Flume 学习笔记 (一)
目录
一、Apache Flume
1. 概述
2. 运行机制
3. Flume 采集系统结构图
二、Flume 简单案例
1. 采集目录到HDFS
2. 采集文件到 HDFS
三、 Flume 的 load-balance、failover
Flume 的负载均衡:
Failover Sink Processor
四、Flume 拦截器实战案例
日志的采集和汇总(静态拦截器)
Flume 自定义拦截器
五、Flume 事务
六、Flume监控之ganglia
Ganglia的安装与部署
一、Apache Flume
1. 概述
Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到 指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前, 会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓 存的数据。

2. 运行机制

Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。
Sink:下沉目的地,采集数据的传送目的地,用于往下一级 agent 传递数据或者往 最终存储系统传递数据;
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
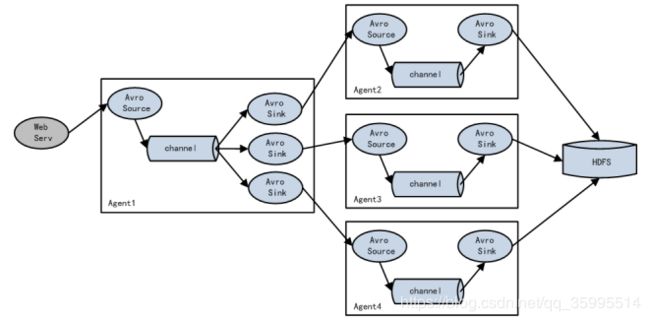
3. Flume 采集系统结构图
单个 agent 采集数据

复杂结构

配置文件说明(部分详解 ,round 、roll 三兄弟)
// <====================================================================================>
// Sink
// 是否开启 时间单位内的文件 舍弃
a1.sinks.k1.hdfs.round = true
// 每 10 分钟 形成 一个文件夹
a1.sinks.k1.hdfs.roundValue = 10
// 时间 单位为分钟
a1.sinks.k1.hdfs.roundUnit = minute
// 控制 HDFS 以何种方式 进行滚动,, 以时间间隔, 谁满足 谁 触发
a1.sinks.k1.hdfs.rollInterval = 3
// 以文件 大小
a1.sinks.k1.hdfs.rollSize = 20
// 以 event 个数
a1.sinks.k1.hdfs.rollCount = 5
// channel:缓冲区
// <=====================================================================================>
a1.channels.c1.type = memory
# 缓冲区中存留的最大event个数
a1.channels.c1.capacity = 1000
# channel从source中每个事务提取的最大event数
# channel发送给sink每个事务发送的最大event数
a1.channels.c1.transactionCapacity = 100二、Flume 简单案例
1. 采集目录到HDFS
采集需求: 服务器的某特定目录下,会不断产生新的文件,每当有新文件出现, 就需要把文件采集到 HDFS 中去
- 采集源,即 source——监控文件目录 : spooldir
- 下沉目标,即 sink——HDFS 文件系统 : hdfs sink
- source 和 sink 之间的传递通道——channel,可用 file channel 也可以用 内存 channel
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/logs1
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = kangna-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 3
a1.sinks.k1.hdfs.rollSize = 20
a1.sinks.k1.hdfs.rollCount = 5
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动
bin/flume-ng agent -c ./conf -f ./conf/spool-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
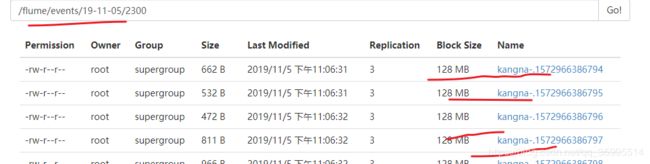
然后在监控的文件夹下 创建文件夹 /root/logs1 ,往 logs1 下 添加文件
![]()
采集到HDFS 中的 日志文件
2. 采集文件到 HDFS
采集需求: 比如业务系统使用 log4j 生成的日志,日志内容不断增加,需要把追 加到日志文件中的数据实时采集到 hdfs
- 采集源,即 source——监控文件内容更新 : exec ‘tail -F file’
- 下沉目标,即 sink——HDFS 文件系统 : hdfs sink
- Source 和 sink 之间的传递通道——channel,可用 file channel 也可以用 内存 channel
As a for instance, one of the most commonly requested features is the tail -F [file]-like use case where an application writes to a log file on disk and Flume tails the file, sending each line as an event. For stronger reliability guarantees, consider the Spooling Directory Source, Taildir Source or direct integration with Flume via the SDK.
