Python爬虫实现获取斗鱼主播信息
先下载安装Python以及其编写软件
https://www.python.org/downloads/ Python下载官网
选择版本 下面使用的版本为3.6.5

根据自己的操作系统的位数选择
打开安装文件后

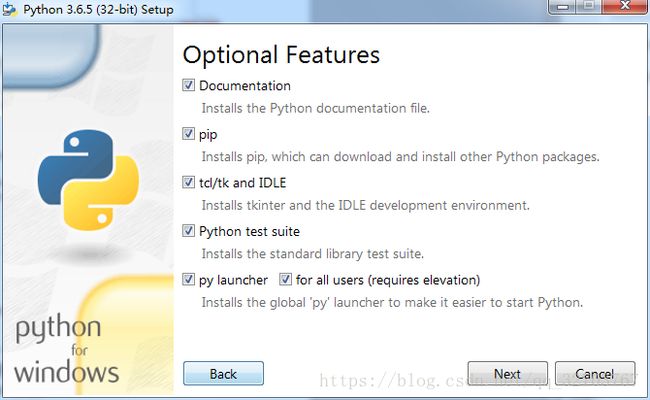
把添加到环境变量打钩,可以省去后面自己配置环境变量
如果想要自己选择安装路径,点击Customize installation安装
后面默认全选就行
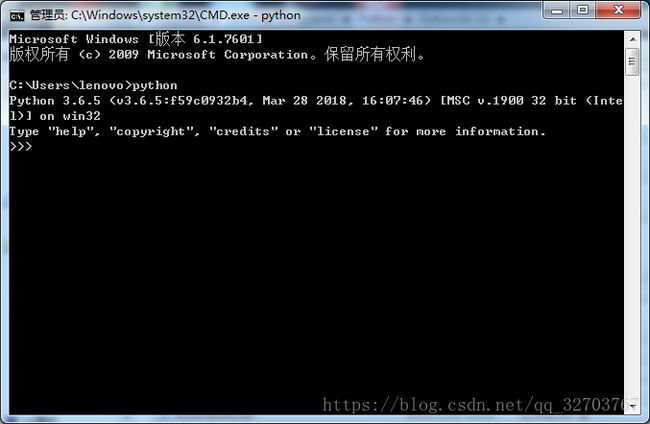
安装完成后,可以在命令提示符下输入 python 显示如下:
注意:32位安装后,命令提示符中Python可能遇到

下载一堆dll文件放到python.exe的根目录下就行了 下面是我打包好的地址
http://www.52wangjun.cn/dll.zip
下面我们安装一个对python比较友好的编译软件 –PyCharm
https://www.jetbrains.com/pycharm/download/#section=windows 点击右边的
软件安装完成后,还需要安装两个包requests 和 beautifulsoup4
先新建一个python工程
然后File – Settings

然后点击Project Interpreter
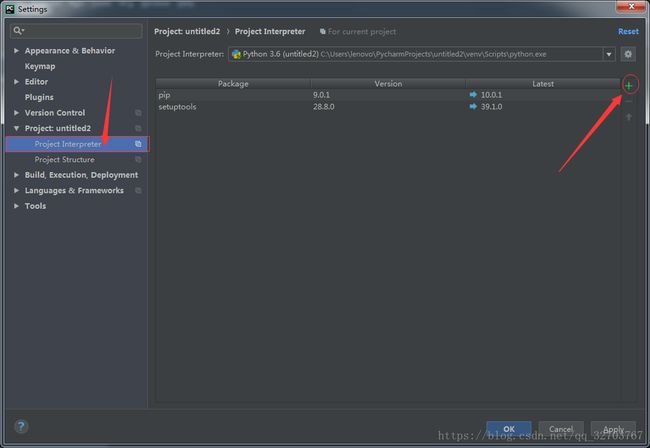
等加号加载出来后,点击加号 先搜索 requests 找到后点击 Install Package
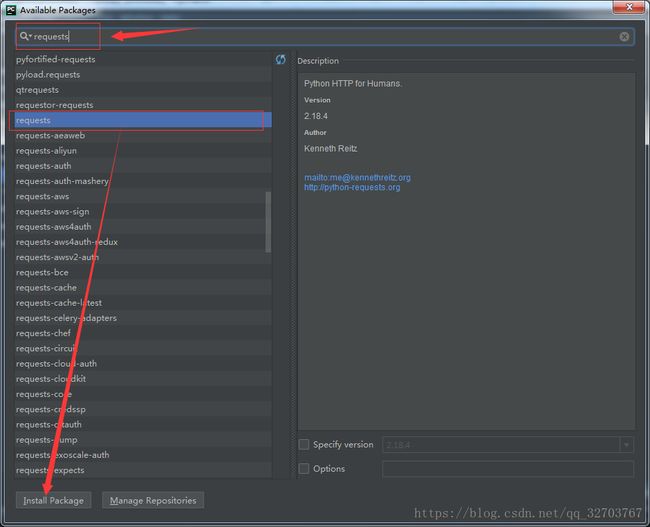
![]()
后面beautifulsoup4一样


当看到Project Interpreter 显示以上内容 我们的基本安装已经完成了
二、网页分析加代码实现
下面我们进入正题 首先 我们进入斗鱼的官网
我发现首页是一些推荐的主播,并不全面,不能全部爬取,所以我这里选择了分类页
分类页地址:https://www.douyu.com/directory
这里是斗鱼所以的直播分类,我们可以看到所有的分类全部都在这一页,所以我们只需要把每个分类的地址拿到。
在浏览器中按F12,我们看到
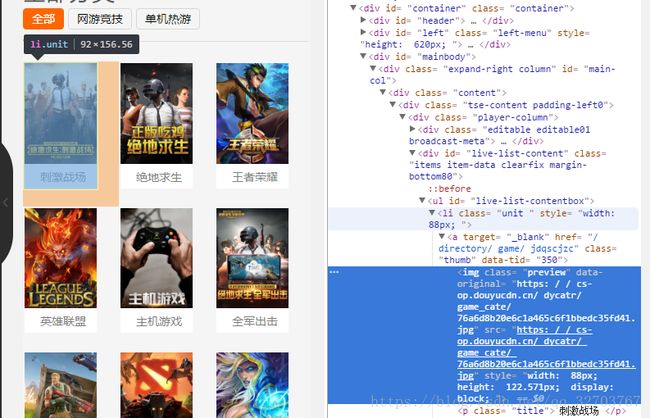

每个分类都是由
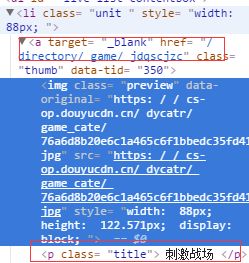
所有我们只需要
def main_wj():
r = requests.get("https://www.douyu.com/directory") #从分类目录读取所有分类的名字和链接地址
