Intellij IDEA开发Hadoop伪分布式应用
在上一篇博客中(https://blog.csdn.net/qq_33588730/article/details/81123614)安装CDH5.15.0之后,安装好的是单机版Hadoop,并且准备好了伪分布式与全分布式需要的ssh远程登录配置,现在试试将Hadoop以伪分布式方式来运行,并用流行的Java开发软件Intellij IDEA来学习和开发Hadoop应用。
一、将Hadoop(CDH)以伪分布式启动
首先需要修改一些配置文件,在命令行中或者文件管理器的图形界面中找到Hadoop(CDH)安装目录下的/etc/hadoop目录,用vim或者gedit编辑器编辑以下4个文件:
(1)core-site.xml,顾名思义,用于定义一些核心的通用配置(如果要返回单机模式,删除该文件里的配置),定义HDFS的namenode主机与端口,默认为8020端口运行namenode:
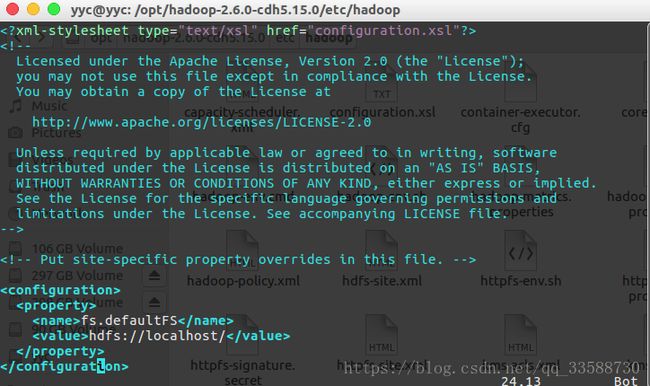
(2)hdfs-site.xml,用于配置HDFS的相关属性,这里配置保存文件副本数,学习的时候只有本机所以副本数为1:
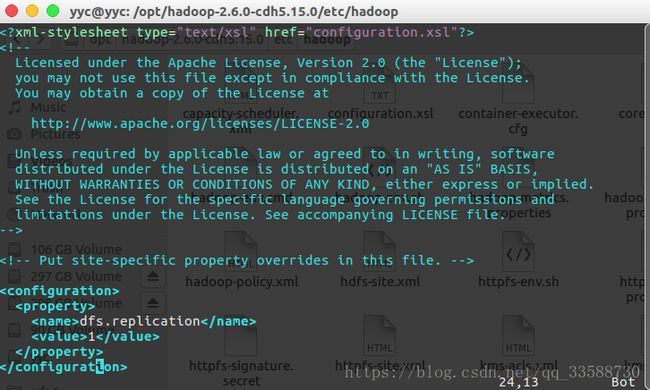
(3)mapred-site.xml,找到Hadoop(CDH)安装目录下/etc/hadoop文件夹内的mapred-site.xml.template文件,并重命名删去后缀.template,有该后缀就是模板文件不会被启用,去掉后缀变成mapred-site.xml可以使该配置文件生效,这个文件是用于配置MapReduce相关属性的,进行编辑,让mapreduce运行在yarn框架下:
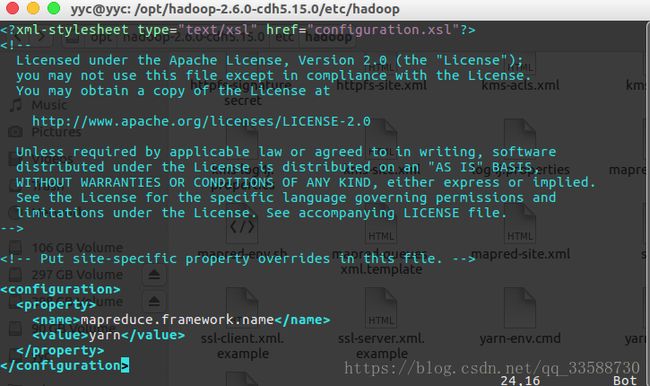
这里需要注意的是,如果不需要启动YARN的时候,一定要把mapred-site.xml重命名为mapred-site.xml.template模板文件,否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的错误,这也是为何默认安装单机模式的时候,该配置文件原本名为 mapred-site.xml.template。
