RDD学习总结
1、引入Spark
Spark 2.3.2 使用 Scala 2.11.x 写应用程序,你需要使用一个兼容的 Scala 版本。
写 Spark 应用程序时,你需要添加 Spark 的 Maven 依赖,Spark 可以通过 Maven 中心仓库来获得:
groupId = org.apache.spark
artifactId = spark-core_2.10
version = 1.2.0
另外,如果你希望访问 HDFS 集群,你需要根据你的 HDFS 版本添加 hadoop-client 的依赖。
groupId = org.apache.hadoop
artifactId = hadoop-client
version =
最后,你需要导入一些 Spark 的类和隐式转换到你的程序,添加下面的行就可以了:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf2、初始化Spark
java初始化Spark:
package com.zhangbb;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class App {
public static void main(String[] args){
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("java Spark Demo");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
sc.close();
}
Scala初始化Spark:
package com.zhangbb
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object Application {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Scala Spark Demo").setMaster("local[*]")
val sc = new SparkContext(conf)
}
}
3、本地运行Spark程序需要的环境(本地运行Spark依赖于Hadoop环境,注意Spark的版本一定与Scala版本对应,如Spark-2.3.2与Scala-2.11.x对应)
- 下载Hadoop,并解压到你的本地目录,我下载的是hadoop-2.5.2版本,解压在D:\hadoop\hadoop-2.5.2。
- 计算机 –>属性 –>高级系统设置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME。注意:路径到bin的上级目录即可。
- Path环境变量下配置【%HADOOP_HOME%\bin;】
- 将下载到的hadooponwindows-master.zip,解压,将全部bin目录文件替换至hadoop目录下的bin目录。下载地址:https://pan.baidu.com/s/1eGra7gKCDbvNubO8UO5rgw密码:yk9u(本人QQ:1280072240)
4、算子的介绍
Value类型 Transformation 算子分类

相关代码:
//map算子:生成一个新的RDD,新的RDD中每个元素均有父RDD通 过作用func函数映射变换而来。新的RDD叫做MappedRDD
val mapRDD = sc.parallelize(List(1,2,3,4,5),2)
val map1 = mapRDD.map(_*2).collect()
println(map1.mkString(","))
JavaRDD map = sc.parallelize(Arrays.asList(1,2,3,4,5));
JavaRDD map1 = map.map(new Function() {
@Override
public Integer call(Integer integer) throws Exception {
return integer*2;
}
});
System.out.println(map1.collect().toString());
//mapPartitions 获取到每个分区的迭代器。对每个分区中每个元素进行操作
val rd1 = sc.parallelize(List("20180101", "20180102", "20180103", "20180104", "20180105", "20180106"), 2)
val rd2 = rd1.mapPartitions(iter => {
val dateFormat = new java.text.SimpleDateFormat("yyyyMMdd")
iter.map(date => dateFormat.parse(date))
})
println(rd2.collect().foreach(println(_)))
JavaRDD rd1 = sc.parallelize(Arrays.asList("20180101", "20180102", "20180103", "20180104", "20180105", "20180106"),2);
JavaRDD> rd2 = rd1.mapPartitions(new FlatMapFunction, Tuple2>() {
@Override
public Iterator> call(Iterator stringIterator) throws Exception {
List> list = new ArrayList<>();
while (stringIterator.hasNext()){
String item = stringIterator.next();
DateFormat dateFormat = new SimpleDateFormat("yyyyMMdd");
list.add(new Tuple2(item,dateFormat.parse(item)));
}
return list.iterator();
}
});
// rd2.foreach(new VoidFunction>() {
// @Override
// public void call(Tuple2 stringDateTuple2) throws Exception {
// System.out.println(stringDateTuple2._2());
// }
// });
rd2.foreach(x -> System.out.println(x));
//flatMap 将RDD中的每个元素通过func转换为新的元素,进行扁平化:合并所有的集合为一个新集合,新的RDD叫做FlatMappedRDD
val rd1 = sc.parallelize(Seq("I have a pen", "I have an apple", "I have a pen", "I have a pineapple"), 2)
val rd2 = rd1.map(_.split(" "))
println("map ==== " + rd2.collect().mkString(","))
val rd3 = rd1.flatMap(_.split(" "))
println("flatMap ==== " + rd3.collect().mkString(","))