tail-hdfs.conf 配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/test.log
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H-%M/
a1.sinks.k1.hdfs.filePrefix = kangna-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
写一个死循环 ,模拟一个 数据动态变化
while true; do date >> /root/logs/test.log;done![]()
其中 10 秒产生一个文件。
三、 Flume 的 load-balance、failover
负载均衡是用于解决一台机器(一个进程)无法解决所有请求而产生的一种 算法。 Load balancing Sink Processor 能够实现 load balance 功能
Flume 的负载均衡:
- 解决一个进程或程序处理不了所有请求,多个进程一起处理
- 同一个请求 不能交给多个进程处理避免数据重复
- 涉及到任务的分配 :一是轮询(round_robin ),二是随机(random )
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /root/logs/123.log
# set sink1 两个 sink avro 协议解决跨网络传输数据
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node02
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = node03
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = load_balance
agent1.sinkgroups.g1.processor.backoff = true
agent1.sinkgroups.g1.processor.selector = round_robin
agent1.sinkgroups.g1.processor.selector.maxTimeOut=10000avro-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
# 与agent 相同 信息 本机 端口
a1.sources.r1.bind = node02
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1avro-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node03
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1



Failover Sink Processor
Failover Sink Processor 能够实现 failover 功能,具体流程类似 load balance,但是内部处理机制与 load balance 完全不同Failover Sink Processor 维护一个优先级 Sink 组件列表,只要有一个 Sink 组件可用,Event 就被传递到下一个组件。故障转移机制的作用是将失败的 Sink 降级到一个池,在这些池中它们被分配一个冷却时间,随着故障的连续,在重试 之前冷却时间增加(缓刑---> 死刑)。一旦 Sink 成功发送一个事件,它将恢复到活动池。 Sink 具 有与之相关的优先级,数量越大,优先级越高。



四、Flume 拦截器实战案例
日志的采集和汇总(静态拦截器)
A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、web.log
在 hdfs 中要求的目录为:
/source/logs/access/20191108/**
/source/logs/nginx/20191108/**
/source/logs/web/20191108/**数据流程处理分析
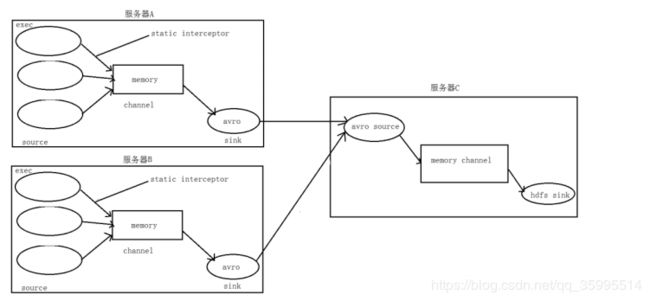
定义exec_source_avro_sink.conf
ll# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# Describe/configure the source 静态 拦截器,
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/logs/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/logs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/logs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node02
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 2000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
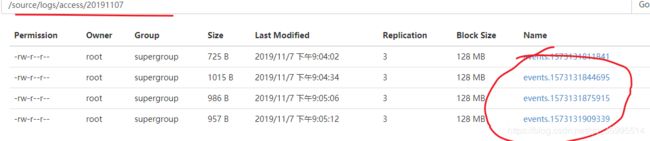
a1.sinks.k1.channel = c1定义 avro_source_hdfs_sink.conf
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
i
#定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = node02
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 200
a1.channels.c1.transactionCapacity = 100
#定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://node01:8020/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
#a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件不按时间生成