(4)yarn-site.xml,用于配置YARN的相关属性,这里配置yarn的resourcemanager的主机名,以及nodemanager上运行的附属服务,配置成mapreduce_shuffle可运行mapreduce:

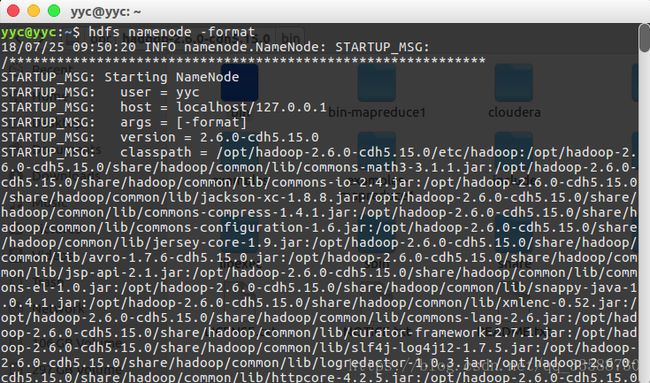
配置好配置文件之后,用hdfs namenode -format命令格式化HDFS文件系统,命令行日志的末尾会显示“successfully formatted”和“Exiting with status 0”,这就表示初始化成功,如果返回的状态码是1则有错误(这里直接可以在/home/yyc目录下输入命令启动在/opt目录下的hdfs是因为上一篇博客配置了环境变量):
需要注意的是,以后每次开机后,在启动Hadoop前都要使用这个命令格式化HDFS,因为HDFS实际的文件默认路径在系统的/tmp/hadoop-用户名/dfs/目录下,下次开机的时候会自动清除/tmp目录下的缓存,因此每次都需要重新初始化把文件写入/tmp,否则直接使用start-all.sh命令启动hdfs的时候会导致NameNode无法启动,使用jps命令查看进程的时候会发现没有NameNode,从而在执行hadoop fs -ls /命令的时候被拒绝连接,并报错“ls: Call From localhost/127.0.0.1 to localhost:8020 failed on connection exception: java.net.ConnectException: Connection refused”。
当然为了避免每次初始化NameNode的麻烦,也可以在用hdfs namenode -format命令初始化之前,在hdfs-site.xml文件中添加如下代码,使NameNode和DataNode的数据存储路径更换为其他的,就可以不用每次初始化NameNode了(默认NameNode的HDFS元数据在/tmp/hadoop-用户名/dfs/name目录,DataNode存储的数据块在/tmp/hadoop-用户名/dfs/data目录,SecondaryNameNode目录在/tmp/hadoop-用户名/dfs/namesecondary下):
