KD-tree的理解
1、kd-tree或者k维树是计算机科学中使用的一种数据结构,用来组织表示k维空间中点集合。它是一种带有其他约束条件的二分查找树。kd-tree对于区间和搜索十分有用。
2、对于构造kd-tree二叉树有两个关键的问题:1)每次对子空间的划分时,怎样确定在哪个维度上进行划分;2)在某个维度上进行划分时,怎样确保在这一维度上的划分得到的两个子集合的数量尽量相等,即左子树和右子树中的结点个数尽量相等。
问题1:每次对子空间的划分时,怎样进行划分?
最简单的方法就是轮着来,即如果这次选择了在第i维上进行数据划分,那下一次就在第j(j≠i)维上进行划分,例如:j = (i mod k) + 1。想象一下我们切豆腐时,先是竖着切一刀,切成两半后,再横着来一刀,就得到了很小的方块豆腐。
可是“轮着来”的方法是否可以很好地解决问题呢?再次想象一下,我们现在要切的是一根木条,按照“轮着来”的方法先是竖着切一刀,木条一分为二,干净利落,接下来就是再横着切一刀,这个时候就有点考验刀法了,如果木条的直径(横截面)较大,还可以下手,如果直径较小,就没法往下切了。因此,如果K维数据的分布像上面的豆腐一样,“轮着来”的切分方法是可以奏效,但是如果K维度上数据的分布像木条一样,“轮着来”就不好用了。因此,还需要想想其他的切法。
如果一个K维数据集合的分布像木条一样,那就是说明这K维数据在木条较长方向代表的维度上,这些数据的分布散得比较开,数学上来说,就是这些数据在该维度上的方差(invariance)比较大,换句话说,正因为这些数据在该维度上分散的比较开,我们就更容易在这个维度上将它们划分开,因此,这就引出了我们选择维度的另一种方法:最大方差法(max invarince),即每次我们选择维度进行划分时,都选择具有最大方差维度。
问题2:如何确保划分的左子树和右子树中的节点个数尽量相等。
假设当前我们按照最大方差法选择了在维度i上进行K维数据集S的划分,此时我们需要在维度i上将K维数据集合S划分为两个子集合A和B,子集合A中的数据在维度i上的值都小于子集合B中。首先考虑最简单的划分法,即选择第一个数作为比较对象(即划分轴,pivot),S中剩余的其他所有K维数据都跟该pivot在维度i上进行比较,如果小于pivot则划A集合,大于则划入B集合。把A集合和B集合分别看做是左子树和右子树,那么我们在构造一个二叉树的时候,当然是希望它是一棵尽量平衡的树,即左右子树中的结点个数相差不大。而A集合和B集合中数据的个数显然跟pivot值有关,因为它们是跟pivot比较后才被划分到相应的集合中去的。好了,现在的问题就是确定pivot了。给定一个数组,怎样才能得到两个子数组,这两个数组包含的元素个数差不多且其中一个子数组中的元素值都小于另一个子数组呢?方法很简单,找到数组中的中值(即中位数,median),然后将数组中所有元素与中值进行比较,就可以得到上述两个子数组。同样,在维度i上进行划分时,pivot就选择该维度i上所有数据的中值,这样得到的两个子集合数据个数就基本相同了。
Kd-tree的构造算法:
先定义一下节点的数据结构。每个节点应当有下面几个域:
Node-data - 数据矢量, 数据集中某个数据点,是n维矢量(这里也就是k维)
Range - 空间矢量, 该节点所代表的空间范围
split - 整数, 垂直于分割超平面的方向轴序号
Left - k-d树, 由位于该节点分割超平面左子空间内所有数据点所构成的k-d树
Right - k-d树, 由位于该节点分割超平面右子空间内所有数据点所构成的k-d树
parent - k-d树, 父节点

由于此例简单,数据维度只有2维,所以可以简单地给x,y两个方向轴编号为0,1,也即split={0,1}。
(1)确定split域的首先该取的值。分别计算x,y方向上数据的方差得知x方向上的方差最大,所以split域值首先取0,也就是x轴方向;
(2)确定Node-data的域值。根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以Node-data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于split = 0(x轴)的直线x = 7;
(3)确定左子空间和右子空间。分割超平面x = 7将整个空间分为两部分,如图2所示。x < = 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。
(4)k-d树的构建是一个递归的过程。然后对左子空间和右子空间内的数据重复根节点的过程就可以得到下一级子节点(5,4)和(9,6)(也就是 左右子空间的’根’节点),同时将空间和数据集进一步细分。如此反复直到空间中只包含一个数据点,如图1所示。最后生成的k-d树如图3所示。
查找算法
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
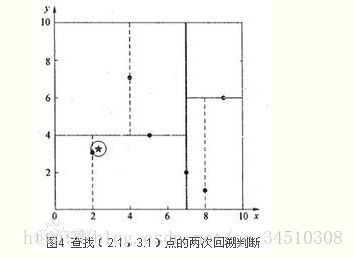
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快 就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶 子节点的圆域内。为了找到真正的最近邻,还需要进行’回溯’操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中先从(7,2)点开始进行 二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为<(7,2),(5,4),(2,3)>,首先以(2,3)作为 当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查 询点更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如图4所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。
3、本人参考以下几个博客,大概了解了kd-tree的基本原理,欢迎前来留言交流。
参考博客链接:http://blog.csdn.net/junshen1314/article/details/51121582
http://www.cnblogs.com/li-yao7758258/p/6437440.html
http://blog.csdn.net/silangquan/article/details/41483689
4、希望大家和我一样有大的收获。
5、鸡汤一下:知识需要分享,赠人玫瑰,手留余香。