服务链路追踪-Sleuth :解决分布式部署下最头疼的溯源问题
文章目录
- 一、服务调用链追踪
- 二、核心功能和体系架构
- 1、核心功能
- 2、设计理念
- 3、数据埋点
- 4、Sleuth与Log系统集成原理
- 1)Log Format Pattern
- 2)MDC
- 5、Sleuth数据结构
- 1)Annotation标记
- 2)服务节点间的ID传递
- 三、整合Sleuth追踪调用链路
- 1、创建Sleuth项目
- 1)创建一个模块命名为sleuth-traceA,修改pom文件
- 2)修改启动文件
- 3)创建配置文件
- 4)在resources中添加日志配置文件logback-spring.xml
- 5)编写controller
- 6)创建一个新的模块sleuth-traceB,和之前的步骤一样
- 7)测试
- 四、Zipkin
- 1、Zipkin的核心功能
- 2、Zipkin的组件
- 3、Zipkin与Sleuth集成,日志分析和链路追踪
- 1)创建一个模块,起名zipkin-server,并修改pom文件
- 2)修改启动类
- 3)创建配置文件
- 4)访问zipkin地址
- 5)修改之前写的sleuth-traceA和B,修改pom文件
- 6)修改之前写的sleuth-traceA和B,修改配置文件
- 五、Sleuth集成ELK实现日志搜索
- 1)使用docker快速搭建ELK
- 2)Sleuth日志推送给ELK
一、服务调用链追踪
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
二、核心功能和体系架构
Sleuth的意思是大侦探,顾名思义,侦探就是查找信息搜集线索,顺着线索链找到所有上下游的关联,这恰好正是Seluth在Spring Cloud中的工作
1、核心功能
借助Sleuth的链路追踪能力,我们还可以完成一些其他的任务,比如说:
- 线上故障定位:结合Tracking ID寻找上下游链路中所有的日志信息(这一步还需要借助一些其他开源组件,后面会有这部分的Demo)
- 依赖分析梳理:梳理上下游依赖关系,理清整个系统中所有微服务之间的依赖关系
- 链路优化:比如说目前我们有三种途径可以导流到下单接口,通过对链路调用情况的统计分析,我们可以识别出转化率最高的业务场景,从而为以后的产品设计提供指导意见。
- 性能分析:梳理各个环节的时间消耗,找到性能瓶颈,为性能优化、软硬件资源调配指明方向
2、设计理念
- 无业务侵入:如果说接入某个监控组件还需要改动业务代码,那么我们认为这是一个“高侵入性”的组件。Sleuth在设计上秉承“低侵入”的理念,不需要对业务代码做任何改动,即可静默接入链路追踪功能
- 高性能:一般认为在代码里加入完善的log(10行代码对应2条log)会对降低5%左右接口性能(针对非异步log框架),而通过链路追踪技术在log里做埋点多多少少也会影响性能。Sleuth在埋点过程中力求对性能影响降低到最小,同时还提供了“采样率配置”来进一步降低开销(比如说开发人员可以设置只对20%的请求进行采样)
3、数据埋点
每一个微服务都有自己的Log组件(slf4j,lockback等各不相同),当我们集成了Sleuth之后,它便会将链路信息传递给底层Log组件,同时Log组件会在每行Log的头部输出这些数据,这个埋点动作主要会记录两个关键信息:
- 链路ID(Trace ID):当前调用链的唯一ID,在这次调用请求开始到结束的过程中,所有经过的节点都拥有一个相同的链路ID
- 单元ID(Event ID): 在一次链路调用中会访问不同服务器节点上的服务,每一次服务调用都相当于一个独立单元,也就是说会有一个独立的单元ID。同时每一个独立单元都要知道调用请求来自哪里(就是对当前服务发起直接调用的那一方的单元ID,我们记为Parent ID)
4、Sleuth与Log系统集成原理
我们需要把链路追踪信息加入到业务Log中,这些业务Log是我们研发人员写在具体服务里的,而不是Sleuth单独打印的log,因此Sleuth需要找到一个合适的切入点,让底层Log组件可以获取链路信息,并且我们的业务代码还不需要做任何改动。
如果有对Log框架做过深度定制的同学可能一下就能想到实现方式,就是使用MDC + Format Pattern的方式输出信息,我们先来看一下Log组件打印信息到文件的过程:
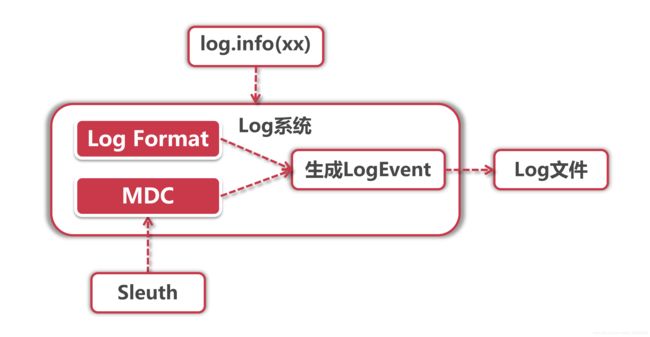
当我们使用"log.info"打印日志的时候,Log组件会将“写入”动作封装成一个LogEvent事件,而这个事件的具体表现形式由Log Format和MDC共同控制,Format决定了Log的输出格式,而MDC决定了输出什么内容。
1)Log Format Pattern
Log组件定义了日志输出格式,这和我们平时使用“String.format”的方式差不多,集成了Sleuth后的Log输出格式是下面这个样子:
%5p [sleuth-traceA,%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]
同学们发现上面有几个X开头的占位符,这就是我们需要写入Log的链路追踪信息
2)MDC
MDC是通过InheritableThreadLocal来实现的,它可以携带当前线程的上下文信息。它的底层是一个Map结构,存储了一系列Key-Value的值。Sleuth就是借助Spring的AOP机制,在方法调用的时候配置了切面,将链路追踪数据加入到了MDC中,这样在打印Log的时候,就能从MDC中获取这些值,填入到Log Format中的占位符里。
由于MDC基于InheritableThreadLocal而不是ThreadLocal实现,因此假如在当前线程中又开启了新的子线程,那么子线程依然会保留父线程的上下文信息。
