机器学习项目(四)疫情期间网民情绪识别 (二)
文本情感分类问题
- 机器学习方法 TFIDF+机器学习分类算法
- 深度学习方法 TextCNN TextRNN 预训练的模型
预训练的模型有哪些?
- bert
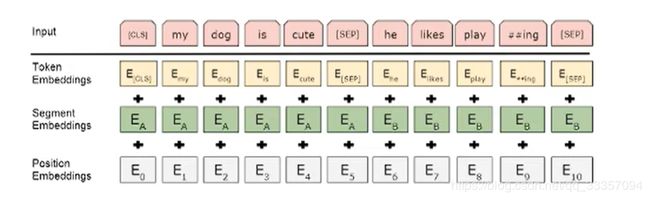
输入有三个序列 Token(字符的序列 把文本转化成字符的编码 进行输入)
Segment(段序列 用于区分是句子A 还是句子B (如果是A就设为0 B就设为1) 用于文本分类 可以全部设成0)
Position(位置向量 由于transformer不能很好的捕捉位置特征 引入位置向量 随初始化 构建embedding的过程) - albert
- xlnet
- robert
预训练的模型 需要很大的显存
Bert源码
- https://github.com/google-research/bert
- https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/modeling.py#L428
transformer包
- https://huggingface.co/transformers/v2.5.0/model_doc/bert.html
- tokenizer.encode_plus 参数详细见:https://github.com/huggingface/transformers/blob/72768b6b9c2083d9f2d075d80ef199a3eae881d8/src/transformers/tokenization_utils.py#L924 924行
import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedKFold
from tensorflow.python.keras.utils import to_categorical
from tqdm import tqdm
import tensorflow as tf
import tensorflow.keras.backend as K
import os
from transformers import *
print(tf.__version__)
# 文件读取
TRAIN_PATH = './data/train_dataset/'
TEST_PATH = './data/test_dataset/'
BERT_PATH = './bert_base_chinese/'
MAX_SEQUENCE_LENGTH = 140
input_categories = '微博中文内容'
output_categories = '情感倾向'
df_train = pd.read_csv(TRAIN_PATH+'nCoV_100k_train.labled.csv',engine ='python')
df_train = df_train[df_train[output_categories].isin(['-1','0','1'])]
df_test = pd.read_csv(TEST_PATH+'nCov_10k_test.csv',engine ='python')
df_sub = pd.read_csv(TEST_PATH+'submit_example.csv')
print('train shape =', df_train.shape)
print('test shape =', df_test.shape)
tokenizer = BertTokenizer.from_pretrained(BERT_PATH+'bert-base-chinese-vocab.txt')
tokenizer.encode_plus("深度之眼",
add_special_tokens=True,
max_length=20,
truncation_strategy= 'longest_first')
# {'input_ids': [101, 3918, 2428, 722, 4706, 102], #Token序列
# 'token_type_ids': [0, 0, 0, 0, 0, 0], #Segment序列
# 'attention_mask': [1, 1, 1, 1, 1, 1]} #Position序列 会在bert里面embedding
将微博的文本转化成三个序列进行输入
max_sequence_length 设置的固定的文本长度(取140)
def _convert_to_transformer_inputs(instance, tokenizer, max_sequence_length):
"""Converts tokenized input to ids, masks and segments for transformer (including bert)"""
"""默认返回input_ids,token_type_ids,attention_mask"""
# 使用tokenizer接口 将文本进行编码 生成一个字典 字典中包含三个元素
# instance 文本
inputs = tokenizer.encode_plus(instance,
add_special_tokens=True,
max_length=max_sequence_length,
truncation_strategy='longest_first')
# 将编码后的内容取出来
input_ids = inputs["input_ids"]
input_masks = inputs["attention_mask"]
input_segments = inputs["token_type_ids"]
padding_length = max_sequence_length - len(input_ids)
# 填充
padding_id = tokenizer.pad_token_id
input_ids = input_ids + ([padding_id] * padding_length)
input_masks = input_masks + ([0] * padding_length)
input_segments = input_segments + ([0] * padding_length)
return [input_ids, input_masks, input_segments]
# 将所有的文本进行保存
def compute_input_arrays(df, columns, tokenizer, max_sequence_length):
input_ids, input_masks, input_segments = [], [], []
for instance in tqdm(df[columns]):
ids, masks, segments = _convert_to_transformer_inputs(str(instance), tokenizer, max_sequence_length)