a1.sinks# .k1.hdfs.rollInterval = 20
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 20
flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

Flume 自定义拦截器
Flume 有各种自带的拦截器,比如:TimestampInterceptor、 HostInterceptor、RegexExtractorInterceptor 等,通过使用不同的拦截器, 实现不同的功能。 但是以上的这些拦截器,不能改变原有日志数据的内容或者对 日志信息添加一定的处理逻辑,当一条日志信息有几十个甚至上百个字段的时候, 在传统的 Flume 处理下,收集到的日志还是会有对应这么多的字段,也不能对你 想要的字段进行对应的处理。
根据实际业务的需求,为了更好的满足数据在应用层的处理,通过自定义 Flume 拦截器,过滤掉不需要的字段,并对指定字段加密处理,将源数据进行预 处理。减少了数据的传输量,降低了存储的开销。
- 定义一个类 CustomParameterInterceptor 实现 Interceptor 接口。
- 在 CustomParameterInterceptor 类中定义变量,这些变量是需要到 Flume 的配置文件中进行配置使用的。每一行字段间的分隔符 (fields_separator)、通过分隔符分隔后,所需要列字段的下标 (indexs)、多个下标使用的分隔符(indexs_separator)、多个下标使用 的分隔符(indexs_separator)。
- 添加 CustomParameterInterceptor 的有参构造方法。并对相应的变量进行 处理。将配置文件中传过来的 unicode 编码进行转换为字符串。
- 写具体的要处理的逻辑 intercept()方法,一个是单个处理的,一个是批量 处理。
- 接口中定义了一个内部接口 Builder,在 configure 方法中,进行一些参数 配置。并给出,在 flume 的 conf 中没配置一些参数时,给出其默认值。通 过其 builder 方法,返回一个 CustomParameterInterceptor 对象。
- 定义一个静态类,类中封装 MD5 加密方法
- 通过以上步骤,自定义拦截器的代码开发已完成,然后打包成 jar, 放到 Flume 的根目录下的 lib 目录中
定义类 CustomParameterInterceptor
package com.kangna.interceptor;
import com.google.common.base.Charsets;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import static com.kangna.interceptor.CustomParameterInterceptor.Constants.*;
/********************************
* @Author: kangna
* @Date: 2019/11/6 0:08
* @Version: 1.0
* @Desc:
********************************/
public class CustomParameterInterceptor implements Interceptor {
/** The field_separator.指明每一行字段的分隔符 */
private final String fields_separator;
/** The indexs.通过分隔符分割后,指明需要那列的字段 下标*/
private final String indexs;
/** The indexs_separator. 多个下标的分隔符*/
private final String indexs_separator;
/** The encrypted_field_index. 需要加密的字段下标*/
private final String encrypted_field_index;
/**
* 3. 通过 CustomParameterInterceptor 的构造器 获取配置文件中的参数
*/
public CustomParameterInterceptor(String fields_separator, String indexs,
String indexs_separator, String encrypted_field_index) {
String f = fields_separator.trim();
String i = indexs_separator.trim();
this.indexs = indexs;
this.encrypted_field_index = encrypted_field_index.trim();
if (!f.equals("")) {
f = UnicodeToString(f);
}
this.fields_separator =f;
if (!i.equals("")) {
i = UnicodeToString(i);
}
this.indexs_separator = i;
}
/*
*
* \t 制表符 ('\u0009')
*
*/
public static String UnicodeToString(String str) {
Pattern pattern = Pattern.compile("(\\\\u(\\p{XDigit}{4}))");
Matcher matcher = pattern.matcher(str);
char ch;
while (matcher.find()) {
ch = (char) Integer.parseInt(matcher.group(2), 16);
str = str.replace(matcher.group(1), ch + "");
}
return str;
}
public static class Builder implements Interceptor.Builder {
// 每一个字段的之间的分隔符
private String fields_separator;
// 指定需要的字段 索引,不需要的 字段 可以舍弃
private String indexs;
// 指定 字段索引的 之间的 分隔符
