9102年入门GAN的补习
“ 本文主要介绍了近年来GAN(生成对抗网络)在分布差异度量,IPM与正则化,对偶学习,条件与控制,提高分辨率,评价指标等问题上的发展情况和代表性工作,希望对之前没有跟进 GAN 相关工作的同学有所帮助~”
作者:纵横
来源:知乎专栏 机器不学习
编辑:happyGirl
最近,笔者在导师的指导下,进行了一些 GAN + GCN/video 的研究。不得不说,GAN 已经火了这么长时间,在图卷积和视频分析等交叉领域、应用领域中仍然有着很强的生命力。在1+1=2的时候需要解决的问题也不少。笔者在研究过程中首先尝试了一些基础模型,并选取了其中具有代表性的进行了记录。后续有时间会继续记录 GAN + GCN / GAN + video 和自己正在实现的 pytorch gan zoo。
9102年,万物皆可 embedding 的目标已经基本实现,表示学习受到广泛重视,生成学习如火如荼。笔者在最近的研究中,发现交叉领域1+1=2的粘合工作已经所剩无几了。但是,1+1=2之后仍面临着一些任务特点相关的小问题,为了解决笔者所在领域的小问题,笔者总结并复现了经典的 GAN 网络,希望对之前没有跟进 GAN 相关工作的同学有所帮助~
导视
很多现有的机器学习任务可以归结为 domain transform,将数据从源域转换到目标域,例如根据文字生成图像、根据前一帧生成后一帧、将一种风格转换为另一种风格等等。现有的神经网络 module已经能够帮助我们将源数据映射为任意目标 size,而 MSE、MAE、Huber Loss 等传统 损失函数,也能够度量生成样本与目标域样本之间的差异。
但是,用这种方式构建的模型(例如 Auto Encoder)在 BP 后,往往 不那么令人满意 。
在研究过程中,一些工作发现,这些 传统的损失函数 在指导 NN 更新的过程中 只能粗略地 根据所有像素的 平均误差计算梯度,导致了很多边缘分布、 局部的差异 没有被学到。
 图一:MSE 的局限性
图一:MSE 的局限性
如上图所示,两张生成图像在原图的基础上修改的像素数目相同,因此其 MSE 误差相同。然而根据常识,第二张图像明显不符合 0 的模式。一个好的损失函数,应当赋予第二张生成图像更大的 MSE。
在此基础上,GAN 网络提出了一种 可学习的损失函数 ,即判别器(Discriminator), 自适应地 度量两个 总体分布之间的差异,即连续的概率分布。(不同于 MSE、MAE、Huber Loss 等 固定的 损失函数,度量两个 样本之间的差异,即离散的概率分布)。
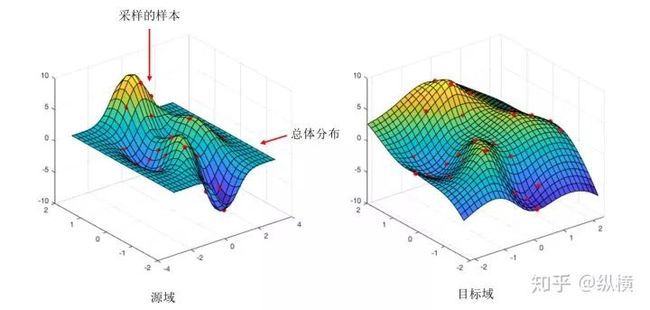 图二:不同于度量样本之间的差异,GAN 度量的是两个总体分布的差异
图二:不同于度量样本之间的差异,GAN 度量的是两个总体分布的差异
在推导过程中,大多工作根据“ 贝叶斯统计 ”的理论,最大化生成域和目标域的似然。
个人认为,一个真正有生命力的研究方向不一定有好的 performance,但至少 应该能够拆分成不同的子问题,分别开花结果。如果大家都在一个问题上,堆叠、魔改 module,那这个研究方向恐怕只能昙花一现。GAN 作为一个在 2019 年仍然蓬勃发展的 topic,其优化方向在 CV 中可以分为以下 6 类:
一、分布差异的度量
改进度量生成分布和目标分布差异,提高生成效果的精度和多样性
二、IPM与正则化
截断梯度、为梯度添加正则,提高 GAN 收敛的稳定性
三、对偶学习
利用循环一致性,添加源域与重构域的约束,充分利用数据
四、条件与控制
融合已知条件,控制生成过程和生成结果的特征
五、提高分辨率的努力
传统的 GAN 网络在生成大图时较为模糊,一些工作在提高生成图像的分辨率上进行了研究
六、评价指标
不同 GAN 生成效果的度量
一、分布差异的度量
在上文中,我们提到 GAN 的本质目标是使生成分布和目标分布尽可能相近。但是,应该如何衡量两者概率分布之间的差异呢?
