shardingsphere之sharding-jdbc分库分表学习笔记
shardingsphere之sharding-jdbc分库分表学习笔记
- 引言
- 小插曲
- 重要提示
- sharding-jdbc简介
- 概念
- 特点
- 使用情况
- 从零开始整合sharding-jdbc
- 整合前的思考
- 场景模拟
- 搭建项目
- 1. 建库建表
- 2.在pom.xml加入依赖
- 3.编写yml配置文件
- yml配置文件
- 注意事项
- 4.基础CRUD代码生成
- 工具代码
- 注意事项
- 5.项目运行
- 分布式事务
- 弹性伸缩
- 配置zookeeper
- 结语
- 相关链接
引言
随着业务数据量的变大,单库单表已经不能满足需求了。当单表数据量超过五百万行,查询性能急剧下降。分库分表迫在眉睫,寻找一个简单实用的解决方案相信是很多小伙伴的想法。
我在看了好多的博客之后遇到了开源数据库中间件mycat和shardingsphere(前身是sharding-jdbc),经过一番比较之后,我选了京东开源的shardingsphere作为我的解决方案。
写这篇文章的目的有两个,一来是帮助刚入门学习shardingsphere的童鞋快速上手,减少时间成本,先看下怎么用再去看官方文档可以达到事半功倍的效果;二来是记录自己在学习过程中遇到的问题,方便以后在项目中的使用。
小插曲
其实一开始我选的是mycat作为解决方案,当时看到文档齐全,又有官方群啥的,以为很适合我。后面二月初研究了几天文档然后自己学着搭建,结果没成功。
在官方群问问题被索要红包,以前是问个问题要发五十块的红包,现在要发二十块。前期学习成本太大,毕竟能不能用到项目还是未知数;而且群主整天在吹自己如何牛逼,贩卖中年焦虑(知乎可查),到后面一查mycat几乎不更新了,issues基本没人理,本身bug还是蛮多的,感觉在走向衰退和灭完,最后选择了shardingsphere。
重要提示
用于演示的代码和重要的参考链接已经放到文章的末尾,有需要的童鞋可直接下载查看。
sharding-jdbc简介
概念
太多的理论知识我就不赘述了,麻烦自己到官网去看。
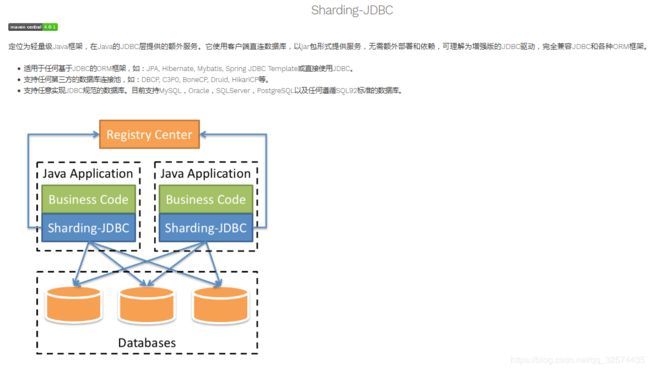
特点
一款简单容易上手的数据库中间件,很好的帮助我们处理分库分表的问题,不需要对现有的业务代码太多的修改,减少时间成本。
使用情况
目前生产环境已使用的公司

从零开始整合sharding-jdbc
整合前的思考
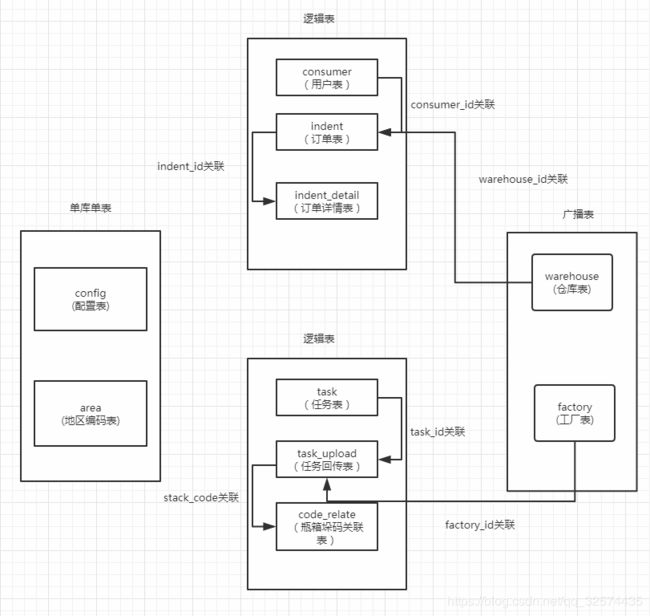
首先你要对业务需要用到的表有一个清晰的认识。哪些表不需要拆分,哪些表需要拆分,表跟表之间是否存在关联。通过阅读官网和我的理解,我觉得主要分为这几种表:
- 单库单表
这种表数据量不大,小于十万这样,而且跟其他表没有关联。这样的表不需要拆分,放在一个默认库中即可。比如:配置表,地区编码表。
- 广播表
这种表数据量不大,没有必要拆分;但是跟其他表有关联关系。在每个库都保存一个完整表,当读取数据的时候随机路由到任一库,当写入数据时每个库下的表都写入。
- 逻辑表
数据量较大需要拆分的表。比如说订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
- 绑定表
按我的理解就是父子表,常见的就是订单表和订单详情表,通过订单id关联。这种类型的表数据量大也是需要拆分的。
场景模拟
为了加深对sharding-jdbc的理解,我在这里模拟了一个场景,基本涵盖了常见的情况,顺便把实现步骤和使用过程的问题也提一提。
搭建项目
1. 建库建表
按照前面表的关系图,我们可以划分一个默认库(存放单库单表和广播表)和三个库(存放逻辑表);再额外建一个库存放所有的表便于代码生成,如下所示。sql文件放在git地址的sql目录下。
用于代码生成的库表
generator
--area
--config
--factory
--warehouse
--code_relate
--customer
--indent_detail
--indent
--task_upload
--task
业务需要的库表
data_source
--area
--config
--factory
--warehouse
data_source0
--code_relate0
--code_relate1
--customer0
--customer1
--factory
--indent_detail0
--indent_detail1
--indent0
--indent1
--task_upload0
--task_upload1
--task0
--task1
--warehouse
data_source1
--code_relate0
--code_relate1
--customer0
--customer1
--factory
--indent_detail0
--indent_detail1
--indent0
--indent1
--task_upload0
--task_upload1
--task0
--task1
--warehouse
data_source2
--code_relate0
--code_relate1