JavaRDD rd1 = sc.parallelize(Arrays.asList("I have a pen", "I have an apple", "I have a pen", "I have a pineapple"));
JavaRDD rd2 = rd1.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
rd2.collect().forEach(x -> System.out.println(x));
val rdd1 = sc.parallelize(Seq("Apple", "Banana", "Orange"))
val rdd2 = sc.parallelize(Seq("Banana", "Pineapple"))
val rdd3 = sc.parallelize(Seq("Durian"))
//union 合并两个RDD,元素数据类型需要相同,并不进行去重操作
val unionRDD = rdd1.union(rdd2).union(rdd3)
//distinc 对RDD中的元素进行去重操作
val unionRDD2 = unionRDD.distinct()
//filter 对RDD元素的数据进行过滤 • 当满足f返回值为true时保留元素,否则丢弃
val filterRDD = rdd1.filter(_.contains("ana"))
//intersection 对两个RDD元素取交集
val intersectionRDD = rdd1.intersection(rdd2)
println("===union===")
println(unionRDD.collect().mkString(","))
println("===distinc===")
println(unionRDD2.collect().mkString(","))
println("===filter===")
println(filterRDD.collect().mkString(","))
println("===intersection===")
println(intersectionRDD.collect().mkString(","))
JavaRDD rdd1 = sc.parallelize(Arrays.asList("Apple", "Banana", "Orange"));
JavaRDD rdd2 = sc.parallelize(Arrays.asList("Banana", "Pineapple"));
JavaRDD rdd3 = sc.parallelize(Arrays.asList("Durian"));
JavaRDD unionRDD = rdd1.union(rdd2).union(rdd3);
JavaRDD unionRDD2 = unionRDD.distinct();
JavaRDD filterRdd = rdd1.filter(new Function() {
@Override
public Boolean call(String s) throws Exception {
return s.contains("ana");
}
});
JavaRDD intersectionRDD = rdd1.intersection(rdd2);
unionRDD.collect().forEach(x -> System.out.println(x));
unionRDD2.collect().forEach(x -> System.out.println(x));
filterRdd.collect().forEach(x -> System.out.println(x));
intersectionRDD.collect().forEach(x -> System.out.println(x));
Key-Value类型 Transformation 算子分类
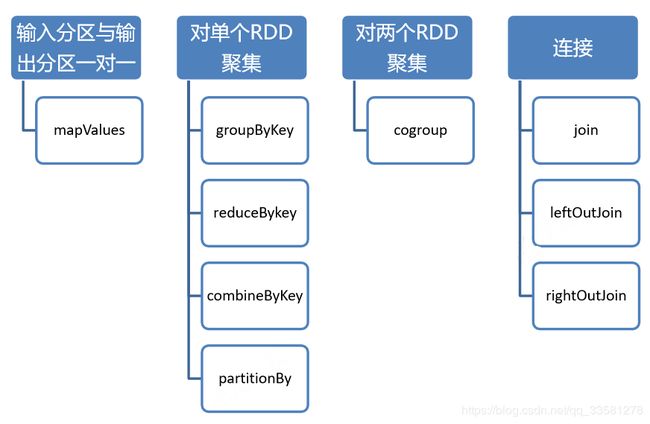
相关代码:
//groupByKey reduceByKey 对RDD[Key, Value]按照相同的key进行分组
val scoreDetail = sc.parallelize(List(("xiaoming","A"), ("xiaodong","B"), ("peter","B"), ("liuhua","C"), ("xiaofeng","A")), 3)
val scoreDetail2 = sc.parallelize(List("A", "B", "B", "D", "B", "D", "E", "A", "E"), 3)
val sorrceGroup = scoreDetail.map(x => (x._2,x._1)).groupByKey().collect()
val sorrceGroup2 = scoreDetail2.map(x => (x,1)).groupByKey().collect()
val sorrceReduce = scoreDetail.map(x => (x._2,x._1)).reduceByKey(_+_).collect()
val sorrceReduce2 = scoreDetail2.map(x => (x,1)).reduceByKey(_+_).collect()
println("===groupByKey===")
println(sorrceGroup.mkString(","))
println("===groupByKey===")
println(sorrceGroup2.mkString(","))
println("===reduceByKey===")
println(sorrceReduce.mkString(","))
println("===reduceByKey===")
JavaRDD scoreDetail = sc.parallelize(Arrays.asList("A", "B", "B", "D", "B", "D", "E", "A", "E"),3);
JavaPairRDD socerGroup = scoreDetail.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String s) throws Exception {
Tuple2 tuple2 = new Tuple2(s,1);
return tuple2;
}
});
JavaPairRDD> socerGroupres = socerGroup.groupByKey();
System.out.println(socerGroupres.collect().toString());
JavaPairRDD socerReduce = scoreDetail.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String s) throws Exception {
Tuple2 tuple2 = new Tuple2(s,1);
return tuple2;
}
});
JavaPairRDD socerReduceRes = socerReduce.reduceByKey(new Function2() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