dfs.name.dir
/opt/hadoop-2.6.0-cdh5.15.0/tmp/dfs/name
dfs.data.dir
/opt/hadoop-2.6.0-cdh5.15.0/tmp/dfs/data
或者:
dfs.tmp.dir
/opt/hadoop-2.6.0-cdh5.15.0/tmp
配置好hdfs-site.xml后,在core-site.xml中加入以下代码,修改Hadoop的临时目录位置,对应hdfs-site.xml中的NameNode和DataNode路径,是它们所在目录的的父目录:
hadoop.tmp.dir
/opt/hadoop-2.6.0-cdh5.15.0/tmp
除了编辑Hadoop配置文件的方法,也可以使用cd /etc/default命令进入到rcS文件所在目录,然后用sudo vim rcS命令编辑该文件,可以看到有一行“TMPTIME=0”,意思是下次启动立刻删除/tmp下的缓存,可以删掉“#”号注释并改为正整数变为x天后删除,改为-1则为永远不删除缓存,因为Hadoop和HDFS文件缓存默认存在/tmp目录下:

在用hdfs namenode -format命令将HDFS格式化之后,利用start-all.sh(相当于start-dfs.sh和start-yarn.sh)启动hdfs和yarn等组件,但是报错说没有指定JAVA_HOME环境变量,然而用echo $JAVA_HOME命令是可以返回Java所在目录的,这个环境变量其实存在,非常奇怪:
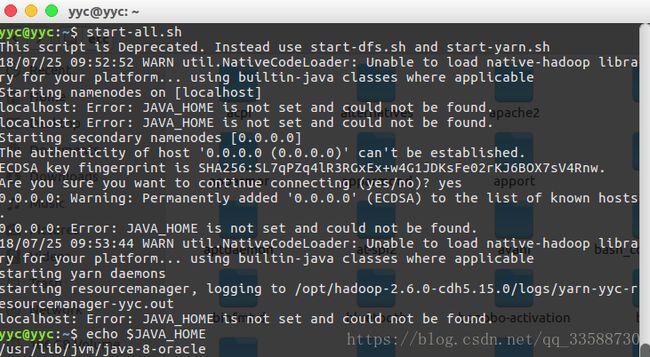
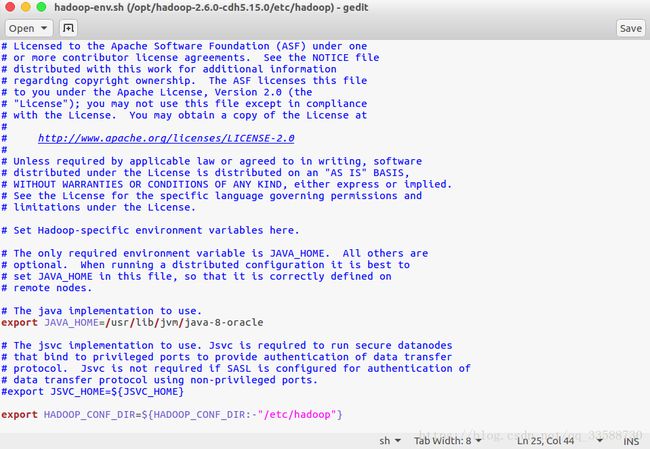
于是找到Hadoop安装目录下的/etc/hadoop目录,编辑里面的hadoop-env.sh,将里面的JAVA_HOME指向安装Java所在的绝对路径:
然后再试试start-all.sh命令,以及mr-jobhistory-daemon.sh start historyserver命令,这样就可以成功启动伪分布式Hadoop:
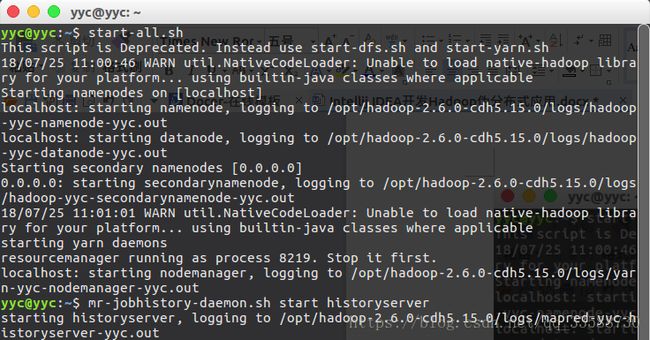
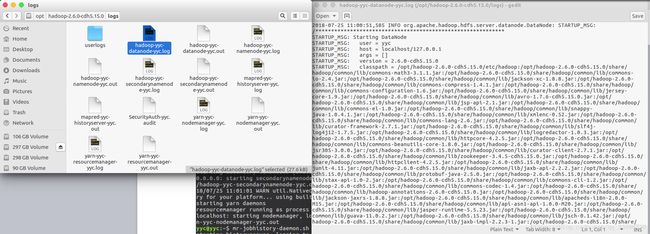
