第九章 Java I/O与NIO
文章目录
- Java IO
- 字节与字符
- Java 编码格式
- File类
- RandomAccessFile
- IO流
- IO流 简介
- IO流 分类
- IO流 四大基类
- Java NIO
- NIO 简介
- 通道与缓冲区
- 选择器
Java IO
字节与字符
在Java中有输入、输出两种IO流,每种输入、输出流又分为字节流和字符流两大类。关于字节,我们在学习8大基本数据类型中都有了解,每个字节(byte)有8bit组成,每种数据类型又几个字节组成等。关于字符,我们可能知道代表一个汉字或者英文字母。
但是字节与字符之间的关系是怎样的?
Java采用unicode编码,2个字节来表示一个字符,这点与C语言中不同,C语言中采用ASCII,在大多数系统中,一个字符通常占1个字节,但是在0~127整数之间的字符映射,unicode向下兼容ASCII。而Java采用unicode来表示字符,一个中文或英文字符的unicode编码都占2个字节。但如果采用其他编码方式,一个字符占用的字节数则各不相同。可能有点晕,举个例子解释下。
例如:Java中的String类是按照unicode进行编码的,当使用String(byte[] bytes, String encoding)构造字符串时,encoding所指的是bytes中的数据是按照那种方式编码的,而不是最后产生的String是什么编码方式,换句话说,是让系统把bytes中的数据由encoding编码方式转换成unicode编码。如果不指明,bytes的编码方式将由jdk根据操作系统决定。
getBytes(String charsetName)使用指定的编码方式将此String编码为 byte 序列,并将结果存储到一个新的 byte 数组中。如果不指定将使用操作系统默认的编码方式,我的电脑默认的是GBK编码。
public class Hel {
public static void main(String[] args){
String str = "你好hello";
int byte_len = str.getBytes().length;
int len = str.length();
System.out.println("字节长度为:" + byte_len);
System.out.println("字符长度为:" + len);
System.out.println("系统默认编码方式:" + System.getProperty("file.encoding"));
}
}
输出结果
字节长度为:9
字符长度为:7
系统默认编码方式:GBK
这是因为:在 GB 2312 编码或 GBK 编码中,一个英文字母字符存储需要1个字节,一个汉字字符存储需要2个字节。 在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符存储需要2个字节,一个汉字字符储存需要3到4个字节(Unicode扩展区的一些汉字存储需要4个字节)。在UTF-32编码中,世界上任何字符的存储都需要4个字节。
简单来讲,一个字符表示一个汉字或英文字母,具体字符与字节之间的大小比例视编码情况而定。有时候读取的数据是乱码,就是因为编码方式不一致,需要进行转换,然后再按照unicode进行编码。
Java 编码格式
计算机中存储信息的最小单元是1byte即8bit,所以能表示的字符范围是 0~255 个,人类要表示的符号太多,无法用一个字节来完全表示,需要一个新的数据结构char来表示这些字符。char与byte之间转换需要编码与解码。
编码:字节(Byte = 8bit 默认数据的最小单位)与字符(Character = 2byte)的转换方式。
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
编码规范
- ASCII
ASCII码一共规定了128个字符的编码,用一个字节的低 7 位表示,0~31 是控制字符如换行回车删除等;32~126 是打印字符,可以通过键盘输入并且能够显示出来。 - ISO-8859-1
ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,共有256个字符。 - GB2312
- GBK
中文字符占 2 个字节,英文字符占 1 个字节; - UTF-16
中文字符和英文字符都占 2 个字节; - UTF-8
UTF-8就是在互联网上使用最广的一种Unicode的实现方式。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
中文字符占 3 个字节,英文字符占 1 个字节;
Java中需要编码的场景包括: - I/O操作中存在的编码
Reader类是Java I/O中读字符的父类,InputStream类是读字节的父类,通过InputStreamReader类将字节转换为字符。
同理,Writer是写字符的父类,OutputStram类是写字节的父类,通过OutputStreamWriter将字符转换为字节。
public class File_Stream {
public static void main(String[] args) throws IOException {
Scanner sca=new Scanner(System.in);
//写文件
System.out.print("请输入文件名:");
