基本过程,后续优化后的最终的结果:识别率达到99%以上,集成定位+识别模型移植到Android端的单张测试速度32ms,完全达到了商用级别,这个就不公开了。
本节内容为车牌定位
所有代码:
链接:https://pan.baidu.com/s/1JPmy684xxsIXJge8CJ1HTg
提取码:xd7r
一 数据解析
-
关于车牌数据形式:原数据是以json文件存储,图像以base64编码在json文件中,所以第一步就是从json文件中解析出图像和标签。标签为车牌的4个角点。
运行gen_raw_img.py,将划分训练集和测试集,共生成4个文件,训练集和测试集图像和记录图像路径的txt文件。4个角点一共8个值
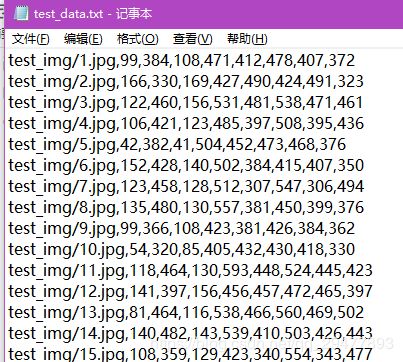
运行check_landmark.py检查下数据,从测试集中随机选取5个图像显示。图像大小为960*540,这里截图太大直截取了一部分。确认无误就可进行下一步
二 level 1训练
-
首先生成level1的训练数据。进入train目录运行gen_tfrecord.py,将生成各个阶段训练需要的数据。所以需要在gen_tfrecord.py文件中修改
level='l1'。运行完成后会在level_1\l1_tfrecord_data目录下生成tensorflow 的tfrecord文件。
-
网络结构在train/model.py中,没用Mobilinet,用这个网络发现效果变好了,(这里??大写的黑人问号),为了简单起见,我两个阶段的网络都是一样的,后续可以考虑优化
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 26 00:13:09 2020
@author: Ke
"""
import tensorflow as tf
from tensorflow.contrib import slim
def level1_net(inputs):
with slim.arg_scope([slim.conv2d],
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
weights_regularizer=slim.l2_regularizer(0.0005),
padding='same'):
net = slim.conv2d(inputs, num_outputs=16, kernel_size=[3,3], stride=2, scope="conv1")#24
net = slim.conv2d(net,num_outputs=24,kernel_size=[3,3],stride=2,scope="conv2")
net = slim.conv2d(net,num_outputs=24,kernel_size=[3,3],stride=1,scope="conv3")#12
net = slim.conv2d(net,num_outputs=32,kernel_size=[3,3],stride=2,scope="conv4")
net = slim.conv2d(net,num_outputs=32,kernel_size=[3,3],stride=1,scope="conv5")#6
net = slim.conv2d(net,num_outputs=64,kernel_size=[3,3],stride=2,scope="conv6")
net = slim.conv2d(net,num_outputs=64,kernel_size=[3,3],stride=1,scope="conv7")#3
fc_flatten = slim.flatten(net)
fc1 = slim.fully_connected(fc_flatten, num_outputs=256,scope="fc1")
fc2 = slim.fully_connected(fc1, num_outputs=8,scope="fc2")
return fc2
def level2_net(inputs):
with slim.arg_scope([slim.conv2d],
weights_initializer=slim.xavier_initializer(),
biases_initializer=tf.zeros_initializer(),
weights_regularizer=slim.l2_regularizer(0.0005),
padding='same'):
net = slim.conv2d(inputs, num_outputs=16, kernel_size=[3,3], stride=2, scope="conv1")#24
net = slim.conv2d(net,num_outputs=24,kernel_size=[3,3],stride=2,scope="conv2")
net = slim.conv2d(net,num_outputs=24,kernel_size=[3,3],stride=1,scope="conv3")#12
net = slim.conv2d(net,num_outputs=32,kernel_size=[3,3],stride=2,scope="conv4")
net = slim.conv2d(net,num_outputs=32,kernel_size=[3,3],stride=1,scope="conv5")#6
net = slim.conv2d(net,num_outputs=64,kernel_size=[3,3],stride=2,scope="conv6")
net = slim.conv2d(net,num_outputs=64,kernel_size=[3,3],stride=1,scope="conv7")#3
fc_flatten = slim.flatten(net)
fc1 = slim.fully_connected(fc_flatten, num_outputs=256,scope="fc1")
fc2 = slim.fully_connected(fc1, num_outputs=8,scope="fc2")
return fc2
- 训练在train/train.py文件中修改为
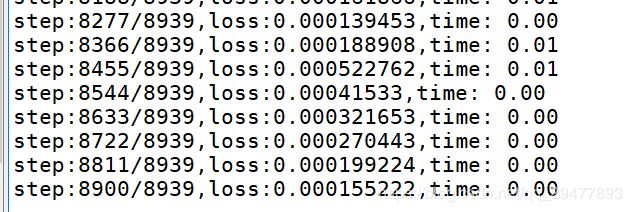
level='l1',第一阶段的训练。
训练情况如下
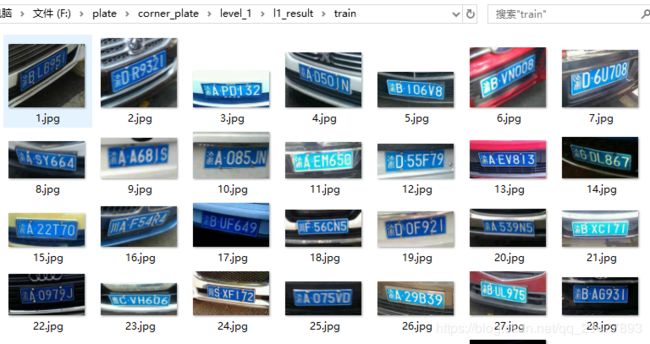
- 训练结束后就是生成训练level2的数据。我们根据level1的预测结果,生成一个最小矩形框,然后将矩形框扩张50个像素点,(这个值也可以更改)超过图像范围的就取图像边界。
运行level_1下的gen_l2_data.py,将生成l1_result文件夹,图像如下。
(可选)为了更好地观察预测结果,我只将测试集的图像在原图中画出真实角点,预测角点,以及预测角点向外拓展的最小矩形框。结果保存在draw_l1_result中。(训练集有可以这样做,但数据量太大了,我嫌麻烦)

红色为真实坐标、绿色为预测坐标、绿色矩形为裁剪范围。
我们将所有数据都预测并裁剪作为level2的输入
三 level 2训练
- 同样运行目录train中的
gen_tfrecord.py,注意修改level='l2'。将在level_2中生成l2_tfrecord_data
- 同样train.py中修改
level='l2',然后运行train.py
四 测试
为了能测试各个阶段的结果。可以运行train中的evaluate.py,同样也要修改是测试哪一阶段
比如测试level1的结果,显示的就是原图

第二阶段的结果是在crop后的图像上测试,显示的部分图

五 demo
最后我将两个模型结合起来,代码在Detect文件夹中,百度找了张网图运行demo.py。识别出角点后对倾斜的车牌矫正。

emmm,还行把。