上面的步骤会使本机启动以下守护进程:一个namenode,一个辅助namenode,一个datanode(HDFS),一个资源管理器,一个节点管理器(YARN)和一个历史服务器(MapReduce)。可以看到Hadoop安装目录下的logs目录里生成了一些日志文件,可以用于检查守护进程是否成功启动,如下所示:
或者,通过Web界面:在浏览器地址栏里输入http://localhost:50070/查看NameNode,在http://localhost:8088/查看resource manager,在http://localhost:19888/查看历史服务器,如下所示:
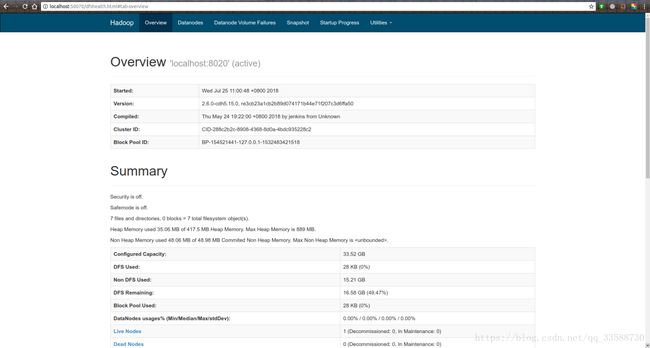
此外,用Java的jps命令也可以查看守护进程是否正在运行,如下所示:
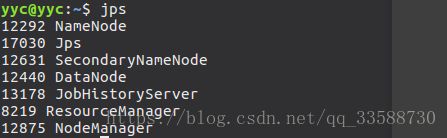
其中NameNode、SecondaryNameNode和DataNode属于HDFS,ResourceManager和NodeManager属于YARN,要终止守护进程,则要反过来输入三个停止命令(后两条也可以用stop-all.sh代替),如下所示:
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh启动伪分布式“集群”之后,用hadoop fs -ls /命令可以查看HDFS中存在的文件目录,但是发现会报警告,显示“WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable”,意思是hadoop不能加载{Hadoop安装目录}/lib/native里的本地库,警告不消除也能正常运行,但是略微拖慢运行速度,解决方法是在Ubuntu系统的/etc/profile文件以及CDH安装目录下的/etc/hadoop/hadoop-env.sh文件两处都加入三个环境变量:
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.15.0
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"然后再试试hadoop fs -ls /命令,就没有WARNING了,如下所示:
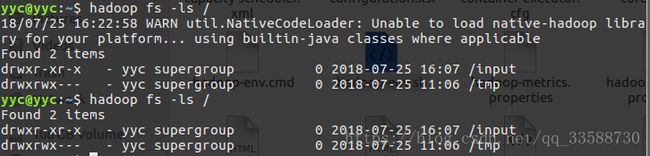
接着可以用hadoop fs -mkdir /input命令在HDFS上添加一个输入文件的目录,我在解决上面WARNING问题之前已经添加过,所以上图会显示有/input文件夹。
二、配置Intellij IDEA
伪分布式Hadoop启动之后,打开Intellij IDEA,新建一个工程,如下所示:
然后选择创建Maven工程,这是一个用于管理jar包的组件,本来一些Java程序需要依赖各种各样的jar包,需要自己去手动找到路径去导入,依赖大量jar包的时候手动一个个导入太过麻烦,Maven可以通过编辑一个叫pom.xml的配置文件来从Maven的代码库中自动下载所需要的jar包并配置依赖:
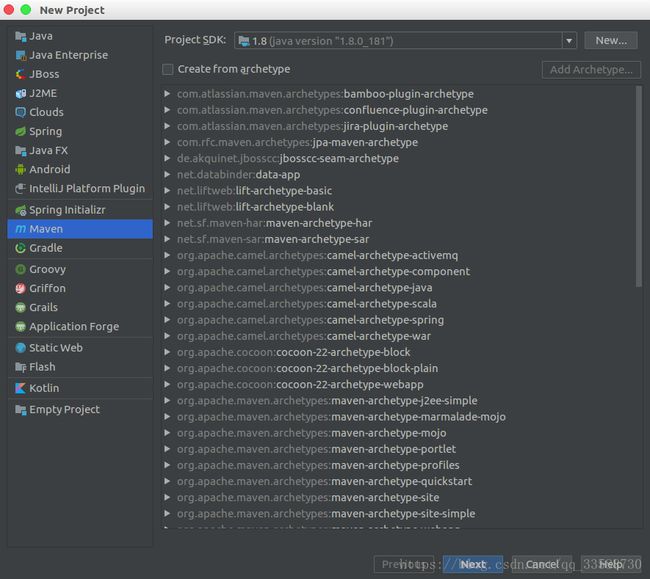
点击Next后,工程组名称和工程名称都可以随便写,然后点击Next,如下所示:
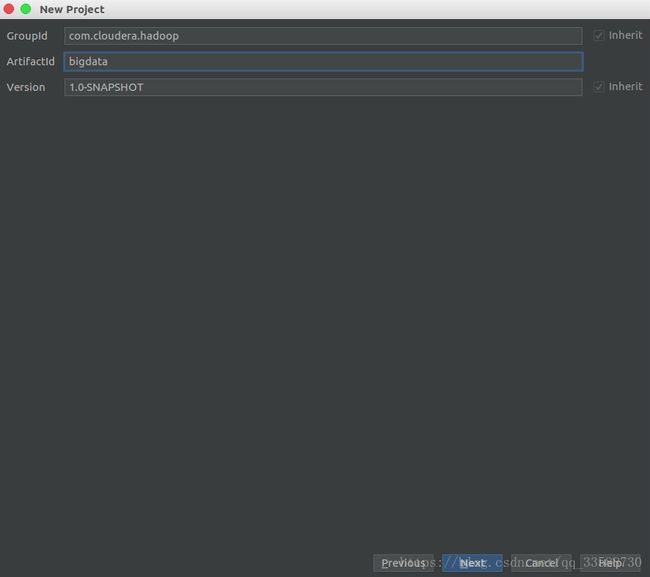
然后设置工程名称和所在目录,这里的Project name最好和ArtifactId一样,然后点击finish,如下所示:
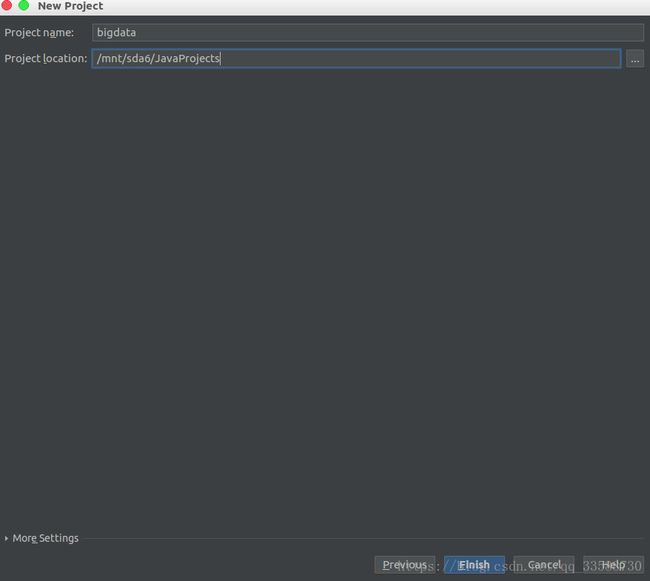
创建工程后,在左侧工程目录菜单里找到pom.xml,如下所示:

对这个文件进行编辑,根据Cloudera的官方网址的指导(https://www.cloudera.com/documentation/enterprise/release-notes/topics/cdh_vd_cdh5_maven_repo.html)输入以下xml代码:
4.0.0
com.cloudera.hadoop
bigdata
1.0-SNAPSHOT
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
true
false
2.6.0-cdh5.15.0
org.apache.hadoop
hadoop-common
${cdh.version}
provided
org.apache.hadoop
hadoop-core
2.6.0-mr1-cdh5.15.0
provided