String name=sca.next();
File file=new File(name+".txt");//文件名 相对路径(项目名根目录下)
// FileOutputStream fs=new FileOutputStream(file);//如果文件存在 覆盖
FileOutputStream fos=new FileOutputStream(file,true);//true表示追加,如果文件存在 向里面继续添加内容
System.out.println("请输入写入的内容:");
String str=sca.next();
byte bytes[]=str.getBytes(); //FileOutputStream 是基于字节流 把要写入的信息 保存到字节数组中
fos.write(bytes,0,bytes.length);//将字节数组中全部内容写到文件中 从0—数组的长度
fos.close();//关闭流
System.out.println("文件写入成功!");
//读文件
FileInputStream fis=new FileInputStream(file);
byte bt[]=new byte[1024];//1KB 每次最多读取的1KB 根据文件大小而定
int temp=0;
while((temp=fis.read(bt))!=-1){ //将数据保存到数组(缓冲区)中 并返回读取的字节数 -1表示读完了
System.out.println(new String(bt,0,temp));//输出数组中保存内容 按照每次读取的字节数
}
fis.close();
}
}
- 内存中的编码(String 的 编码方式)
Java 中用 String 表示字符串,所以 String 类就提供转换到字节的方法,也支持将字节转换为字符串的构造函数。
String s = "这是一段中文字符串";
byte[] b = s.getBytes("UTF-8"); // (字符转字节)将字符串所表示的字符按照charset编码,并以字节方式表示。
String n = new String(b,"UTF-8"); // (字节转字符)将字节数组按照charset编码进行组合识别,最后转换为unicode存储
File类
File类是java.io包下代表与平台无关的文件和目录,也就是说,如果希望在程序中操作文件和目录,都可以通过File类来完成。
① 构造函数
//构造函数File(String pathname)
File f1 =new File("c:\\abc\\1.txt");
//File(String parent,String child)
File f2 =new File("c:\\abc","2.txt");
//File(File parent,String child)
File f3 =new File("c:"+File.separator+"abc");//separator 跨平台分隔符
File f4 =new File(f3,"3.txt");
System.out.println(f1);//c:\abc\1.txt
路径分隔符: windows: “/” “” 都可以 linux/unix: “/”
注意:如果windows选择用"“做分割符的话,那么请记得替换成”",因为Java中"“代表转义字符
所以推荐都使用”/",也可以直接使用代码File.separator,表示跨平台分隔符。
路径:
- 相对路径:
./表示当前路径(默认情况下,java.io 包中的类总是根据当前用户目录来分析相对路径名。此目录由系统属性user.dir 指定,通常是 Java 虚拟机的调用目录。)
…/表示上一级路径- 绝对路径:
绝对路径名是完整的路径名,不需要任何其他信息就可以定位自身表示的文件
② 创建与删除方法
//如果文件存在返回false,否则返回true并且创建文件
boolean createNewFile();
//创建一个File对象所对应的目录,成功返回true,否则false。且File对象必须为路径而不是文件。只会创建最后一级目录,如果上级目录不存在就抛异常。
boolean mkdir();
//创建一个File对象所对应的目录,成功返回true,否则false。且File对象必须为路径而不是文件。创建多级目录,创建路径中所有不存在的目录
boolean mkdirs() ;
//如果文件存在返回true并且删除文件,否则返回false
boolean delete();
//在虚拟机终止时,删除File对象所表示的文件或目录。
void deleteOnExit();
③ 判断方法
boolean canExecute() ;//判断文件是否可执行
boolean canRead();//判断文件是否可读
boolean canWrite();//判断文件是否可写
boolean exists();//判断文件是否存在
boolean isDirectory();//判断是否是目录
boolean isFile();//判断是否是文件
boolean isHidden();//判断是否是隐藏文件或隐藏目录
boolean isAbsolute();//判断是否是绝对路径 文件不存在也能判断
③获取方法
String getName();//返回文件或者是目录的名称
String getPath();//返回路径
String getAbsolutePath();//返回绝对路径