private String indexs_separator;
// 需要加密的 字段 下标
private String encrypted_field_index;
/**
* 将 配置的 解析后 参数 通过 参数 传递给自定义的 实例对象
* @return
*/
@Override
public Interceptor build() {
return new CustomParameterInterceptor(fields_separator, indexs, indexs_separator, encrypted_field_index);
}
/**
* 通过 flume context 上下文环境变量读取采集方案中的配置的属性, 如果没有配置 则 使用默认值
* @param context
*/
@Override
public void configure(Context context) {
fields_separator = context.getString(FIELD_SEPARATOR, DEFAULT_FIELD_SEPARATOR);
indexs = context.getString(INDEXS, DEFAULT_INDEXS);
indexs_separator = context.getString(INDEXS_SEPARATOR, DEFAULT_INDEXS_SEPARATOR);
encrypted_field_index = context.getString(ENCRYPTED_FIELD_INDEX, DEFAULT_ENCRYPTED_FIELD_INDEX);
}
}
@Override
public void initialize() {
}
/**
* 自定义拦截器的具体功能实现
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
if (event == null) {
return null;
}
try {
String line = new String(event.getBody(), Charsets.UTF_8);
String[] fields_splits = line.split(fields_separator);
String[] indexs_split = indexs.split(indexs_separator);
String newLine = "";
for (int i = 0; i < indexs_split.length; i++) {
int paseInt = Integer.parseInt(indexs_split[i]);
// 匹配到加密字段, 对加密字段进行加密
if (!"".equals(encrypted_field_index) && encrypted_field_index.equals(indexs_split[i])) {
// 拿到 加密的 字段 进行加密
newLine += StringUtils.GetMD5Code(fields_splits[paseInt]);
} else {
// 如果是 不需要加密的字段
newLine += fields_splits[paseInt];
}
// 遍历 如果不是 最后一个字段 就拼接分隔符
if (i!= fields_splits.length -1) {
newLine += fields_separator;
}
}
event.setBody(newLine.getBytes(Charsets.UTF_8));
return event;
} catch (Exception e) {
return event;
}
}
@Override
public List intercept(List events) {
List out = new ArrayList<>();
for (Event event : events) {
Event outEvent = intercept(event);
if (outEvent != null) {
out.add(outEvent);
}
}
return out;
}
@Override
public void close() {
}
public static class Constants {
/** The Constant FIELD_SEPARATOR. */
public static final String FIELD_SEPARATOR = "fields_separator";
/** The Constant DEFAULT_FIELD_SEPARATOR. */
public static final String DEFAULT_FIELD_SEPARATOR =" ";
/** The Constant INDEXS. */
public static final String INDEXS = "indexs";
/** The Constant DEFAULT_INDEXS. */
public static final String DEFAULT_INDEXS = "0";
/** The Constant INDEXS_SEPARATOR. */
public static final String INDEXS_SEPARATOR = "indexs_separator";
/** The Constant DEFAULT_INDEXS_SEPARATOR. */
public static final String DEFAULT_INDEXS_SEPARATOR = ",";
/** The Constant ENCRYPTED_FIELD_INDEX. */
public static final String ENCRYPTED_FIELD_INDEX = "encrypted_field_index";
/** The Constant DEFAUL_TENCRYPTED_FIELD_INDEX. */
public static final String DEFAULT_ENCRYPTED_FIELD_INDEX = "";
/** The Constant PROCESSTIME. */
public static final String PROCESSTIME = "processTime";
/** The Constant PROCESSTIME. */