org.apache.hadoop
hadoop-hdfs
${cdh.version}
provided
org.apache.hadoop
hadoop-client
2.6.0-mr1-cdh5.15.0
provided
pom.xml的dependency标签下可以加入想要导入的jar依赖包,groupId是工程组名称,artifactId是工程名称,version是版本,这三个信息唯一确定了要下载的jar包。
然后在左侧工程目录菜单栏里右键src/main/java文件夹,新建一个包(Package),如下所示:
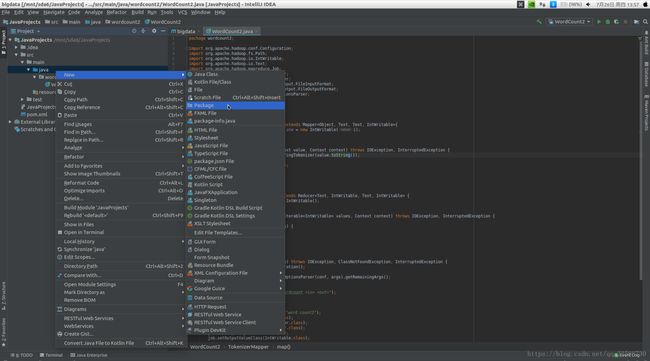
并在创建的wordcount2包下新建一个WordCount2类,写入如下代码:
package wordcount2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount2 {
public static class TokenizerMapper extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count2");
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
boolean flag = job.waitForCompletion(true);
System.out.println("Succeed! " + flag);
System.exit(flag ? 0 : 1);
System.out.println();
}
} 然后点击上面菜单栏的Run,点击Edit Configurations(在用命令行运行hadoop jar命令的时候,添加Application配置可跳过,该步骤是为了在Intellij IDEA中运行Hadoop调试),如下所示:
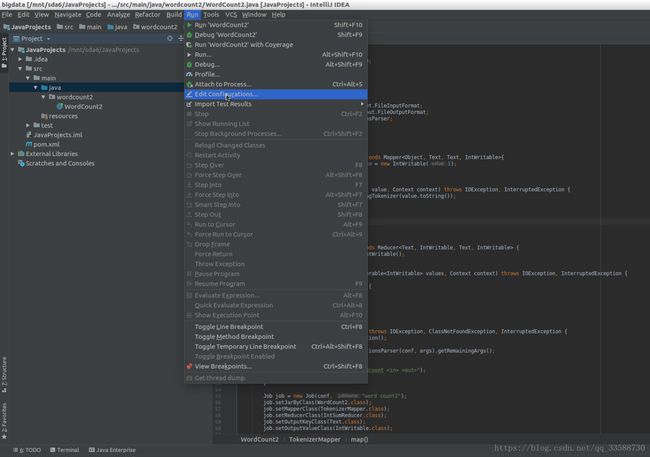
进入工程配置界面,点击左上角的加号,添加Application配置,如下所示:

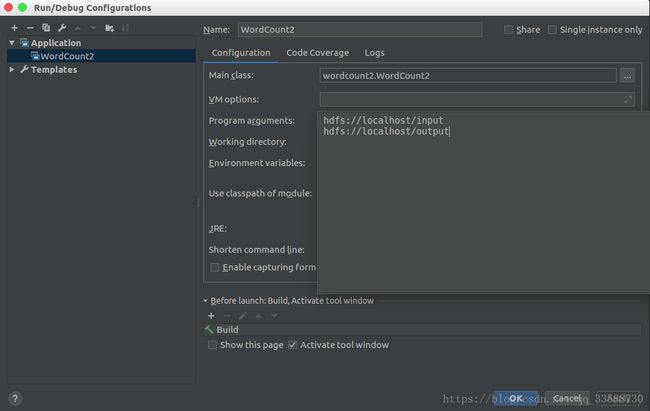