input_ids.append(ids)
input_masks.append(masks)
input_segments.append(segments)
return [np.asarray(input_ids, dtype=np.int32),
np.asarray(input_masks, dtype=np.int32),
np.asarray(input_segments, dtype=np.int32)
]
# 将训练集和测试集同时变成三个序列
inputs = compute_input_arrays(df_train, input_categories, tokenizer, MAX_SEQUENCE_LENGTH)
test_inputs = compute_input_arrays(df_test, input_categories, tokenizer, MAX_SEQUENCE_LENGTH)
# 标签类别转化
# 改为从0开始 变为 0 1 2 只需要加一
def compute_output_arrays(df, columns):
return np.asarray(df[columns].astype(int) + 1)
outputs = compute_output_arrays(df_train, output_categories)
BERT模型
构建BERT模型
def create_model():
# 三个序列作为输入
input_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
input_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
input_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
# 导入bert模型
# output_hidden_states transformer中的每一层都可以取出来
config = BertConfig.from_pretrained(BERT_PATH + 'bert-base-chinese-config.json', output_hidden_states=True)
bert_model = TFBertModel.from_pretrained(BERT_PATH + 'bert-base-chinese-tf_model.h5', config=config)
# bert模型会返回三个向量
# sequence_output 最后一层transformer的向量 (bs,140,768) batchsize 文本的长度 每一个Token的向量
# pooler_output 通过pooling之后的到的结果
# hidden_states 12层的transformer
sequence_output, pooler_output, hidden_states = bert_model(input_id, attention_mask=input_mask,
token_type_ids=input_atn)
# (bs,140,768)(bs,768)
x = tf.keras.layers.GlobalAveragePooling1D()(sequence_output)
x = tf.keras.layers.Dropout(0.15)(x)
x = tf.keras.layers.Dense(3, activation='softmax')(x)
# 模型的定义
model = tf.keras.models.Model(inputs=[input_id, input_mask, input_atn], outputs=x)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5)
# 定义loss 优化函数 和 metrics指标
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['acc', 'mae'])
return model
模型训练
CV交叉验证
gkf = StratifiedKFold(n_splits=5).split(X=df_train[input_categories].fillna('-1'), y=df_train[output_categories].fillna('-1'))
valid_preds = []
test_preds = []
# 简单的进行分裂
for fold, (train_idx, valid_idx) in enumerate(gkf):
train_inputs = [inputs[i][train_idx] for i in range(len(inputs))]
train_outputs = to_categorical(outputs[train_idx])
valid_inputs = [inputs[i][valid_idx] for i in range(len(inputs))]
valid_outputs = to_categorical(outputs[valid_idx])
K.clear_session()
model = create_model()
# 进行模型训练的部分
model.fit(train_inputs, train_outputs, validation_data= [valid_inputs, valid_outputs], epochs=2, batch_size=32)
# model.save_weights(f'bert-{fold}.h5')
valid_preds.append(model.predict(valid_inputs))
test_preds.append(model.predict(test_inputs))
df_test.head()
# 模型预测 1做平均 将概率相加取平均
sub = np.average(test_preds, axis=0)
sub = np.argmax(sub,axis=1)
# df_sub['y'] = sub-1
# #df_sub['id'] = df_sub['id'].apply(lambda x: str(x))
# df_sub.to_csv('test_sub.csv',index=False, encoding='utf-8')
# 要用测试集 微博id
df_sub = df_test[['微博id']]
df_sub.head()
# 将测试集写入
# 预测的时候 是将结果+1 实际写入的时候 要-1
df_sub['y'] = sub-1
df_sub.columns=['id','y']
df_sub.head()
df_sub.to_csv('test_sub.csv',index=False, encoding='utf-8')