String getParent();//返回父目录,如果没有父目录则返回null
long lastModified();//返回最后一次修改的时间
long length();//返回文件的长度
File[] listRoots();// 列出所有的根目录(Window中就是所有系统的盘符)
String[] list() ;//返回一个字符串数组,给定路径下的文件或目录名称字符串
String[] list(FilenameFilter filter);//返回满足过滤器要求的一个字符串数组
File[] listFiles();//返回一个文件对象数组,给定路径下文件或目录
File[] listFiles(FilenameFilter filter);//返回满足过滤器要求的一个文件对象数组
其中包含了一个重要的接口FileNameFilter,该接口是个文件过滤器,包含了一个accept(File dir,String name)方法,该方法依次对指定File的所有子目录或者文件进行迭代,按照指定条件,进行过滤,过滤出满足条件的所有文件。
// 文件过滤
File[] files = file.listFiles(new FilenameFilter() {
@Override
public boolean accept(File file, String filename) {
return filename.endsWith(".mp3");
}
});
file目录下的所有子文件如果满足后缀是.mp3的条件的文件都会被过滤出来。
RandomAccessFile
- 简介
RandomAccessFile既可以读取文件内容,也可以向文件输出数据。同时,RandomAccessFile支持“随机访问”的方式,程序快可以直接跳转到文件的任意地方来读写数据。
由于RandomAccessFile可以自由访问文件的任意位置,所以如果需要访问文件的部分内容,而不是把文件从头读到尾,使用RandomAccessFile将是更好的选择。
与OutputStream、Writer等输出流不同的是,RandomAccessFile允许自由定义文件记录指针,RandomAccessFile可以不从开始的地方开始输出,因此RandomAccessFile可以向已存在的文件后追加内容。如果程序需要向已存在的文件后追加内容,则应该使用RandomAccessFile。
RandomAccessFile的方法虽然多,但它有一个最大的局限,就是只能读写文件,不能读写其他IO节点。
RandomAccessFile的一个重要使用场景就是网络请求中的多线程下载及断点续传。
- 方法
- RandomAccessFile的构造函数
RandomAccessFile类有两个构造函数,其实这两个构造函数基本相同,只不过是指定文件的形式不同——一个需要使用String参数来指定文件名,一个使用File参数来指定文件本身。除此之外,创建RandomAccessFile对象时还需要指定一个mode参数,该参数指定RandomAccessFile的访问模式,一共有4种模式。
“r”: 以只读方式打开。调用结果对象的任何 write 方法都将导致抛出 IOException。
“rw”: 打开以便读取和写入。
“rws”: 打开以便读取和写入。相对于 “rw”,“rws” 还要求对“文件的内容”或“元数据”的每个更新都同步写入到基础存储设备。
“rwd” : 打开以便读取和写入,相对于 “rw”,“rwd” 还要求对“文件的内容”的每个更新都同步写入到基础存储设备。
- RandomAccessFile的重要方法
RandomAccessFile既可以读文件,也可以写文件,所以类似于InputStream的read()方法,以及类似于OutputStream的write()方法,RandomAccessFile都具备。除此之外,RandomAccessFile具备两个特有的方法,来支持其随机访问的特性。
RandomAccessFile对象包含了一个记录指针,用以标识当前读写处的位置,当程序新创建一个RandomAccessFile对象时,该对象的文件指针记录位于文件头(也就是0处),当读/写了n个字节后,文件记录指针将会后移n个字节。除此之外,RandomAccessFile还可以自由移动该记录指针。下面就是RandomAccessFile具有的两个特殊方法,来操作记录指针,实现随机访问:
long getFilePointer( ):返回文件记录指针的当前位置
void seek(long pos):将文件指针定位到pos位置
- 使用
利用RandomAccessFile实现文件的多线程下载,即多线程下载一个文件时,将文件分成几块,每块用不同的线程进行下载。下面是一个利用多线程在写文件时的例子,其中预先分配文件所需要的空间,然后在所分配的空间中进行分块,然后写入:
/**
* 测试利用多线程进行文件的写操作
*/
public class Test {
public static void main(String[] args) throws Exception {
// 预分配文件所占的磁盘空间,磁盘中会创建一个指定大小的文件
RandomAccessFile raf = new RandomAccessFile("D://abc.txt", "rw");
raf.setLength(1024*1024); // 预分配 1M 的文件空间