--customer0
--customer1
--factory
--indent_detail0
--indent_detail1
--indent0
--indent1
--task_upload0
--task_upload1
--task0
--task1
--warehouse
2.在pom.xml加入依赖
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
${sharding-jdbc-spring-boot-starter.version}
org.apache.shardingsphere
sharding-jdbc-orchestration-spring-boot-starter
${sharding-jdbc-orchestration-spring-boot-starter.version}
org.apache.shardingsphere
sharding-orchestration-reg-zookeeper-curator
${sharding-orchestration-reg-zookeeper-curator.version}
3.编写yml配置文件
yml配置文件
spring:
shardingsphere:
props:
sql: #sql打印
show: true
#executor: #工作线程数量,默认值: CPU核数
# size: 4
orchestration: ###数据库治理功能 配置了zk但是看不到节点
name: spring_boot_ds_sharding #治理实例名称
overwrite: true #本地配置是否覆盖注册中心配置。如果可覆盖,每次启动都以本地配置为准
registry:
type: zookeeper #配置中心类型。如:zookeeper
namespace: orchestration-spring-boot-sharding-test #注册中心的命名空间
server-lists: localhost:2181 #连接注册中心服务器的列表。包括IP地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181
digest: admin #连接注册中心的权限令牌。缺省为不需要权限验证
operation-timeout-milliseconds: 500 #操作超时的毫秒数,默认500毫秒
max-retries: 3 #连接失败后的最大重试次数,默认3次
retry-interval-milliseconds: 500 #重试间隔毫秒数,默认500毫秒
time-to-live-seconds: 60 #临时节点存活秒数,默认60秒
props: #配置中心其它属性
author: huangjg
blog-url: https://www.flyxiaopang.top/
datasource: #数据源配置
names: db,db0,db1,db2 #数据库别名
db: #数据源具体配置,这个可作为默认库
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/data_source?characterEncoding=utf-8
username: root
password: root
db0: #数据源具体配置
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/data_source0?characterEncoding=utf-8
username: root
password: root
db1: #数据源具体配置
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/data_source1?characterEncoding=utf-8
username: root
password: root
db2: #数据源具体配置
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/data_source2?characterEncoding=utf-8
username: root
password: root
sharding: ##分库分表规则
default-data-source-name: db #默认数据源,放置不需要分片的表和广播表
broadcast-tables: factory,warehouse #广播表,每个库都有独立的表
binding-tables: indent,indent_detail,task_upload,code_relate ##绑定表配置
default-database-strategy: #默认的分库规则,如果逻辑表没单独配置则使用这个
inline:
sharding-column: customer_id #默认按照customer_id分库,避免跨库查询
algorithm-expression: db$->{customer_id % 3}
tables: #逻辑表配置
config: ###单库单表,使用UUID作为主键