5、Sleuth数据结构
- Trace:它就是从头到尾贯穿整个调用链的ID,我们叫它Trace ID,不管调用链路中途访问了多少服务节点,在每个节点的log中都会打印同一个Trace ID
- Span:它标识了Sleuth下面一个基本的工作单元,每个单元都有一个独一无二的ID。比如服务A发起对服务B的调用,这个事件就可以看做一个独立单元,生成一个独立的ID
Span不单单只是一个ID,它还包含一些其他信息,比如时间戳,它标识了一个事件从开始到结束经过的时间,我们可以用这个信息来统计接口的执行时间。每个Span还有一系列特殊的“标记”,也就是接下来要介绍的“Annotation”,它标识了这个Span在执行过程中发起的一些特殊事件。
1)Annotation标记
一个Span可以包含多个Annotation,每个Annotation表示一个特殊事件,比如:
- cs Client Sent:客户端发送了一个调用请求
- sr Server Received:服务端收到了来自客户端的调用
- ss Server Sent:服务端将Response发送给客户端
- cr Client Received:客户端收到了服务端发来的Response
每个Annotation同样有一个时间戳字段,这样我们就能分析一个Span内部每个事件的起始和结束时间。这里我选取了Spring Cloud官网的一张图来展示Trace、Span和Annotation的关系。
2)服务节点间的ID传递
我们知道了Trace ID和Span ID,眼下的问题就是如何在不同服务节点之间传递这些ID。我想这一步大家很容易猜到是怎么做的,因为在Eureka的服务治理下所有调用请求都是基于HTTP的,那我们的链路追踪ID也一定是HTTP请求中的一部分。可是把ID加在HTTP哪里好呢?Body里可以吗?NoNoNo,一来GET请求压根就没有Body,二来加入Body还有可能影响后台服务的反序列化。那加在URL后面呢?似乎也不妥,因为某些服务组件对URL的长度可能做了限制(比如Nginx可以设置最大URL长度)。
那剩下的只有Header了!Sleuth正是通过Filter向Header中添加追踪信息,我们来看下面表格中Header Name和Trace Data的对应关系:
| HTTP Header Name | Trace Data | |
|---|---|---|
| X-B3-TraceId | Trace ID | 链路全局唯一ID |
| X-B3-SpanId | Span ID | 当前Span的ID |
| X-B3-ParentSpanId | Parent Span ID | 前一个Span的ID |
| X-Span-Export | Can be exported for sampling or not | 是否可以被采样 |
三、整合Sleuth追踪调用链路
1、创建Sleuth项目
1)创建一个模块命名为sleuth-traceA,修改pom文件
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
dependencies>
2)修改启动文件
@EnableDiscoveryClient
@SpringBootApplication
public class SleuthTraceA{
public static void main(String[] args){
new SpringApplicationBuilder(SleuthTraceA.class)
.web(WebApplicationType.SERVLET)
.run(args);
}
@LoadBalanced
@Bean
public RestTemplate lb(){
return new RestTemplate();
}
}
3)创建配置文件
spring.application.name=sleuth-traceA
server.port=62000
eureka.client.serviceUrl.defaultZone=http://localhost:20000/eureka/
logging.file=${spring.application.name}.log
#日志采样率, 1:所有的日志都会被采样
spring.sleuth.sampler.probability=1
info.app.name=sleuth-traceA
info.app.description=test
management.security.enabled=false
management.endpoints.web.exposure.include=*
management.endpoint.health.show-details=always
4)在resources中添加日志配置文件logback-spring.xml
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<property name="CONSOLE_LOG_PATTERN" value="%clr(%d{HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" />
<appender name="consoleLog" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFOlevel>
filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}pattern>
<charset>utf8charset>
encoder>
appender>