raf.close();
// 所要写入的文件内容
String s1 = "第一个字符串";
String s2 = "第二个字符串";
String s3 = "第三个字符串";
String s4 = "第四个字符串";
String s5 = "第五个字符串";
// 利用多线程同时写入一个文件
new FileWriteThread(1024*1,s1.getBytes()).start(); // 从文件的1024字节之后开始写入数据
new FileWriteThread(1024*2,s2.getBytes()).start(); // 从文件的2048字节之后开始写入数据
new FileWriteThread(1024*3,s3.getBytes()).start(); // 从文件的3072字节之后开始写入数据
new FileWriteThread(1024*4,s4.getBytes()).start(); // 从文件的4096字节之后开始写入数据
new FileWriteThread(1024*5,s5.getBytes()).start(); // 从文件的5120字节之后开始写入数据
}
// 利用线程在文件的指定位置写入指定数据
static class FileWriteThread extends Thread{
private int skip;
private byte[] content;
public FileWriteThread(int skip,byte[] content){
this.skip = skip;
this.content = content;
}
public void run(){
RandomAccessFile raf = null;
try {
raf = new RandomAccessFile("D://abc.txt", "rw");
raf.seek(skip);
raf.write(content);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
raf.close();
} catch (Exception e) {
}
}
}
}
}
当RandomAccessFile向指定文件中插入内容时,将会覆盖掉原有内容。如果不想覆盖掉,则需要将原有内容先读取出来,然后先把插入内容插入后再把原有内容追加到插入内容后。
IO流
IO流 简介
Java的IO流是实现输入/输出的基础,它可以方便地实现数据的输入/输出操作,在Java中把不同的输入/输出源抽象表述为"流"。流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流有输入和输出,输入时是流从数据源流向程序。输出时是流从程序传向数据源,而数据源可以是内存,文件,网络或程序等。
IO流 分类
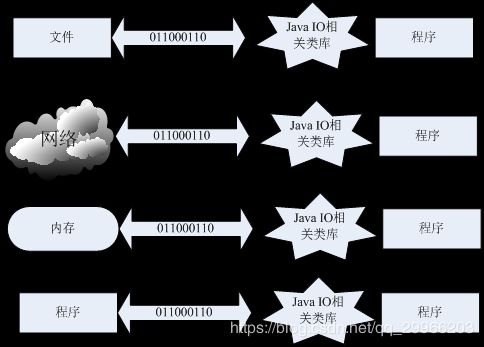
- 输入流和输出流
根据数据流向不同分为:输入流和输出流。
输入流:程序从数据源中读取数据。
输出流:程序向数据源中写入数据。
如下如所示:对程序而言,向右的箭头,表示输入,向左的箭头,表示输出。
2. 字节流和字符流
字节流和字符流和用法几乎完全一样,区别在于字节流和字符流所操作的数据单元不同。
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。字节流和字符流的区别:
(1)读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
(2)处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。
- 节点流和处理流
按照流的角色来分,可以分为节点流和处理流。
可以从/向一个特定的IO设备(如磁盘、网络)读/写数据的流,称为节点流,节点流也被成为低级流。
处理流是对一个已存在的流进行连接或封装,通过封装后的流来实现数据读/写功能,处理流也被称为高级流。
//节点流,直接传入的参数是IO设备
FileInputStream fis = new FileInputStream("test.txt");
//处理流,直接传入的参数是流对象
BufferedInputStream bis = new BufferedInputStream(fis);
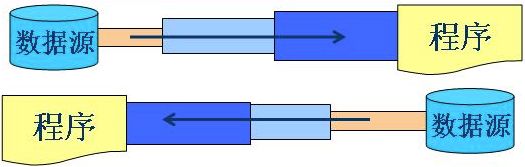
当使用处理流进行输入/输出时,程序并不会直接连接到实际的数据源,没有和实际的输入/输出节点连接。使用处理流的一个明显好处是,只要使用相同的处理流,程序就可以采用完全相同的输入/输出代码来访问不同的数据源,随着处理流所包装节点流的变化,程序实际所访问的数据源也相应地发生变化。
实际上,Java使用处理流来包装节点流是一种典型的装饰器设计模式,通过使用处理流来包装不同的节点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入/输出功能。
IO流 四大基类
根据流的流向以及操作的数据单元不同,将流分为了四种类型,每种类型对应一种抽象基类。这四种抽象基类分别为:InputStream,Reader,OutputStream以及Writer。四种基类下,对应不同的实现类,具有不同的特性。在这些实现类中,又可以分为节点流和处理流。下面就是整个由着四大基类支撑下,整个IO流的框架图。