public static final String DEFAULT_PROCESSTIME = "a";
}
/**
* 字符串md5加密
*/
public static class StringUtils {
// 全局数组
private final static String[] strDigits = { "0", "1", "2", "3", "4", "5",
"6", "7", "8", "9", "a", "b", "c", "d", "e", "f" };
// 返回形式为数字跟字符串
private static String byteToArrayString(byte bByte) {
int iRet = bByte;
// System.out.println("iRet="+iRet);
if (iRet < 0) {
iRet += 256;
}
int iD1 = iRet / 16;
int iD2 = iRet % 16;
return strDigits[iD1] + strDigits[iD2];
}
// 返回形式只为数字
private static String byteToNum(byte bByte) {
int iRet = bByte;
System.out.println("iRet1=" + iRet);
if (iRet < 0) {
iRet += 256;
}
return String.valueOf(iRet);
}
// 转换字节数组为16进制字串
private static String byteToString(byte[] bByte) {
StringBuffer sBuffer = new StringBuffer();
for (int i = 0; i < bByte.length; i++) {
sBuffer.append(byteToArrayString(bByte[i]));
}
return sBuffer.toString();
}
public static String GetMD5Code(String strObj) {
String resultString = null;
try {
resultString = new String(strObj);
MessageDigest md = MessageDigest.getInstance("MD5");
// md.digest() 该函数返回值为存放哈希值结果的byte数组
resultString = byteToString(md.digest(strObj.getBytes()));
} catch (NoSuchAlgorithmException ex) {
ex.printStackTrace();
}
return resultString;
}
}
}
// 定义两个拦截器
a1.sources.r1.interceptors =i1 i2
// 拦截器 的自定义实现
a1.sources.r1.interceptors.i1.type =com.kangna.interceptor.CustomParameterInterceptor$Builder
// 以参数的形式 进行 相应的配置 可以 舍弃某些 数据, 拦截器在中获取这些value 值 做具体处理
// 字段分隔符
a1.sources.r1.interceptors.i1.fields_separator=\\u0009
// 保留 那些数据
a1.sources.r1.interceptors.i1.indexs =0,1,3,5,6
// 保留字段的分隔符
a1.sources.r1.interceptors.i1.indexs_separator =\\u002c
// 加密字段 索引 为 0
a1.sources.r1.interceptors.i1.encrypted_field_index =0
a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder


五、Flume 事务
前面说 数据传输分为 三大步骤,但是具体细分 还可以拆,flume 是传输数据的,所以得考虑到数据传输时数据的完整性 . Flume在传输数据的时候很有可能因为传输速率的不一致导致channel满了,从而导致数据丢失。
channel是被动的,source这边是主动把数据 put 给 channel,sink 这边是主动把数据从 channel 拉取 take,所以 channel 是被动操作的。
一般channel使用MemoryChannel,基于内存的,断电会丢失数据,也可以使用filechannel(磁盘),filechannel速度慢,但有提供日志级别的数据恢复功能,不过不断电MemoryChannel是不会丢数据的,所以一般选用memorychannel 也 OK(量大丢点没关系)。
source把数据传给channel 时不是直接传给channel,中间还有put事务,当然从channel到sink也不是直接传过去的,中间还有take事务。
put事务步骤:
- doput :先将批数据写入临时缓冲区putlist里面
- docommit:去检查channel里面有没有空位置,如果有就传入数据,如果没有那么dorollback就把数据回滚到putlist里面。
take事务步骤:
- dotake:将数据读取到临时缓冲区takelist,并将数据传到hdfs上。
- docommit :去判断数据发送是否成功,若成功那么清除临时缓冲区takelist
若不成功(比如hdfs系统服务器崩溃等)那么dorollback将数据回滚到channel里面。
数据在传输到下个节点时(一般是批量数据),假设接收节点出现异常,比方网络异常。则回滚这一批数据,因此有可能导致数据重发(是重发不是重复)。
同个节点内,Source写入数据到Channel,数据在一个批次内的数据出现异常,则不写入到Channel,已接收到的部分数据直接抛弃,靠上一个节点重发数据。
通过这两个事务,Flume提高了数据传输的完整性,准确性。(原文链接https://blog.csdn.net/Nurbiya_K/article/details/100391740)
Event数据结构
public interface Event {
/**
* Returns a map of name-value pairs describing the data stored in the body.