GAN
 图三:GAN 由生成器和判别器构成
图三:GAN 由生成器和判别器构成
Goodfellow 首次提出了极小极大博弈(minimax game),开启了 GAN 的篇章。GAN 需要同时训练两个模型,即一个能捕获数据分布的生成模型 ,和一个能估计数据是否为真实样本的判别模型 。生成器的训练目标是最大化判别器犯错误的概率,即通过优化生成分布,让判别器误以为生成的假样本为真。而判别器的训练目标是最小化自己犯错误的概率,即找出生成器生成的假样本,loss 可以表达为:
在实现过程中,GAN 的判别器和生成器往往是交替优化(或5:1)的,可以分别写出判别器和生成器的优化目标:
论文:arxiv (https://arxiv.org/abs/1406.2661)
代码:github (https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/gan/gan.py)
LSGAN
LSGAN 将生成样本和真是样本分别编码为 , ,并使用平方误差代替了 GAN 的逻辑损失 :
试验表明,LSGAN 能够部分解决 GAN 训练不稳定和生成图像质量差的问题。但是,平方误差对离群点的过度惩罚,可能会导致过度模仿真实样本,降低生成结果的多样性。
论文:arxiv
代码:[ github ](https://link.zhihu.com/?target=https%3A//github.com/LynnHo/DCGAN-LSGAN- WGAN-GP-DRAGAN-Pytorch/blob/master/v0/train_celeba_lsgan.py)
f-GAN
f-GAN 进一步扩展了 GAN 的损失函数 ,认为 GAN 所使用的 JS 散度和 LSGAN 所使用的卡方散度都属于散度的特例,还可以使用其他不同的距离或散度来衡量真实分布与生成分布 。在此基础上,f-GAN 设计一组根据不同散度计算得到的损失:
其中, 可以根据不同散度,替换为多种表达形式;由于 对判别器的值域有要求,判别器输出层的激活函数也需要替换:
 图四:f-GAN的多种形式
图四:f-GAN的多种形式
论文:arxiv (https://arxiv.org/abs/1606.00709)
代码:github(https://github.com/shayneobrien/generative-models/blob/master/src/f_gan.py)
EBGAN
f-GAN 在散度视角集大成,EBGAN 则 将判别器视为一个能量函数,作为一个可训练的损失函数。该能量函数将靠近真实分布的区域视为低能量区域,远离真是分布的视为高能量区域。生成器会尽可能生成最小能量的伪造样本。在这种视角下,生成器的网络结构和损失函数更加灵活多变,EBGAN 提出 使用自动编码器结构,用重构误差代替分类器的分类结果 :
 图五:EBGAN 的判别器采用自动编码器结构
图五:EBGAN 的判别器采用自动编码器结构
即, 。在设计损失函数时,为了使能量模型更加稳定,作者 添加了一个边际值 :
论文:arxiv(https://arxiv.org/abs/1609.03126)
代码:github(https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/ebgan/ebgan.py)
二、IPM与正则化
很多时候,由于对抗学习,GAN 的收敛并不理想。IPM (积分概率度量) 将鉴别器的输出从概率转变为实数,并通过正则化将梯度限定在一定区间内,有效防止了判别器过早优化,导致生成器梯度消失的问题。
WGAN