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser') #美丽汤,用于html更加简便
urls = []
names = []
for link in soup.select('.unit '): #分类链接和名字的 class 是unit
urls.append(link.select('a')[0]['href']) #添加链接到urls列表
names.append(link.select('a')[0].text.strip().replace(":", "")) #添加分类名到names列表,
# 且替换掉名字中的:,避免后面创建文件夹失败就能够把所有分类(分类名+分类地址)获取到了
下面我们随便进入一个分类中
https://www.douyu.com/directory/game/jdqscjzc 我们拉到最下面,发现是有分页的
如果是一般的分页都是 直接在链接中改 id ,但是我们点击第二页后发现,网页的地址没有改变,说明很可能是用JavaScript实现的分页功能,这怎么办呢,如果按照之前的方法只能获取到第一页。下面我们按F12,选中network-XHR,然后点击第二页。
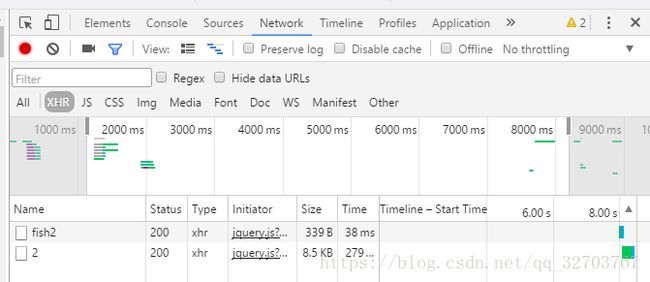
我们看到一个2的文件,点击进去
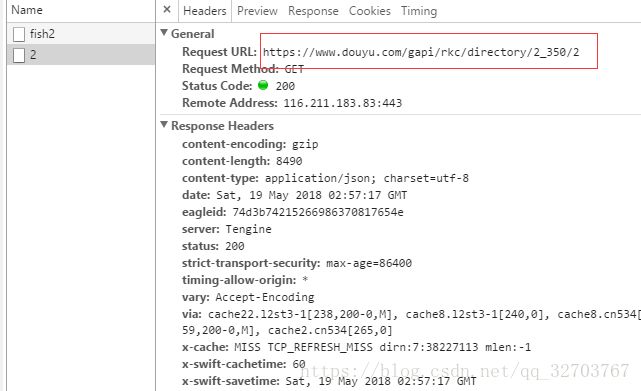
我们发现是这个api给刚刚分类页面提供的数据
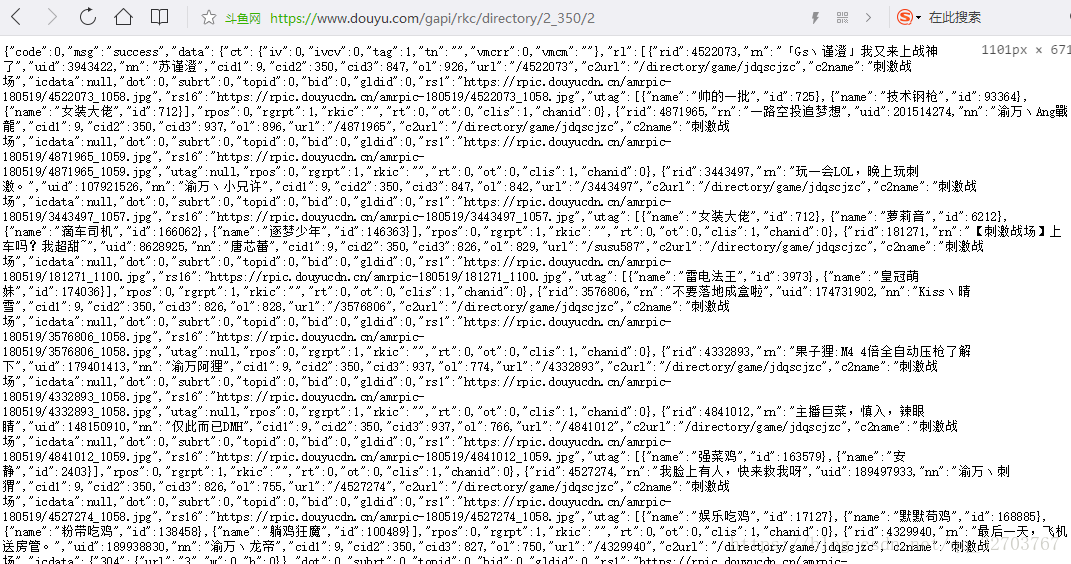
所有我们只需要从这个api,就能够获取所有的,信息了
https://www.douyu.com/gapi/rkc/directory/2_350/2
我们发现这个链接,就两个参数,2_350,2,很明显可能看出,后面的2是第2页,不信的可以,点击3验证一下,那么2_350就是表示分类了,那么还有一个问题需要确定,就是一共有多少页,现在我们回到第一页,看源码,有一个JavaScript标签
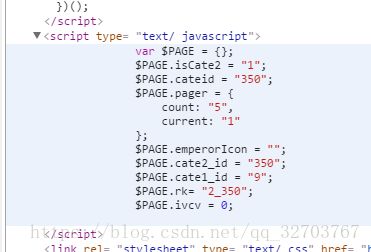
rk_=”2_350”,就是分类 count = “5”,是总页数,
所以后面我们只需要提取这两个参数就行
def write_info(a1,a2,name): # a1 分类接口编号 a2 分类页数 name 分类名
os.mkdir("F:\\yusheng\\"+name) #以分类名创建目录,F:盘的yusheng文件夹下
global num # 初始化全局变量 用于统计主播数量
num = 1
for x in range(int(a2[0])): # 循环写入每一页的信息
getUrl_wj("/gapi/rkc/directory/" + str(a1[0]) + "/" + str(x + 1), name)