*/
public Map getHeaders();
/**
* Set the event headers
* @param headers Map of headers to replace the current headers.
*/
public void setHeaders(Map headers);
/**
* Returns the raw byte array of the data contained in this event.
*/
public byte[] getBody();
/**
* Sets the raw byte array of the data contained in this event.
* @param body The data.
*/
public void setBody(byte[] body);
} header是一个map,body是一个字节数组,body才是我们实际使用中真正传输的数据,header传输的数据,我们是不会sink出去的。在source端产出event的时候,通过header去区别对待不同的event,然后在sink端的时候,我们就可以通过header中的key来将不同的event输出到对应的sink下游去(比如kafka),这样就将event分流出去了。
这个场景 就是 使用了拦截器,我们 用了 两个拦截器(数据进过简单过滤),使用了两个 channel(c1、c2) ,通过 header ,将 event 放到不同的 channel 再sink到 不同机器 的 kafka
示例如下: 通过 logType
# selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = logType
a1.sources.r1.selector.mapping.start = c1
a1.sources.r1.selector.mapping.event = c2
// 2. 区分 日志
if (json.contains("start")) {
// 启动日志 ,value
logType = "start";
} else {
// 其它 11种 事件的日志 ,value
logType = "event";
}
Map headers = event.getHeaders();
headers.put("logType", logType);
return event;

六、Flume监控之ganglia
Ganglia的安装与部署
// 安装httpd服务与php
yum -y install httpd php
yum -y install rrdtool perl-rrdtool rrdtool-devel
yum -y install apr-devel
// 安装ganglia
rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
yum -y install ganglia-gmetad
yum -y install ganglia-web
yum install -y ganglia-gmond修改配置文件/etc/httpd/conf.d/ganglia.conf vim /etc/httpd/conf.d/ganglia.conf
# Ganglia monitoring system php web frontend
Alias /ganglia /usr/share/ganglia
Order deny,allow
Deny from all
Allow from all
# Allow from 127.0.0.1
# Allow from ::1
# Allow from .example.com
修改配置文件/etc/ganglia/gmetad.conf vim /etc/ganglia/gmetad.con
data_source "hadoop102" 192.168.1.102修改配置文件/etc/ganglia/gmond.conf
修改为:
cluster {
name = "hadoop102" ######
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
# mcast_join = 239.2.11.71
host = 192.168.1.102 ########
port = 8649 ########
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
bind = 192.168.1.102 ###########
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics 修改配置文件/etc/selinux/config
vim /etc/selinux/config
修改为: 之前大家应该 都有改的
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted启动ganglia
service httpd start
service gmetad start
service gmond start打开网页浏览ganglia页面
http://node01/ganglia
果完成以上操作依然出现权限不足错误,请修改/var/lib/ganglia目录的权限:
chmod -R 777 /var/lib/ganglia操作Flume测试监控传递
修改flume/conf目录下的flume-env.sh配置:
JAVA_OPTS="-Dflume.monitoring.type=ganglia
-Dflume.monitoring.hosts=192.168.100.10:8649
-Xms100m
-Xmx200m"图例说明:
| 字段(图表名称) |
字段含义 |
| EventPutAttemptCount |
source尝试写入channel的事件总数量 |
| EventPutSuccessCount |
成功写入channel且提交的事件总数量 |
| EventTakeAttemptCount |
sink尝试从channel拉取事件的总数量。这不意味着每次事件都被返回,因为sink拉取的时候channel可能没有任何数据。 |
| EventTakeSuccessCount |
sink成功读取的事件的总数量 |
| StartTime |
channel启动的时间(毫秒) |
| StopTime |
channel停止的时间(毫秒) |
| ChannelSize |
目前channel中事件的总数量 |
| ChannelFillPercentage |
channel占用百分比 |
| ChannelCapacity |
channel的容量 |
至此 Flume 常见的 使用 场景 算是入门了。