WGAN 在分析 GAN 收敛不稳定的原因后认为,判别器训练的梯度很难把控是导致 GAN 收敛不稳定的罪魁祸首。判别器训练得太好,生成器的梯度消失,loss 难以下降;判别器训练的不好,生成器的梯度不准确,loss 四处乱跑。只有在零和游戏中把握判别器和生成器的平衡才行。
WGAN 作出了如下修改:
判别器的最后一层取消 sigmoid
2. 对判别器使用梯度裁剪,将梯度 取值限制在 区间内。
3. 使用 RMSProp 或 SGD 并以较低的学习率进行优化
损失函数可以表示成:
的作用是将 的剧烈变化限制的更平缓一点,可以表示为:
在实现上就是将梯度 取值限制在 区间内。
论文:arxiv(https://arxiv.org/abs/1701.07875) 代码:github(https://github.com/Zeleni9/pytorch-wgan/blob/master/models/wgan_clipping.py)
WGAN-GP
WGAN 提出不久后,WGAN 的作者又对 WGAN 进行了优化,将梯度裁剪(weight clipping)替换为梯度惩罚(gradient penalty),提出带有梯度惩罚的 WGAN-gp。
论文:arxiv(https://arxiv.org/abs/1704.00028)
代码:github(https://github.com/caogang/wgan-gp/blob/master/gan_cifar10.py)
BEGAN
BEGAN 进一步结合了 WGAN 和 EBGAN 的思路。一方面,BEGAN 使用自动编码器和重构误差度量生成样本与真实样本的差异:
图六:BEGAN 的判别器也采用自动编码器结构
另一方面,BEGAN 训练了一个超参数,用于平衡判别器和生成器的优化速度:
论文:arxiv(https://arxiv.org/abs/1703.10717) 代码:github(https://github.com/shayneobrien/generative-models/blob/master/src/be_gan.py)
三、对偶学习
一些工作通过对偶学习,将 GAN 的生成-识别过程,扩展为生成-识别和重建-识别的过程,更充分地利用了源域和目标域的信息。DaulGAN、CycleGAN 和 DiscoGAN 的网络结构大同小异,但是 motivation 的差异很有趣:
DaulGAN
DaulGAN 提出将源分布转换为目标分布,与将目标分布转换回源分布,是一个对偶问题,可以协同优化。
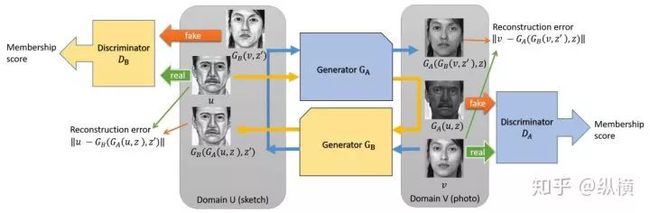 图七:DaulGAN 的网络结构
图七:DaulGAN 的网络结构
CycleGAN
CycleGAN 提出了循环一致性(Cycle-Consistent)原则,其基本思想是图像经过映射变为另一类图像后,应该能通过逆映射变换回原来的图像。
 图八:CycleGAN 的网络结构
图八:CycleGAN 的网络结构
论文:arxiv(https://arxiv.org/abs/1703.10593)
代码:github(https://github.com/aitorzip/PyTorch-CycleGAN/blob/master/models.py)
DiscoGAN
为了学习不同域之间的映射,DiscoGAN 首先想到了添加了第二个生成器,和重构损失项来比较真实图像和重构图像。
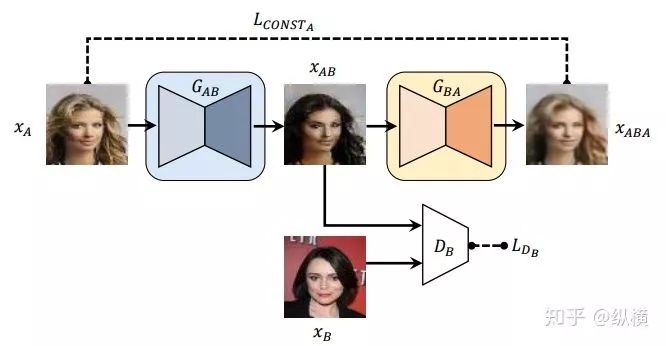 图九:DiscoGAN 的单映射网络
图九:DiscoGAN 的单映射网络