});
System.out.println(socerReduceRes.collect().toString());
List> list = new ArrayList<>();
list.add(new Tuple2<>("xiaoming","A"));
list.add(new Tuple2<>("xiaodong","B"));
list.add(new Tuple2<>("peter","B"));
list.add(new Tuple2<>("liuhua","C"));
list.add(new Tuple2<>("xiaofeng","A"));
JavaPairRDD scoreDetail20 = sc.parallelizePairs(list);
JavaPairRDD scoreDetail2 = scoreDetail20.mapPartitionsToPair(new PairFlatMapFunction>, String, String>() {
@Override
public Iterator> call(Iterator> tuple2Iterator) throws Exception {
List> list = new ArrayList<>();
while (tuple2Iterator.hasNext()){
Tuple2 t1 = tuple2Iterator.next();
Tuple2 t2 = new Tuple2<>(t1._2(),t1._1());
list.add(t2);
}
return list.iterator();
}
});
JavaPairRDD> socerGroupres1 = scoreDetail2.groupByKey();
System.out.println(socerGroupres1.collect().toString());
JavaPairRDD socerReduceRes1 = scoreDetail2.reduceByKey(new Function2() {
@Override
public String call(String s, String s2) throws Exception {
return s + "," + s2;
}
});
System.out.println(socerReduceRes1.collect().toString());
//join 对两个RDD根据key进行连接操作
val data1 = sc.parallelize(Array(("A", 1),("b", 2),("c", 3)))
val data2 = sc.parallelize(Array(("A", 4),("A", 6),("b", 7),("c", 3),("c", 8)))
val joinRDD = data1.join(data2)
println(joinRDD.collect().mkString(","))
List> list1 = new ArrayList<>();
list1.add(new Tuple2("A", 1));
list1.add(new Tuple2("b", 2));
list1.add(new Tuple2("c", 3));
List> list2 = new ArrayList<>();
list2.add(new Tuple2("A", 4));
list2.add(new Tuple2("A", 6));
list2.add(new Tuple2("b", 7));
list2.add(new Tuple2("c", 3));
list2.add(new Tuple2("c", 8));
JavaPairRDD data1 = sc.parallelizePairs(list1);
JavaPairRDD data2 = sc.parallelizePairs(list2);
JavaPairRDD> dataJoin = data1.join(data2);
dataJoin.collect().forEach(x -> System.out.println(x));
Action 算子分类
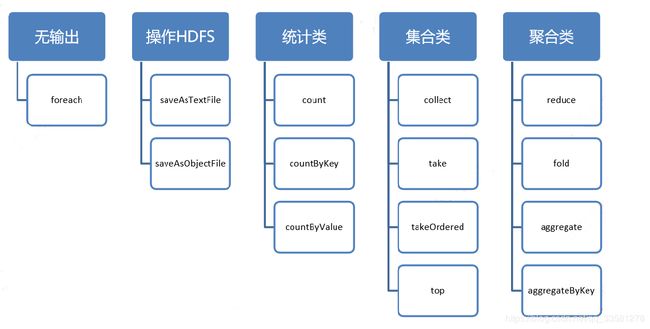
相关代码:
val data1 = sc.parallelize(Array(("A", 1),("b", 2),("c", 3),("A", 4),("A", 6),("b", 7),("c", 3),("c", 8)))
//count 从RDD中返回元素的个数
println(data1.count())
//countByKey 从RDD[K, V]中返回key出现的次数
println(data1.countByKey().mkString(","))
//countByValue 统计RDD中值出现的次数
println(data1.countByValue().mkString(","))
//take 从RDD中取0到num – 1下标的元素,不排序
println(data1.take(1).mkString(","))
//takeOrdered 从RDD中返按从小到大(默认)返回num个元素
println(data1.takeOrdered(3).mkString(","))
//top 和takeOrdered类似,但是排序顺序从大到小
println(data1.top(3).mkString(","))
List> list1 = new ArrayList<>();
list1.add(new Tuple2("A", 1));
list1.add(new Tuple2("b", 2));
list1.add(new Tuple2("c", 3));
list1.add(new Tuple2("A", 4));
list1.add(new Tuple2("A", 6));
list1.add(new Tuple2("b", 7));
list1.add(new Tuple2("c", 3));
list1.add(new Tuple2("c", 8));
JavaPairRDD data = sc.parallelizePairs(list1);
System.out.println("count" + data.count());
System.out.println("countByKey" + data.countByKey());
Map map = data.countByKey();
System.out.println("countByValue" + data.countByValue());
Map,Long> mapTuple = data.countByValue();
//take 取对象从1开始
List> takeList = data.take(1);
System.out.println("take");
takeList.forEach(x -> System.out.println(x._1()+"-"+x._2()));
JavaRDD data2 = sc.parallelize(Arrays.asList(9,3,4,2,6,8,4,5,6));
List takeOrderList = data2.takeOrdered(3);
System.out.println("takeOrdered");