print("当前完成分类:"+name)
下面是在每个api分类中提取数据就简单了,只需要用个正则表达式就行了
def getUrl_wj(url,name): #接口url ,分类名
res = requests.get("https://www.douyu.com"+url)
res.encoding = 'utf-8'
ze = '"rid":(.*?),"rn":".*?","uid":.*?,"nn":"(.*?)"' #rid = 房间号 nn = 主播名
s = re.findall(ze, res.text) #获得主播的房间号 和 名字
global num
f = open("F:\\\\yusheng\\\\"+name+"\\\\zhubo.txt","a") #以追加的模式打开文件txt文件
for x in s:
t = list(x)
try:
f.write(str(t[0])+"\t\t"+str(t[1])+"\t\t"+str(num)+"\n") #写入信息,防止编码异常的问题,这里try一下
num+=1
except UnicodeEncodeError:
continue
f.close() #关闭文件以上就是全部的过程了,仔细的朋友可能会发现一点不足,这只能获取在线的。第一次写博客,有不足之处,望见谅,也欢迎大家的批评指正,下面是完整代码:
from bs4 import BeautifulSoup #美丽汤 ,可以很好的读取html标签,本来想练练这个的,可是后来发现用到不到,情况特殊
import requests
import re
import os
def getUrl_wj(url,name): #接口url ,分类名
res = requests.get("https://www.douyu.com"+url)
res.encoding = 'utf-8'
ze = '"rid":(.*?),"rn":".*?","uid":.*?,"nn":"(.*?)"' #rid = 房间号 nn = 主播名
s = re.findall(ze, res.text) #获得主播的房间号 和 名字
global num
f = open("F:\\\\yusheng\\\\"+name+"\\\\zhubo.txt","a") #以追加的模式打开文件txt文件
for x in s:
t = list(x)
try:
f.write(str(t[0])+"\t\t"+str(t[1])+"\t\t"+str(num)+"\n") #写入信息,防止编码异常的问题,这里try一下
num+=1
except UnicodeEncodeError:
continue