InputStream,Reader,OutputStream以及Writer,这四大抽象基类,本身并不能创建实例来执行输入/输出,但它们将成为所有输入/输出流的模版,所以它们的方法是所有输入/输出流都可以使用的方法。类似于集合中的Collection接口。
- InputStream
InputStream 是所有的输入字节流的父类,它是一个抽象类,主要包含三个方法:
//读取一个字节并以整数的形式返回(0~255),如果返回-1已到输入流的末尾。
int read() ;
//读取一系列字节并存储到一个数组buffer,返回实际读取的字节数,如果读取前已到输入流的末尾返回-1。
int read(byte[] buffer) ;
//读取length个字节并存储到一个字节数组buffer,从off位置开始存,最多len, 返回实际读取的字节数,如果读取前以到输入流的末尾返回-1。
int read(byte[] buffer, int off, int len) ;
实例
// 读取f盘下该文件f://hell/test.txt
InputStream inputStream = new FileInputStream(new File("f://hello//test.txt"));
int i = 0;
//一次读取一个字节
while ((i = inputStream.read()) != -1) {
System.out.print((char) i + " ");
}
//关闭IO流
inputStream.close();
- Reader
Reader 是所有的输入字符流的父类,它是一个抽象类,主要包含三个方法:
//读取一个字符并以整数的形式返回(0~255),如果返回-1已到输入流的末尾。
int read() ;
//读取一系列字符并存储到一个数组buffer,返回实际读取的字符数,如果读取前已到输入流的末尾返回-1。
int read(char[] cbuf) ;
//读取length个字符,并存储到一个数组buffer,从off位置开始存,最多读取len,返回实际读取的字符数,如果读取前以到输入流的末尾返回-1。
int read(char[] cbuf, int off, int len)
实例
//使用默认编码
FileReader reader = new FileReader("test.txt");
int len;
while ((len = reader.read()) != -1) {
System.out.print((char) len);
}
reader.close();
对比InputStream和Reader所提供的方法,就不难发现两个基类的功能基本一样的,只不过读取的数据单元不同。
在执行完流操作后,要调用close()方法来关系输入流,因为程序里打开的IO资源不属于内存资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件IO资源。
- OutputStream
OutputStream 是所有的输出字节流的父类,它是一个抽象类,主要包含如下四个方法:
//向输出流中写入一个字节数据,该字节数据为参数b的低8位。
void write(int b) ;
//将一个字节类型的数组中的数据写入输出流。
void write(byte[] b);
//将一个字节类型的数组中的从指定位置(off)开始的,len个字节写入到输出流。
void write(byte[] b, int off, int len);
//将输出流中缓冲的数据全部写出到目的地。
void flush();
实例
OutputStream outputStream = new FileOutputStream(new File("test.txt"));
// 写入数据
outputStream.write("ABCD".getBytes());
// 关闭IO流
outputStream.close();
- Writer
Writer 是所有的输出字符流的父类,它是一个抽象类,主要包含如下六个方法:
//向输出流中写入一个字符数据,该字节数据为参数b的低16位。
void write(int c);
//将一个字符类型的数组中的数据写入输出流,
void write(char[] cbuf)
//将一个字符类型的数组中的从指定位置(offset)开始的,length个字符写入到输出流。
void write(char[] cbuf, int offset, int length);
//将一个字符串中的字符写入到输出流。
void write(String string);
//将一个字符串从offset开始的length个字符写入到输出流。
void write(String string, int offset, int length);
//将输出流中缓冲的数据全部写出到目的地。
void flush()
实例
FileWriter writer = new FileWriter("test.txt");
// 写入数据
writer.write("ABCD".getBytes());
// 关闭IO流
writer.close();
可以看出,Writer比OutputStream多出两个方法,主要是支持写入字符和字符串类型的数据。
使用Java的IO流执行输出时,不要忘记关闭输出流,关闭输出流除了可以保证流的物理资源被回收之外,还能将输出流缓冲区的数据flush到物理节点里(因为在执行close()方法之前,自动执行输出流的flush()方法)