然后在右侧,Name可以给这个配置起名,Main class用于设置运行时的主类,格式为“Package.Class”,在Program arguments栏里输入Hadoop任务的输入目录和输出目录,我这里输入的是伪分布式情况下输入和输出文件夹的URL,这两个目录地址要与core-site.xml配置文件中的fs.defaultFS属性对应,如下所示:
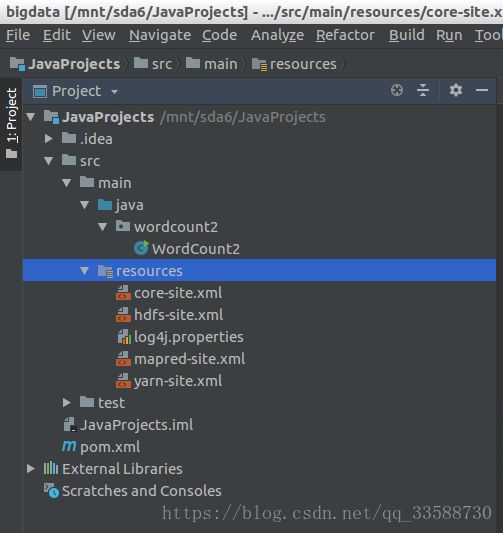
接着将Hadoop的配置文件放到工程目录下的src/main/resources文件夹下,如下所示:
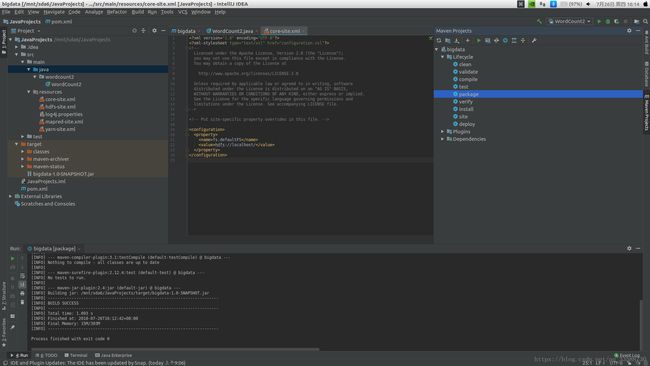
然后就可以把写的Java代码编译成jar包,点击界面右侧的Maven Projects选项卡,再双击Lifecycle选项下的compile,执行完成后再双击package在左侧工程目录里生成一个jar包,或者可以在界面底部打开terminal运行mvn compile和mvn package命令也是同样的效果,如下所示:
然后把生成的jar包重命名为wordcount2.jar,复制到让自己方便的路径,我复制到了自己手动挂载的机械硬盘分区/mnt/sda6上。
接着,将Hadoop安装目录下的/etc/hadoop目录内所有xml文件都作为输入文件上传到HDFS的/input文件夹内,输入如下命令:
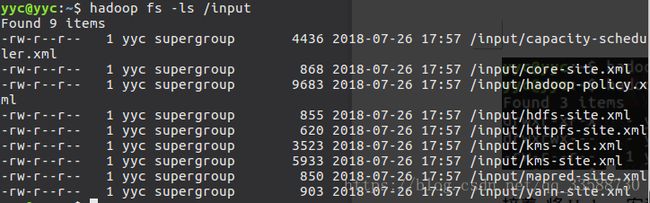
hadoop fs -put /opt/hadoop-2.6.0-cdh5.15.0/etc/hadoop/*.xml /input上传完成后,用hadoop fs -ls /input命令查看刚才上传的xml文件,如下所示:
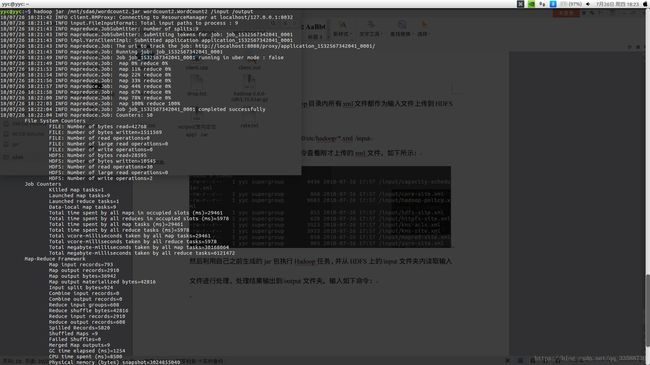
然后利用自己之前生成的jar包执行Hadoop任务,并从HDFS上的/input文件夹内读取输入文件进行处理,处理结果输出到/output文件夹。输入如下命令:
hadoop jar /mnt/sda6/wordcount2.jar wordcount2.WordCount2 /input /output指定生成的jar包所在位置后,还要指定执行的是哪个包中的哪个类,以"Package.class"的格式写清楚,后面加上用于输入给任务的文件所在路径,以及处理任务完成后输出的结果文件所在路径。