f.close() #关闭文件
def getUrl(url):
res = requests.get("https://www.douyu.com" + url) #向指定某分类页发送请求
# 通过接收到的数据,是通过js动态实现多页数据显示的
# 后来通过查看js文件发现他调用了API的接口
# /gapi/rkc/directory/"(分类编号)/(分类页数)
# 所以后面只需要分析接口的数据就行
res.encoding='utf-8'
ze = 'PAGE.rk= "(.*?)";' #指定某个分类的接口编号
ze2 = 'count: "(.*?)",' #指定某个分类的页数
s = re.findall(ze,res.text) #通过正则表达式过滤出信息
s2 =re.findall(ze2,res.text)
return s,s2 #返回 分类接口编号 和 分类页数
def write_info(a1,a2,name): # a1 分类接口编号 a2 分类页数 name 分类名
os.mkdir("F:\\yusheng\\"+name) # 以分类名创建目录
global num # 初始化全局变量 用于统计主播数量
num = 1
for x in range(int(a2[0])): # 循环写入每一页的信息
getUrl_wj("/gapi/rkc/directory/" + str(a1[0]) + "/" + str(x + 1), name)
print("当前完成分类:"+name)
def main_wj():
r = requests.get("https://www.douyu.com/directory") #从分类目录读取所有分类的名字和链接地址
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html.parser') #美丽汤,用于html更加简便
urls = []
names = []
for link in soup.select('.unit '): #分类链接和名字的 class 是unit
urls.append(link.select('a')[0]['href']) #添加链接到urls列表
names.append(link.select('a')[0].text.strip().replace(":", "")) #添加分类名到names列表,
# 且替换掉名字中的:,避免后面创建文件夹失败
for url, name in zip(urls, names): #循环遍历列表 urls 和 names
a1, a2 = getUrl(url)
write_info(a1, a2, name)
num = 1
main_wj()