actual-data-nodes: db.config
key-generator:
column: code
type: UUID
customer:
actual-data-nodes: db$->{0..2}.customer$->{0..1} #具体的数据节点
table-strategy: ##分表策略
inline:
sharding-column: customer_name #根据hash值取模确定落在哪张表
algorithm-expression: customer$->{Math.abs(customer_name.hashCode() % 2)}
key-generator: #配置主键生成策略,默认使用SNOWFLAKE
column: customer_id
type: SNOWFLAKE
props:
worker:
id: 20200422
indent:
actual-data-nodes: db$->{0..2}.indent$->{0..1}
table-strategy:
inline:
sharding-column: indent_id
algorithm-expression: indent$->{indent_id % 2}
key-generator:
column: indent_id
type: SNOWFLAKE
indent_detail:
actual-data-nodes: db$->{0..2}.indent_detail$->{0..1}
table-strategy:
inline:
sharding-column: indent_id
algorithm-expression: indent_detail$->{indent_id % 2}
key-generator:
column: detail_id
type: SNOWFLAKE
task:
actual-data-nodes: db$->{0..2}.task$->{0..1} #具体的数据节点
database-strategy: #分库规则
inline:
sharding-column: task_id
algorithm-expression: db$->{task_id % 3}
table-strategy:
inline:
sharding-column: task_id
algorithm-expression: task$->{task_id % 2}
task_upload:
actual-data-nodes: db$->{0..2}.task_upload$->{0..1} #具体的数据节点
database-strategy: #分库规则
inline:
sharding-column: task_id
algorithm-expression: db$->{task_id % 3}
table-strategy:
inline:
sharding-column: stack_code
algorithm-expression: task_upload$->{Math.abs(stack_code.hashCode() % 2)}
key-generator:
column: upload_id
type: SNOWFLAKE
code_relate:
actual-data-nodes: db$->{0..2}.code_relate$->{0..1} #具体的数据节点
database-strategy: #分库规则
inline:
sharding-column: task_id
algorithm-expression: db$->{task_id % 3}
table-strategy:
inline:
sharding-column: stack_code
algorithm-expression: code_relate$->{Math.abs(stack_code.hashCode() % 2)}
key-generator:
column: relate_id
type: SNOWFLAKE
注意事项
(1)分片键分为分库键和分表键。
(2)主键生成默认使用SNOWFLAKE算法,使用UUID主键的话需要配置。
(3)如果分片键的值为long型,分片规则为分片字段取模即可;如果是String型,分片规则为分片字段的哈希值取模再求绝对值,因为哈希值取模之后也许会出现负数。
(4)逻辑表和绑定表配置建议,尽可能的让同一类型的数据落在同一个库中。比如用户的信息和他产生的订单以及订单详情,可以通过consumer_id作为分库键,indent_id作为分表键存放,这样如果查询命中分片键的话可以提高查询效率(少查了不必要的表)。
(5)绑定表建表的时候,子表最好增加分库键字段便于新增数据时确定落到哪个库中。比如用户表、订单表和订单详情表,consumer_id作为分库键,订单表需要有这个字段,订单详情表也需要这个字段,否则订单详情新增数据的时候会在每个库都新增数据,很明显是不合理的情况。
4.基础CRUD代码生成
工具代码
通过配置下方的文件连接generator库可以快速生成基础的CRUD代码
src/test/java/com/project/generator/MybatisGenerator.java
