《Cross-Modal Retrieval in the Cooking Context__Learning Semantic Text-Image Embeddings》
论文地址:
https://arxiv.org/pdf/1804.11146.pdfarxiv.org
来源:ACM SIGIR2018(暂未发布源码)
一、Introduction:
文章要做的事情(recipe retreival):
输入:image(sentence)+dataset 输出:sentence(image) rank list
在本文中,我们提出了一个跨模态检索模型,在共享表示空间中对齐视觉和文本数据(如菜肴图片和食谱)。我们描述了一个有效的学习方案,能够解决大规模问题,并在包含近100万个图片配方对的Recipe1M数据集上进行验证。
二、Contributions:
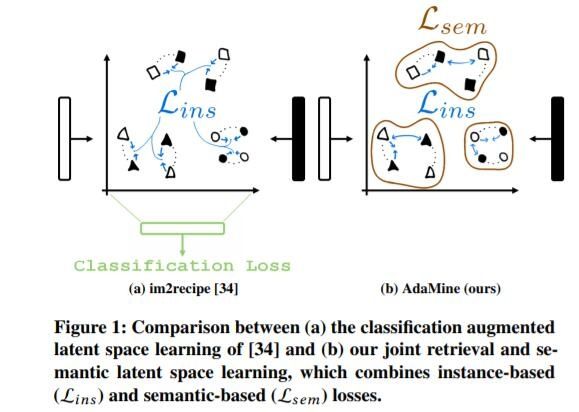
1.提出了一个跨模态检索及分类损失的联合目标函数来构建潜在空间。
![]()
2.提出了一个双重三元组来共同表达
1)检索损失(例:比萨的配方和相对应的图片的距离在潜在空间中比其他的图片更接近,见图1b中的蓝色箭头)
2)类别损失(例:在潜在空间中,两种披萨的距离,比起,比萨和任何来自其他类别的另一个物品,如沙拉更接近)。我们基于类别的损失直接作用于特征空间,而不是向模型添加分类层。
3.提出了一种新方法来调整随机梯度下降法中的梯度更新和用于训练模型的反向传播算法。
三、Model:
本文提出的模型AdaMine(ADAptive MINing Embeding)的目标是通过基于双三元组的联合检索和类别的学习框架来学习配方items(文本和图像)的表示。
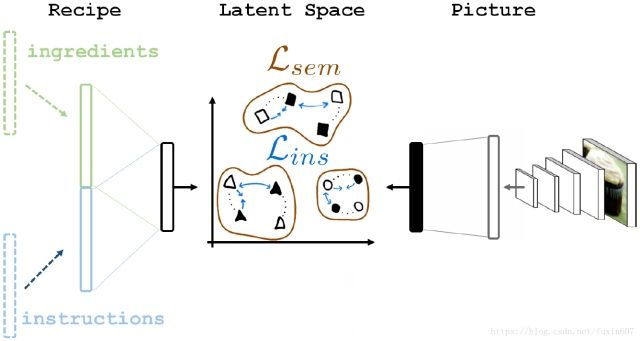
在模型中,将不同模态(图像或文本配方)的特征向量映射到潜在空间中。
1.
图像特征:ResNet-50模型,最后一层为完全连接层,输入为224*224*3的图像
输出为1*1*1000的特征向量,映射到潜在空间。
文本配方:首先,成分和说明分别嵌入,然后将其获得的特征作拼接,作为完全连接层的输入,再将食谱特征映射到潜在空间。(对于成分,我们对由word2vec算法获得的预训练嵌入向量使用双向LSTM。)
2.
我们提出了一种双三元组学习方案,它依赖于基于实例和基于语义的三元组
分别注明(x_{q},x_{p},x_{n}) 和 (x'_{q},x'_{p},x'_{n}) 。
我们通过最小化以下目标函数来学习项目嵌入:
![]()
θ是网络参数集,Lins是与基于实例的三元组 (x_{q},x_{p},x_{n}) 上的检索任务的损失,而Lsem是基于语义的三元组 (x'_{q},x'_{p},x'_{n}) 中的语义信息所带来的损失。
Retrieval loss:

d(x,y) 表示为向量x,y的余弦距离, \iota_{ins} 是所有三元组中个体损失的总和
Semantic loss:

3.
Adaptive Learning Schema
自适应策略更新 \delta_{adm}

四、实验结果
1.
Dataset:Recipe 1M 数据集
2.
Baselines:CCA、PWC、PWC*、PWC++
3.
Adam optimizer
lr= 10^{-4}
\alpha=\lambda=0.3

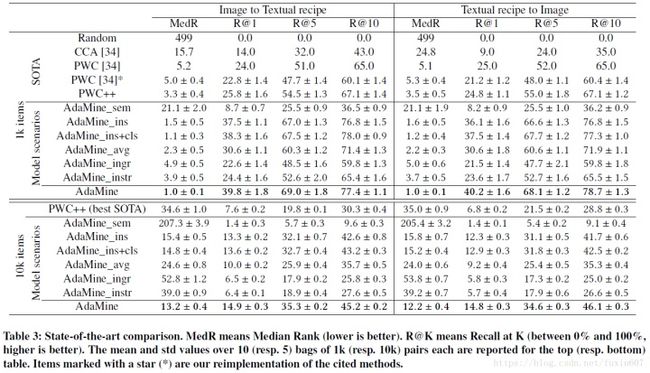
与state-of-the-art比较的实验结果如下所示:
五、总结
-
image、ingredients和instructions concatenation。
-
image与ingredients。
-
在训练的过程中采用adaptive strategy,主要思想就是对统计两个triplet loss中不为0的值得个数,然后分别用这个triplet loss除以统计的个数(对triplet loss取平均),实验结果表明这种方法效果比较好。
-
future work:考虑目标语义中的多层级来扩展我们的模型,以更好地改进潜在空间的结构。