<root level="DEBUG">
5)编写controller
//lombok的注解 用来打印日志,用其他的方式打印日志也是一样的
@Slf4j
@RestController
public class ControllerA{
@Autowired
private RestTemplate restTemplate;
@GetMapping(value = "/traceA")
public String traceA(){
log.info("--------Trace A");
return restTemplate.getForEntity("http://sleuth-traceB/traceB",String.class).getBody();
}
}
6)创建一个新的模块sleuth-traceB,和之前的步骤一样
1.修改以下配置文件中的3个参数
spring.application.name=sleuth-traceB
server.port=62001
info.app.name=sleuth-traceB
2.修改一下Controller
//lombok的注解 用来打印日志,用其他的方式打印日志也是一样的
@Slf4j
@RestController
public class ControllerB{
@Autowired
private RestTemplate restTemplate;
@GetMapping(value = "/traceB")
public String traceB(){
log.info("--------Trace B");
return "traceB";
}
}
7)测试
1.启动服务发现中心(示例中没有需要自己配置下)
2.启动traceB和traceA
3.调用/traceA接口参看日志
四、Zipkin
Zipkin是一套分布式实时数据追踪系统,它主要关注的是时间维度的监控数据,比如某个调用链路下各个阶段所花费的时间,同时还可以从可视化的角度帮我们梳理上下游系统之间的依赖关系。
Sleuth为什么需要一个搭档?大家难道没发现Sleuth空有一身本领,可是没个页面可以show出来吗?而且Sleuth似乎只是自娱自乐在log里埋点,却没有一个汇聚信息的能力,不方便对整个集群的调用链路进行分析。Sleuth目前的情形就像Hystrix一样,也需要一个类似Turbine的组件做信息聚合+展示的功能。在这个背景下,Zipkin就是一个不错的选择。
1、Zipkin的核心功能
Zipkin的主要作用是收集Timing维度的数据,以供查找调用延迟等线上问题。所谓Timing其实就是开始时间+结束时间的标记,有了这两个时间信息,我们就能计算得出调用链路每个步骤的耗时。Zipkin的核心功能有以下两点
- 数据收集:聚合客户端数据
- 数据查找:通过不同维度对调用链路进行查找
Zipkin分为服务端和客户端,服务端是一个专门负责收集数据、查找数据的中心Portal,而每个客户端负责把结构化的Timing数据发送到服务端,供服务端做索引和分析。这里我们重点关注一下“Timing数据”到底用来做什么,前面我们说过Zipkin主要解决调用延迟情况的线上排查,它通过收集一个调用链上下游所有工作单元的独立用时,Zipkin就能知道每个环节在服务总用时中所占的比重,再通过图形化界面的形式,让开发人员知道性能瓶颈出在哪里。
Zipkin提供了多种维度的查找功能用来检索Span的耗时,最直观的是通过Trace ID查找整个Trace链路上所有Span的前后调用关系和每阶段的用时,还可以根据Service Name或者访问路径等维度进行查找
2、Zipkin的组件
- Collector:很多人以为Collector是一个客户端组件,其实它是Zipkin Server的守护进程,用来验证客户端发送来的链路数据,并在存储结构中建立索引。守护进程就是指一类用于执行特定任务的后台进程,它独立于Zipkin Server的控制终端,一直等待接收客户端数据。
- Storage:Zipkin支持ElasticSearch和MySQL等存储介质用来保存链路信息,本章demo中采用默认的Cassandra作为存储方式
- Search Engine:提供基于JSON API的接口来查找信息
- Dashboard:一个大盘监控页面,后台调用Search Engine来获取展示信息。大家如果本地启动Zipkin会每次刷新主页后系统日志会打印Error信息,这个是Zipkin的一个小问题,直接跳过即可
3、Zipkin与Sleuth集成,日志分析和链路追踪
1)创建一个模块,起名zipkin-server,并修改pom文件
<dependencies>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
<version>2.8.4version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
<version>2.8.4version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<configuration>
<mainClass>>com.test.spring.ZipkinApplicationmainClass>
configuration>
<executions>
<execution>
<goals>
<goal>repackagegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
2)修改启动类
//选哪个没有被标记为Deprecated的
@EnableZipkinServer
@SpringBootApplication
