Hadoop集群搭建实验(1) _伪分布式部署
〇 基础练习
1)安装虚拟机VirtualBox
先卸载,再安装,
学会基本操作, 启动虚拟机, 新建虚拟机, 主机网络管理器查看虚拟网卡,
2)安装CentOS
安装1台干净的CentOS作为搭建hadoop集群的基础环境
纯命令行界面安装,root用户成功登陆, 忘记root密码会修改,
虚拟网卡配置, win7和CentOS构成的网络拓扑,ifconfig查看IP地址, ping命令测试,XSHELL远程连接,
修改配置文件配置IP地址, 配置文件的位置/etc/sysconfig/network-scripts
配置YUM源, 连接阿里源,自动安装软件 yum list 和 yum install
学会虚拟机的复制,复制后应该修改IP,避免IP地址冲突, 复制的新虚拟机的MAC地址是自动分配的不会冲突
可参考系列博文Hadoop手把手逐级搭建,从单机伪分布到高可用+联邦
https://yq.aliyun.com/users/r3cgwpwhr7cie?spm=a2c4e.11153940.0.0.cea964409exlsb
一 Hadoop伪分布式部署(Pseudo Distributed)
1)复制一台新的CentOS虚拟机
必须关机后才能复制
2)XSHELL远程登录
注意VirtualBox主机网络管理器的虚拟网卡IP地址必须和CentOS一个网段
3)通过配置文件修改IP地址
配置文件位置/etc/sysconfig/network-scripts/ifcfg-enp0s8,文件名和网络名称对应
修改后执行service network restart重启网络接口,XSHELL用新的IP地址重新连接
4)拷贝Hadoop安装包和JAVA JDK安装包到Linux
拷贝到/root目录
5)解两个压缩安装包到指定目录
cd /root
tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C /usr/local/
tar -zxvf jdk-7u79-linux-x64.tar.gz -C /usr/local/
cd /usr/local/
请注意:如果执行echo $JAVA_HOME发现Java JDK已经安装,可以跳过4)5)两个步骤中的拷贝和解压缩Java JDK安装包的步骤
6)修改hostname主机名
vi /etc/hostname 主机名修改为hadoop
7)修改hosts文件
vi /etc/hosts
前两行保留,删除掉多余的行,只增加一行
192.168.56.10 hadoop
注意:IP地址设置为虚拟机Linux的IP地址,按实际地址设置
8)设置环境变量并使之生效
vi /etc/profile
增加以下内容:
#jdk
export JAVA_HOME=/usr/local/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
#hadoop
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh5.7.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile 让环境变量生效
echo $JAVA_HOME
echo $HADOOP_HOME 测试环境变量是否生效
9)设置本机的SSH免密登录
执行 ssh hadoop 或 ssh 192.168.56.20(当前Linux的IP地址),测试能否免密登录本机Linux,如果必须输入才能登录,就必须进行SSH免密登录设置
执行ssh-keygen命令,遇到提示直接回车,生成一个密钥对,使用RSA加密算法,生成一个公钥和一个私钥
执行ssh-copy-id hadoop 或 ssh 192.168.56.20命令 , 把公钥发送到目标机
再次执行 ssh hadoop 或 ssh 192.168.56.20,测试能否免密登录本机Linux,如果能不输入密码自动登录成功,说明SSH免密登录设置成功
10)关闭防火墙firewall和SeLinux
关闭防火墙命令 systemctl disable firewalld 关闭后执行systemctl status firewalld查看防火墙状态为inactive,关闭成功
关闭SeLinux命令 setenforce 0 关闭后执行getenforce查看SeLinux的状态为Permissive,关闭成功
11)修改hadoop-env.sh文件
文件路径是/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hadoop-env.sh
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vi hadoop-env.sh
a)修改JAVA_HOME环境变量的值为java jdk的存放路径
# export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/java/jdk1.8
b)还要修改HADOOP_CONF_DIR变量的值,HADOOP_CONF_DIR表示hadoop配置文件的存放路径,否则执行start-dfs.sh启动hdfs时会报错
#export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
执行source hadoop-env.sh让设置生效
12)配置core-site.xml文件
文件路径是/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vi core-site.xml
在
13)修改hdfs-site.xml 配置文件
文件路径是/usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hdfs-site.xml
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
vi hdfs-site.xml
在
14)修改slaves文件
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop/ 切换到slaves文件所在目录
vi slaves
删除localhost,添加本机名hadoop
15)创建HDFS存放数据的目录
cd /root 切换到root目录
执行命令mkdir -p hdfs/tmp 在root目录下创建两级子目录/root/hdfs/tmp,
路径/root/hdfs/tmp和core-site.xml文件中的hadoop.tmp.dir参数值相同
16)格式化HDFS文件系统
首次启动Hadoop集群之前,必须先格式化HDFS文件系统
cd $HADOOP_HOME 切换到hadoop安装目录
cd bin 切换到bin目录
ls 查看 有一个SHELL脚本文件hdfs
执行 hdfs namenode -format 格式化命令
出现Storage directory /root/hdfs/tmp/dfs/name has been successfully formatted.