注意事项
(1)框架版本的选择,目前下方这个组合是正常的,其他的版本组合启动时可能会爆异常
mybatis-plus-boot-starter 3.1.0
sharding-jdbc-spring-boot-starter
3.1.0 spring-boot 2.0.6.RELEASE
其他版本组合时异常信息
The bean ‘dataSource’, defined in class path resource
[io/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class],
could not be registered. A bean with that name has already been
defined in class path resource
[com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class]
and overriding is disabled.
(2)实体主键类型的选择
- 如果主键是long型的话,可以这么配置,个人建议选择type = IdType.ID_WORKER这样更直白明了。否则会报错。
/**
* id
*/
@TableId(value = "id", type = IdType.ID_WORKER)
private Long id;
或者
/**
* id
*/
@TableId(value = "id", type = IdType.NONE)
private Long id;
使用type= ID.AUTO的异常信息
Caused by: java.sql.SQLException: Field ‘id’ doesn’t have a default
value at
com.mysql.jdbc.SQLError.createSQLException(SQLError.java:965) at
com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3978) at
com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3914) at
com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2530) at
com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2683) at
com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2495) at
com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1903)
at
com.mysql.jdbc.PreparedStatement.executeUpdateInternal(PreparedStatement.java:2124)
at
com.mysql.jdbc.PreparedStatement.executeBatchSerially(PreparedStatement.java:1801)
… 89 common frames omitted
- 如果主键是String型的话,可以这么配置。因为默认的是SNOWFLAKE生成,否则会插入一个long型的主键值导致报错。
/**
* 编号
*/
@TableId(value = "code", type = IdType.AUTO)
private String code;
或者
/**
* 编号
*/
@TableId(value = "code", type = IdType.UUID)
private String code;
5.项目运行
测试代码已经写到里面了,通过发起请求和观察控制台的sql你会发现逻辑SQL和真实SQL,从而发现他的查询规则:
1、如果表没配置规则,那么直接到默认库去访问
2、如果访问的是广播表,那么读的时候是随机路由到一个库,写的时候是全部库都写数据。
3、逻辑表查询,查询字段命中了分库键,那么路由到指定库下的所有表查询;命中了分表键,到所有库下指定表查询。如果都没命中,那么将发生笛卡尔积,进行全路由所有的库和表都查询一遍,效率不高。所以合理的配置分片规则是很重要的。
分布式事务
sharding-jdbc的XA分布式事务要到4.1.x版本才发布,不过可以在主版本测试,详情请看
ShardingTransactionType cannot be resolved to a type
弹性伸缩
这个也是在4.1.x发布,详情请看
弹性伸缩(Alpha)
配置zookeeper
目前我将zookeeper跑起来的时候不懂如何跟项目对接起来,如果有成功的同学麻烦将方法告知下。
结语
官网的文档比较详细和社区都是很活跃的,这些可以减少我们的学习成本,快速用于项目。如果在学习的过程中遇到问题可以多看看官方文档或者直接到github上面提issues,官方人员会很快给予答复的。
相关链接
演示代码地址
shardingsphere官网地址
shardingsphere github地址