然而,这样设计出的模型是单方向映射的,无法同时学习如何从目标域映射回源域。此外,由于 MSE 对离群点的过度惩罚也会使模型存在模式崩塌问题,只会在源图上做微小的修改。因此,作者进一步提出了双向映射的 DiscoGAN:
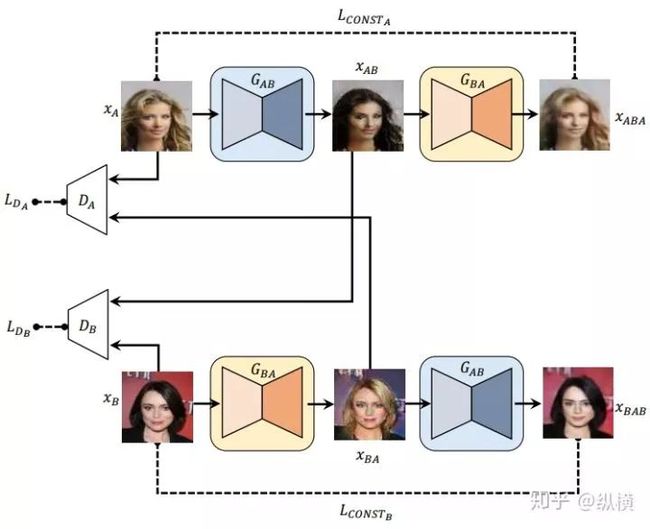 图十:DiscoGAN 的双映射网络
图十:DiscoGAN 的双映射网络
论文:arxiv(https://arxiv.org/abs/1703.05192) 代码:github(https://github.com/carpedm20/DiscoGAN-pytorch/blob/master/models.py)
四、条件与控制
GAN 的生成样本不可控,ConditionalGAN 通过添加先验/条件,指导生成样本的过程,从而控制生成的样本满足某些特征。
cGAN
通过 GAN 可以生成与目标分布相近的分布,例如生成 0 到 9 的数字等。但是,我们无法干预传统 GAN 生成分布的过程,譬如指定生成数字 1 等。因此,cGAN 将 GAN 中的概率分布改成了条件概率:
具体而言,就是在生成器和鉴别器的输入中,都拼接已知的条件向量:
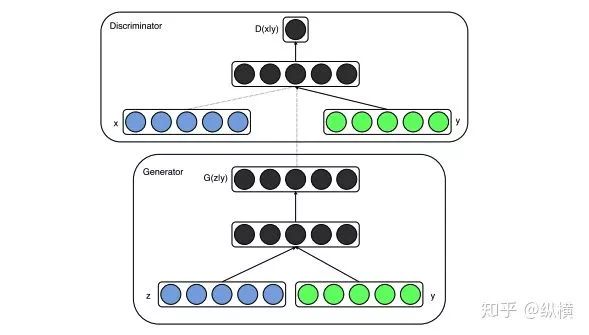 图十一:cGAN 的网络结构
图十一:cGAN 的网络结构
图中, 代表从正态分布中采样的噪声; 代表真实分布中采样的样本, 代表条件向量,例如样本标签的 one hot 编码。在判别器判别生成样本时,会根据条件判别,从而迫使生成器参考条件向量生成样本。
论文:arxiv(https://arxiv.org/abs/1411.1784)
代码:github(https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/cgan/cgan.py)
IcGAN
最初,cGAN 只将样本标签的 one hot 编码作为输入,在标签级控制生成样本。如何更细力度的更改生成样本的某些特征呢?IcGAN 通过编码器学习了原图到其特征向量的映射,今儿通过修改特征向量的部分特征作为生成器的输入生成希望生成的特征:
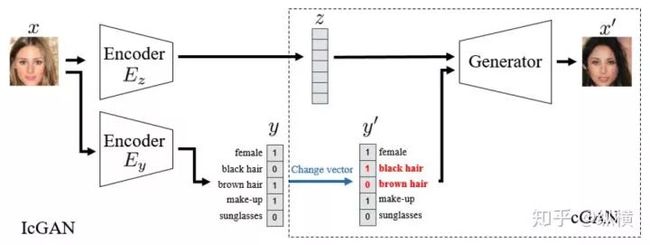 图十二:IcGAN 的网络结构
图十二:IcGAN 的网络结构
ACGAN
ACGAN 没有选择将条件(样本的类别)直接输入判别器,而是训练判别器对样本进行分类,即判别器不仅需要判断每个样本的真假,还需要预测已知条件(样本的类别,添加一个分类的损失)。
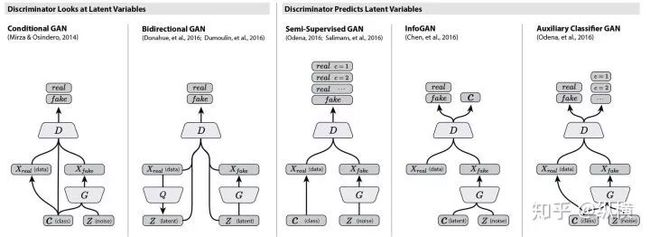 图十三:ACGAN 的网络结构
图十三:ACGAN 的网络结构
ACGAN 的一个好处是,判别器输出条件的设计使我们可以采用在其他数据集上预训练的模型进行前一学习,从而生成更清晰的图像减轻模式崩塌的问题。此外,如上图所示,还有其他类似的设计为 GAN 添加先验分布,例如 SemiGAN 和 InfoGAN 等,但大同小异。
论文:arxiv(https://arxiv.org/abs/1610.09585) 代码:github(https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/acgan/acgan.py)
五、提高分辨率的努力
在最初的工作中,受到正态分布采样的 noise 尺寸的限制,GAN 还只能生成 32x32 的低分辨率的图像。一些工作针对如何生成高分辨率图像进行了研究。
DCGAN