17)启动HDFS集群
执行脚本start-dfs.sh启动hdfs
18)执行java进程查看命令jps,除了Jps外,出现以下三个进程,说明HDFS启动成功:
3041 NameNode
3315 SecondaryNameNode
3128 DataNode
3500 Jps
进程启动问题的解决:
如果发现NameNode进程没有启动,
可先尝试执行hadoop-daemon.sh start namenode命令来启动namenode,
再输入jps命令查看NameNode进程是否启动,
如果NameNode还没有启动, 再执行stop-dfs.sh停止hdfs所有进程,
再执行hdfs namenode -format命令,重新执行一次格式化,
然后再次执行start-dfs.sh启动hdfs的所有进程,
最后,执行jps命令,查看NameNode,DataNode,SecondaryNameNode三个进程,是否全部启动成功
19)执行hadoop fs -ls / 查看hdfs文件系统目录
此时hdfs文件系统根目录下还没有任何目录,
可以执行hadoop fs -mkdir /input命令,在hdfs文件系统的根目录下创建一个input子目录,
然后再执行hadoop fs -ls / 查看目录命令, 会发现出现了一个子目录:
Found 1 items
drwxr-xr-x - root supergroup 0 2019-09-12 09:50 /input
还可以执行hadoop fs -put /usr/local/hadoop-2.6.0-cdh5.7.0/README.txt /input 命令, 把Linux本地文件系统上的一个文件上传到HDFS文件系统的/input目录中
20)在win7下,用chrome浏览器访问HDFS自带的web配置网站 http://192.168.56.20:50070 ,能出现如下页面说明访问成功:
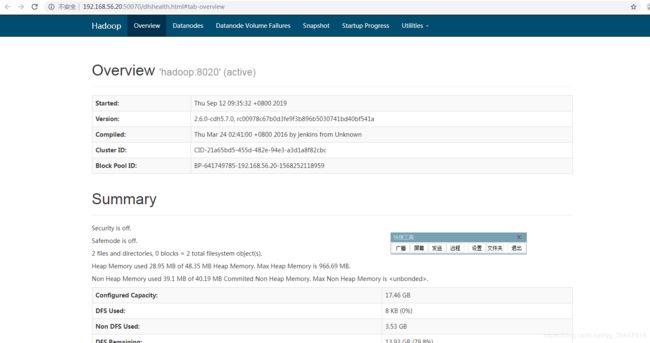 标题
标题
================================================================================
从第21步开始,执行配置并启动资源协调器yarn
21)修改mapred.xml配置文件
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop 切换到mapred.xml配置文件所在目录
cp mapred-site.xml.template mapred-site.xml 复制mapred-site.xml.template模板文件为一个新配置文件mapred-site.xml
vi mapred-site.xml
在
22)修改yarn-site.xml配置文件
cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop 切换到yarn-site.xml配置文件所在目录
vi yarn-site.xml
在
23)启动资源协调器yarn
执行脚本start-yarn.sh启动yarn
24)执行java进程查看命令jps,除了Jps外,多出现两个进程ResourceManager和NodeManager,说明yarn启动成功:
2688 DataNode
2833 Jps
2546 NameNode
2116 ResourceManager
2196 NodeManager
2794 SecondaryNameNode
25)在win7下,用chrome浏览器访问yarn自带的web配置网站 http://192.168.56.20:8088,能出现如下页面说明访问成功:
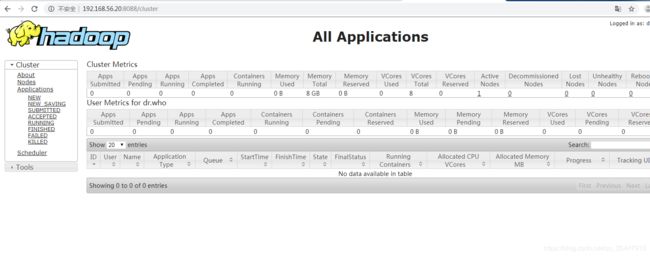
=========================================================================
从第26步开始,运行一个hadoop自带的mapreduce示例程序:wordcount词频统计
本次练习使用官方案例程序
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
26)首先确认第25步已经成功启动资源协调器yarn,如果没有启动就执行start-yarn.sh启动yarn
再执行文件上传命令,上传本地Linux文件系统的一个文件文件README.txt 到hdfs文件系统的/inpu目录
hadoop fs -put /usr/local/hadoop-2.6.0-cdh5.7.0/README.txt /input
27)执行词频统计程序wordcount
切换到目录 cd /usr/local/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
执行命令hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /input/README.txt /output
请注意/output不能提前存在,执行命令后会自动创建改目录
28)查看词频统计程序wordcount的执行结果
先执行命令 hadoop fs -ls /output 查看hdfs的/output目录的内容,应该出现:
Found 2 items
-rw-r--r-- 1 root supergroup 0 2019-09-16 09:50 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 1306 2019-09-16 09:50 /output/part-r-00000
wordcount运行结果会输出到文件output/part-r-00000中,执行命令:
hadoop fs -cat /output/part-r-00000 查看词频统计程序wordcount的执行结果,类似:
details 1
distribution 2
eligible 1
encryption 3
exception 1
说明词频统计程序运行正确