Java NIO
NIO 简介
新的输入/输出 (NIO) 库是在 JDK 1.4 中引入的,弥补了原来的 I/O 的不足,提供了高速的、面向块的 I/O。
NIO 与普通 I/O 的区别主要有以下两点:
- NIO 是非阻塞的;
当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
blocking IO的特点就是在IO执行的两个阶段都被block了。
non-blocking IO的特点是当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。所以,用户进程其实是需要不断的主动询问kernel数据好了没有。 - NIO 面向块,I/O 面向流。
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
通道与缓冲区
- 通道
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道包括以下类型:
- FileChannel:从文件中读写数据;
- DatagramChannel:通过 UDP 读写网络中数据;
- SocketChannel:通过 TCP 读写网络中数据;
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
- 缓冲区
发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区包括以下类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
缓冲区状态变量包括:
- capacity:最大容量;
- position:当前已经读写的字节数;
- limit:还可以读写的字节数。
状态变量的改变过程举例:
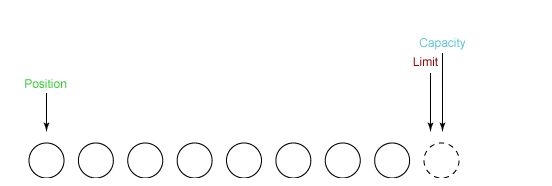
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
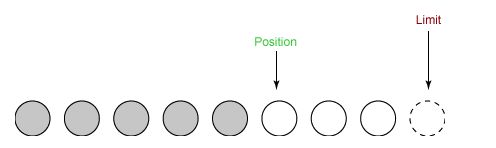
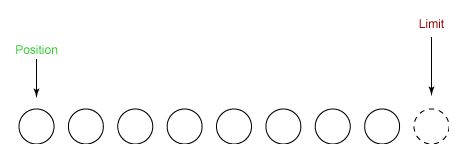
② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
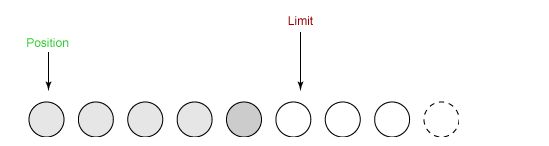
④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
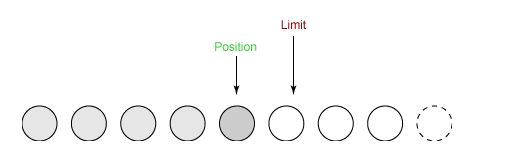
⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
选择器
- 简介
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
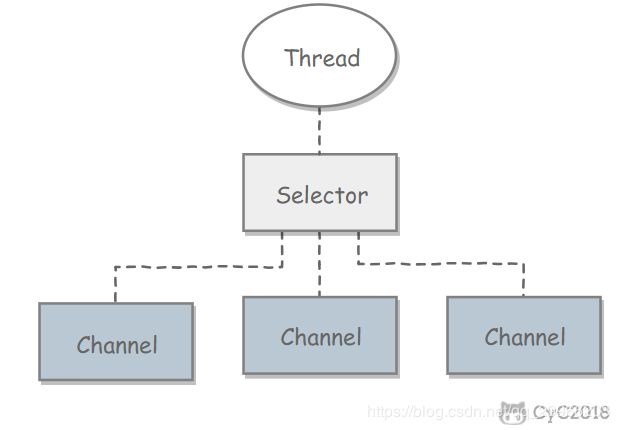
NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件,对于 IO 密集型的应用具有很好地性能。
应该注意的是,只有Socket Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
- 原理
IO multiplexing —— 整体 blocking 局部 non-blocking
当用户进程调用了select,那么整个进程会被block,而同时,kernel通过不断轮询,“监视”所有select负责的所有kernel(socket),当任何一个kernel(socket)中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
使用IO multiplexing性能不一定比使用multi-threading + blocking IO效率高,使用select的优势在于它可以同时处理多个connection。
在IO multiplexing Model中,实际中,对于每一个socket channel,一般都设置成为non-blocking,但是,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket channel IO给block。 - 使用
- 创建选择器
Selector selector = Selector.open();
- 将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;
可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
- 监听事件
int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
- 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
- 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}
- 套接字 NIO 实例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}