DCGAN 首次将 CNN 引入 GAN(此前 GAN 大多由全连接层构成),并提出了一个能够稳定收敛的 CNN + GAN 结构。很多 trick 为后面的研究提供了基础:
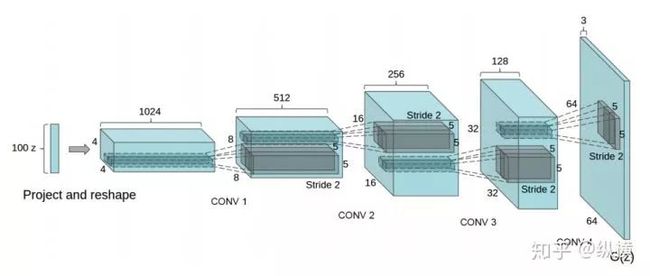 图十四:DCGAN 的生成器
图十四:DCGAN 的生成器
下采样使用带有步长的卷积,而不是池化
2. 上采样使用反卷积,而不是插值
3. 判别器的激活函数使用 Leaky ReLU
4. 使用 BatchNorm 层(注:在 WGAN 不适用)
5. 生成器与判别器对偶等等
论文:arxiv(https://arxiv.org/abs/1511.06434) 代码:github(https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/dcgan/dcgan.py)
SAGAN
随着研究的深入,一些 CV 中常用的与 CNN 结合的 module 逐渐被引入。SAGCN 提出在生成器和判别器中引入 Self Attention 模块,获取距离较远的相关区域的信息,提升了生成图像的清晰度。
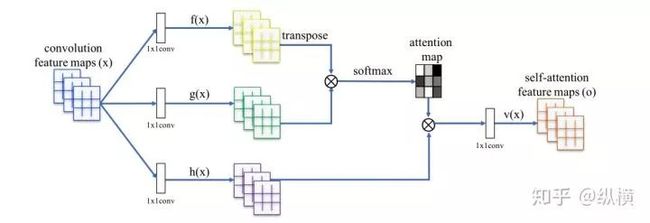 图十五:Self Attention 结构
图十五:Self Attention 结构
在原文实现中,Self Attention 只需要加在生成器和判别器的最后两层。
论文:arxiv(https://arxiv.org/abs/1805.08318) 代码:github(https://github.com/heykeetae/Self-Attention-GAN/blob/master/sagan_models.py)
BigGAN
随着可用的 module 逐渐增加,网络参数量的军备竞赛也逐渐展开。BigGAN 作为 GAN 发展史上的里程碑,在精度上(128x128 分辨率)实现了跨越式的提升。虽然其模型规模较大,很难在本地复现,但是BigGAN 使用的 Self Attention、Res Block、大 channel/batch、梯度阶段技巧等为后续的研究提供了借鉴。
 图十六:BigGAN 结构
图十六:BigGAN 结构
论文:arxiv(https://arxiv.org/abs/1809.11096) 代码:github(https://github.com/ajbrock/BigGAN-PyTorch/blob/master/BigGANdeep.py)
LAPGAN
LAPGAN 结合 CGAN 将迭代和层次化的思想运用到了图像生成中。LAPGAN 认为与其一下子生成大分辨率的图像,先生成低分辨率的图像。在向上采样,提高分辨率的过程中,让生成器每次生成缺少的细节信息,即“残差”图片,与上采样后的图片做加法,得到更高分辨率的图像:
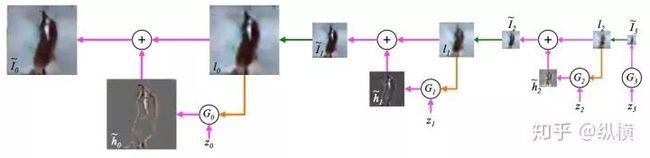 图十七:LAPGAN 的推理过程
图十七:LAPGAN 的推理过程
在训练过程中,LAPGAN 在每个分辨率下,以下采样后的图像为先验条件,学习下采样再上采样后与原图的信息损失,即残差的生成:
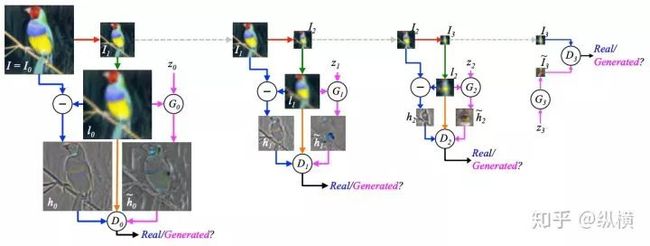 图十七:LAPGAN 的训练过程
图十七:LAPGAN 的训练过程
论文:arxiv(https://arxiv.org/abs/1506.05751)
代码:github (https://github.com/AaronYALai/Generative_Adversarial_Networks_PyTorch/blob/master/LAPGAN/LAPGAN.py)
