爬虫(一)Requests
课程大纲

0.课程使用的开发工具
IDLE PyCharm Sublime Text Anaconda&Spyder
1.requests库的安装
右键开始,点windows powershell或者 在C:\windows\system32找到cmd,以管理员的身份打开
输入 pip install requests

下载完requests库后在IDLE输入
>>> import requests
>>> r=requests.get("http://www.baidu.com")
>>> r.status_code #检测请求的状态码,200则访问成功
200
>>> r.encoding='utf-8' #如果没有赋值则显示'ISO-8859-1',显示的不是正常字符
>>> r.text
>>> type(r)
>>> r.headers #返回访问页面的头部信息抓取百度页面如下:
'\r\n 百度一下,你就知道 \r\n'
2.Requests库的get()方法
r=requests.get(url)get构造一个向服务器请求资源的Requst对象,返回一个包含服务器资源的Response对象。
Response对象包含服务器返回的所有信息,也包含请求的Request信息。
Response对象的属性如下:
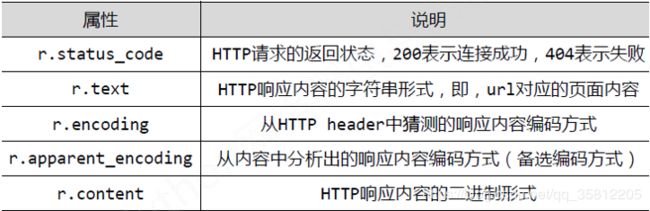
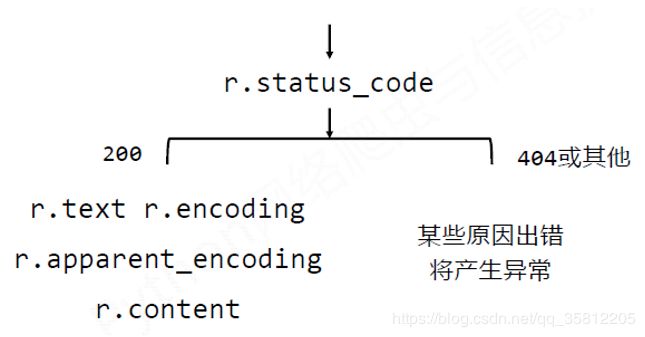
理解Response的编码:

3.爬取网页的通用代码框架
r=requests.get(url) ——> Exception

import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPEroor异常
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))4.HTTP协议及Requests库方法
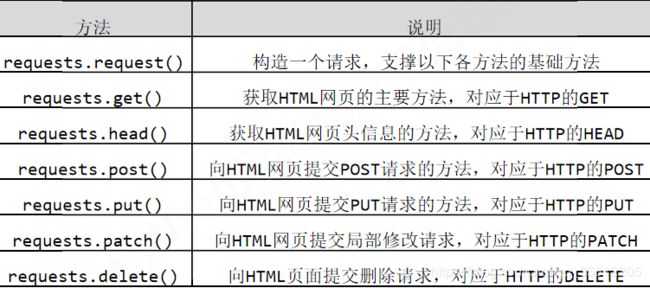
HTTP协议:超文本传输协议(Hypertext Transfer Protocol)
(1)一个基于“请求与相应”模式的、无状态的应用程序协议
(2)采用URL作为定位网络资源的标识
URL格式:http://host[:port][path]
(1)host:合法的Internet主机域名或IP地址
(2)port:端口号,缺省端口为80
(3)path:请求资源的路径
HTTP URL实例:http://www.bit.edu.cn http://220.181.111.188/duty
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。

向URL post一个字典,自动编码为form(表单):
>>> payload={'key1':'value1','key2':'value2'}
>>> r=requests.post('http://httpbin.org/post',data=payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e414584-e35045808901c5eac8b9fc33"
},
"json": null,
"origin": "36.102.20.87",
"url": "http://httpbin.org/post"
}向URL POST一个字符串,自动编码为data
>>> r=requests.post('http://httpbin.org/post',data='ABC')
>>> print(r.text)
{
"args": {},
"data": "ABC",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "3",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e41465a-9de2ad2889dcefa0c1e06558"
},
"json": null,
"origin": "36.102.20.47",
"url": "http://httpbin.org/post"
}put会覆盖掉原有的数据:
>>> payload={'key1':'value1','key2':'value2'}
>>> r=requests.put('http://httpbin.org/put',data=payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e414792-04e8b8901adfc57cbfd42f78"
},
"json": null,
"origin": "36.102.20.87",
"url": "http://httpbin.org/put"
}5.Requests库主要方法解析
>>> payload={'key1':'value1','key2':'value2'}
>>> r=requests.put('http://httpbin.org/put',data=payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5e414792-04e8b8901adfc57cbfd42f78"
},
"json": null,
"origin": "36.102.20.87",
"url": "http://httpbin.org/put"
}request方法
requests.request(method,url,**kwargs)
#method:请求方式,对应get/put/post等7种
#url:拟获取页面的url链接
#**kwargs:控制访问的参数,共13个6.Robots协议
Robosts网络爬虫排除协议 Robots Exclusion Standard
(1)形式:在网站根目录下的robots.txt文件,如京东的:http://www.jd.com/robots.txt
*代表所有 /代表根目录

(2)类人行为可不参考Robots协议