就可以看到任务运行成功,如下所示:
三、处理输出结果
在Hadoop任务运行成功后,可以通过hadoop fs -ls /命令看到HDFS生成了/output文件夹,里面有输出结果文件,如下所示:

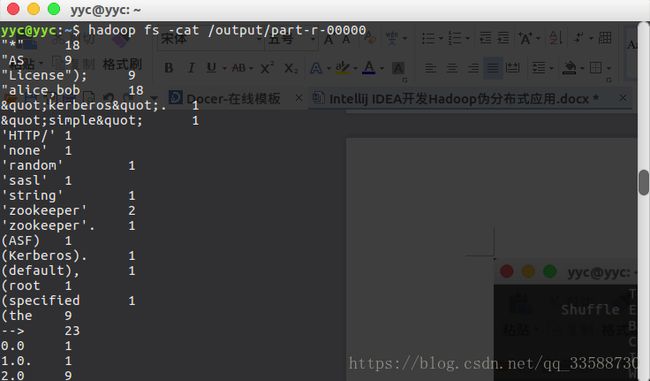
可以通过hadoop fs -cat /output/part-r-00000命令查看输出结果文件,如下所示:
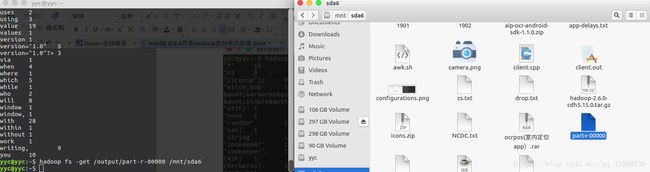
如果需要把Hadoop处理结果从HDFS下载到本地,可以使用hadoop fs -get /output/part-r-00000 /mnt/sda6命令将结果文件下载到自己指定的目录下,如下所示:
当然,也可以通过图形界面来下载,在浏览器地址栏里输入http://localhost:50070并回车,在顶部菜单栏点击Utilities,下拉菜单里点击Browse the file system,如下所示:

进入Browse Directory界面后,点击右侧的output链接,或者在上面搜索栏输入/output并点击“Go!”,就可以进入/output目录,如下所示:
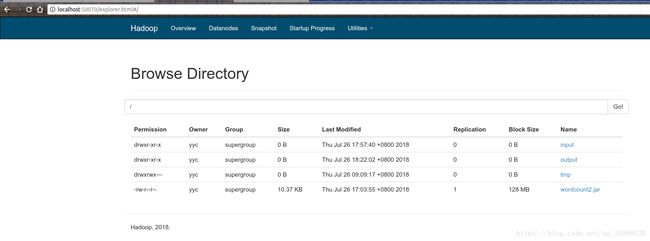
进入/output目录的界面后,点击右侧的part-r-00000链接,就会打开一个对话框,显示该文件的基本信息,上面有Download按钮可以下载该文件,如下所示:
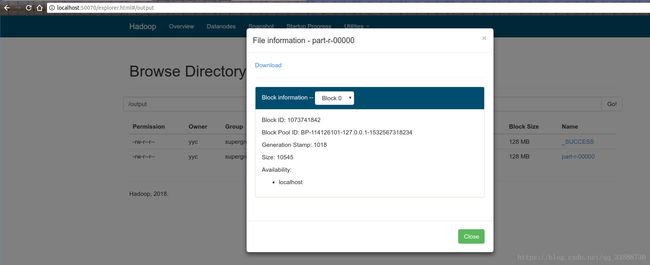
所有的结果分析工作处理完之后,一定要记得用hadoop fs –rm –r /output命令删除/output目录及其包含的所有文件,否则执行下一个任务的时候,还存在输出目录会报错:“org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost/output already exists”。如果之前没有修改NameNode和DataNode等HDFS组件的存储路径配置,第二次开机的时候也会自动删除/tmp/hadoop-用户名/下所有数据,包括输出文件夹也会被清除。