takeOrderList.forEach(x -> System.out.println(x.toString()));
List takeTopList = data2.top(3);
takeTopList.forEach(x -> System.out.println(x.toString()));
//takeOrdered top 由于Tuple无法比较
//List> takeOrderList = data.takeOrdered(3);
//List> takeTopList = data.top(3);
//System.out.println("takeOrdered");
//takeOrderList.forEach(x -> System.out.println(x.toString()));
//System.out.println("top" );
//takeTopList.forEach(x -> System.out.println(x.toString()));
val data = sc.parallelize(List(1,2,3,2,3,4,5,4,3,6,8,76,8),3)
//reduce 对RDD中的元素进行聚合操作、注意:reduceByKey是Transformation,如果集合为空则会抛出Exception,Java实现可以为空,此时为0
val d = data.reduce(_ + _)
val f = data.filter(_ > 4).reduce(_ + _)
println(d)
println(f)
//fold 类似于reduce,对RDD进行聚合操作;首先每个分区分别进行聚合,初始值为传入的zeroValue,然后对所有 的分区进行聚合
val e = data.fold(0)(_+_)
val h = data.filter(_ >100).fold(0)(_+_)
println(e)
println(h)
JavaRDD data = sc.parallelize(Arrays.asList(1,3,4,6,2,3,4,5,6));
Integer sum = data.reduce(new Function2() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
Integer sum1 = data.filter(new org.apache.spark.api.java.function.Function() {
@Override
public Boolean call(Integer integer) throws Exception {
return integer>7;
}
}).fold(0, new Function2() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
System.out.println(sum);
System.out.println(sum1);
Integer sum2 = data.fold(0, new Function2() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
Integer sum3 = data.filter(new org.apache.spark.api.java.function.Function() {
@Override
public Boolean call(Integer integer) throws Exception {
return integer>7;
}
}).fold(0, new Function2() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
System.out.println(sum2);
System.out.println(sum3);
//aggregateByKey 分组计算平均值
val data = sc.parallelize( Seq ( ("A",110),("A",130),("A",120), ("B",200),("B",206),("B",206), ("C",150),("C",160),("C",170)))
val rdd1 = data.aggregateByKey((0,0))((k,v) => (k._1 + v,k._2 +1),(k,v) => (k._1 + v._1,k._2 + v._2))
val rdd2 = rdd1.mapValues(x => x._1/x._2)
println(rdd1.collect().mkString(","))
println(rdd2.collect().mkString(","))
List> list = new ArrayList<>();
list.add(new Tuple2<>("A",110));
list.add(new Tuple2<>("A",130));
list.add(new Tuple2<>("A",120));
list.add(new Tuple2<>("B",200));
list.add(new Tuple2<>("B",206));
list.add(new Tuple2<>("B",206));
list.add(new Tuple2<>("C",150));
list.add(new Tuple2<>("C",160));
list.add(new Tuple2<>("C",170));
JavaPairRDD data = sc.parallelizePairs(list);
JavaPairRDD> rdd = data.aggregateByKey(new Tuple2(0, 0), new Function2, Integer, Tuple2>() {
@Override
public Tuple2 call(Tuple2 v1, Integer v2) throws Exception {
return new Tuple2(v1._1() + v2,v1._2() +1);
}
}, new Function2, Tuple2, Tuple2>() {
@Override
public Tuple2 call(Tuple2 v1, Tuple2 v2) throws Exception {
return new Tuple2(v1._1() + v2.productArity(),v1._2() + v2._2());
}
}
);
System.out.println(rdd.collect().toString());
JavaPairRDD rdd2 = rdd.mapValues(new org.apache.spark.api.java.function.Function, Integer>() {
@Override
public Integer call(Tuple2 v1) throws Exception {
return v1._1()/v1._2();
}
});
System.out.println(rdd2.collect().toString()); 5、运行spark程序
- 本地运行:可直接执行main方法运行
- yarn(集群运行):spark-submit --master yarn-client --class spark的jar包路径