public class ZipkinApplication{
public static void main(String[] args){
new SpringApplicationBuilder(ZipkinApplication.class)
.web(WebApplicationType.SERVLET)
.run(args);
}
}
3)创建配置文件
spring.application.name=zipkin-server
server.port=62100
#允许bean重载
spring.main.allow-bean-definition-overriding=true
management.metrics.web.server.auto-time-requests=false
4)访问zipkin地址
localhost:62100/zipkin/
5)修改之前写的sleuth-traceA和B,修改pom文件
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
6)修改之前写的sleuth-traceA和B,修改配置文件
#zipkin的地址
spring.zipkin.base-url=http://localhost:62100
#使用http上传数据到zipkin
#因为有可能后引入bus依赖导入了rabbitmq的依赖,zipkin会自动切换到RabbitMq上
spring.zipkin.sender.type=web
五、Sleuth集成ELK实现日志搜索
1)使用docker快速搭建ELK
- ElasticSearch:存储Log信息,并提供搜索功能
- Logstash:log信息收集过滤
- Kibana:Log信息的查询报表
1.使用docker下载elk镜像(很慢需要耐心)
docker pull sebp/elk
2.创建Docker容器(第一次使用的时候才需要创建,启动很慢 5-10分钟)
#kibana的端口 ElasticSearch端口 LogStash端口 容器名称 启动的镜像
docker run -p 5601:5601 -p 9200:9200 -p5044:5044 -e ES_MIN_MEM=128m -e ES_MAX_MEM=1025m -it --name elk sebp/elk
3.再次启动的命令docker容器(启动很慢 5-10分钟)
docker start elk
4. 进入docker容器:
docker exec -it elk /bin/bash
5.修改配置文件
配置文件位置: /etc/logstash/conf.d/02-beats-input.conf
将内容全部删除,替换成下面的配置
input{
tcp{
port =>5044
codec => json_lines
}
}
output{
elasticsearch{
hosts => ["localhost:9200"]
}
}
6.重启docker容器(启动很慢 5-10分钟)
docker restart elk
7.访问Kibana
http://localhost:5601/
2)Sleuth日志推送给ELK
1.修改之前写的sleuth-traceA和B,修改pom文件
<dependency>
<groupId>net.logstash.logbackgroupId>
<artifactId>logstash-logback-encoderartifactId>
<version>5.2version>
dependency>
2.修改日志配置文件logback-spring.xml,下面是完整的配置,添加logstashLog了
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<property name="CONSOLE_LOG_PATTERN" value="%clr(%d{HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}" />
<appender name="consoleLog" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFOlevel>
filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}pattern>
<charset>utf8charset>
encoder>
appender>
<appender name="logstashLog" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>127.0.0.1:5044destination>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTCtimeZone>
timestamp>
<pattern>
<pattern>
{
"severity":"%level",
"service":"${springAppName:-}",
"trace":"%X{X-B3-TraceId:-}",
"span":"%X{X-B3-SpanId:-}",
"exportable":"%X{X-SpanId-Export:-}",
"pid":"${PID:-}",
"thread":"%thread",
"class":"%logger{40}",
"rest":"%message"
}
pattern>
pattern>
providers>
encoder>
appender>
<root level="DEBUG">
3.配置完成,发起一个调用,查看Kibana