六、评价指标
生成器的 loss 可以衡量生成的图片能骗过判别起的性能,但是无法度量生成图像的准确性和多样性。因此,除了主观性的评估外,近年的工作中也出现了 IS、FIP 等客观评价指标(类似 PSNR 评估图像质量)对生成图像的准确性和多样性进行评估(有些同学问这些评估指标能否作为 loss:这些指标只反映了生成数据的某些统计特征,做 loss 是无法指导 GAN 优化的)。
IS
Inception Score 作为早期的评价指标,提出 GAN 生成的结果可以由两个维度来衡量:即生成结果的准确性(可分性)和多样性:以生成图片为例,对于一张清晰的图片,它属于某一类的概率应该非常大,而属于其它类的概率应该较小(可以准确的被 Inception v3 分类)。同时,如果 GAN 能生成足够多样的图片,那么它生成的图片在各个类别中应当是均匀分布的(而不是只有某几种,即模式崩塌)。
值得注意的是,IS 越大,GAN 的效果越好。
代码:github(https://github.com/sbarratt/inception-score-pytorch/blob/master/inception_score.py)
FID
然而,IS 存在一个问题,真实图像并没有参与到生成图像的评估过程中。因此,FID 提出将生成图像与真实图像的进行的比较(在 Inception v3 的 feature map 层面),实现对生成图像准确性和多样性的评估。
值得注意的是,FID越小,GAN 的效果越好。
代码:github(https://github.com/mseitzer/pytorch-fid/blob/master/fid_score.py)
其他
FID 和 IS 都是基于特征提取的评估方法,feature map 有效地描述了某些特征是否出现,但是无法描述这些特征的空间关系。因而,近年来 GAN dissertation, on GAN and GMM 等文章对 GAN 的生成效果进行了进一步的分析。
一个比较有趣的结论是,目前大多数 GAN 的模型相较于原始的 GAN 模型并没有本质上的提升,只是收敛速度更快、收敛更稳定了。因此,在解决交叉领域的问题时,笔者一般先用常规的 WGAN-GP 进行测试,得到一个大致的 baseline,再决定是否继续深入研究下去,或者探究有哪些 task special 的问题。
尾注
看到一段很好的话,指导我们的科研工作(逃)与大家共勉~
层级结构并不意味着学科 X “仅仅是Y的应用”。每个新的层级都需要全新的定律、概念和归纳,并且和其前一个层级一样,研究过程需要大量的灵感和创意。心理学不是应用生物学,生物学也不是应用化学。
推荐原创干货阅读:
聊聊近状, 唠十块钱的
【Deep Learning】详细解读LSTM与GRU单元的各个公式和区别
【手把手AI项目】一、安装win10+linux-Ubuntu16.04的双系统(全网最详细)
【Deep Learning】为什么卷积神经网络中的“卷积”不是卷积运算?
【TOOLS】Pandas如何进行内存优化和数据加速读取(附代码详解)
【TOOLS】python3利用SMTP进行邮件Email自主发送
【手把手AI项目】七、MobileNetSSD通过Ncnn前向推理框架在PC端的使用
【时空序列预测第一篇】什么是时空序列问题?这类问题主要应用了哪些模型?主要应用在哪些领域?
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

个人微信
备注:昵称+学校/公司+方向
拉你进 AI蜗牛车粉丝群

点个在看,么么哒!
