pytorch——用resnet18做动物多分类问题(含可视化结果)
代码以及数据集下载:https://github.com/duchp/python-all/tree/master/CV%20code/动物多分类项目
一、任务介绍
- 纲分类问题,预测该动物是属于哺乳纲(Mammals)还是鸟纲(Birds)
- 种分类问题,预测该动物是兔子、老鼠还是鸡
- 多任务分类问题,同时预测动物的“纲”和“种”
二、数据预处理
使用的数据集结构如下:
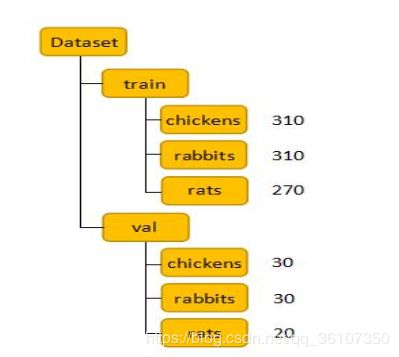
上图为文件夹数据结构,同时,我们对于每一个任务,都有两个.csv文件,用于存储对应的训练数据与测试数据的标签。
训练的第一步是将数据存为pytorch里面的Dataset类,便于后续处理和读取数据。
因为三个任务的数据一致,不同的是标签情况,在代码上差异不大,所以以第一个任务——纲分类为例,数据存为Dataset类的代码及注释如下:
class MyDataset(torch.utils.data.Dataset):
def __init__(self,root,transform=None):
super(MyDataset,self).__init__()
#读取csv文件
file_info = pd.read_csv(root, index_col=0)
#读取图像路径
file_path = file_info['path']
#读取图像纲分类标签
file_class = file_info['classes']
imgs = []
imglb = []
#依次处理数据
for i in range(len(file_path)):
path = file_path[i]
path = path.replace('\\','/')
if not os.path.isfile(path):
print(path + ' does not exist!')
return None
#读对应路径的图像,存为img,依次存入imgs
img = Image.open(path).convert('RGB')
imgs.append(img)
#读对应图像的标签,依次存入imglb
imglb.append(int(file_class[i]))
self.image = imgs
self.imglb = imglb
self.root = root
self.size = len(file_info)
self.transform = transform
def __getitem__(self,index):
img = self.image[index]
label = self.imglb[index]
sample = {'image': img,'classes':label}
if self.transform:
sample['image'] = self.transform(img)
return sample
def __len__(self):
return self.size
存好数据后,开始为训练网络做准备,在深度学习训练中,一般会对数据进行一些变换,比如:翻转,旋转等等,用来增强鲁棒性,因此,这里需要定义一个数据变换函数:
train_transforms = transforms.Compose([transforms.Resize((500, 500)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
val_transforms = transforms.Compose([transforms.Resize((500, 500)),
transforms.ToTensor()
])
这里我们只做了训练图像的resize和随机水平翻转变换,实际上图像变换还有很多选择,具体可查询torchvision.transforms.Compose这个函数的参数设置。这个设定是要赋值到上面的MyDataset里面的,可以看到上面的transform默认为None,如果不赋值,则不做变换。
到了这一步,我们的数据还需要一个非常重要的处理,那就是分batch,因为如果一次性把数据放入训练中,往往内存是不够的,如果一张一张的训练,每次修正方向以各自样本的梯度方向修正,难以达到收敛。因此需要设置合理的batch size(这里设为64)。调用上述所有函数,代码如下:
TRAIN_ANNO = 'Classes_train_annotation.csv'
VAL_ANNO = 'Classes_val_annotation.csv'
CLASSES = ['Mammals', 'Birds']
train_dataset = MyDataset(root = TRAIN_ANNO,transform = train_transforms)
test_dataset = MyDataset(root = VAL_ANNO,transform = val_transforms)
#设置batch size = 64
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset)
data_loaders = {'train': train_loader, 'val': test_loader}
则最终所用的数据为data_loaders,包含了train_loader和test_loader。
三、网络结构
采用经典的resnet18网络进行分类任务的训练,代码如下:(以第一个任务为例)
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes,
kernel_size = 3,stride = stride,
padding = 1, bias = False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride = 1, downsample = None):
super(BasicBlock,self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace = True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes = 2):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3, bias = False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace = True)
self.maxpool = nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 0, ceil_mode = True)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride = 2)
self.layer3 = self._make_layer(block, 256, layers[2], stride = 2)
self.layer4 = self._make_layer(block, 512, layers[3], stride = 2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion * 4, num_classes)
for m in self.modules():
if isinstance(m,nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0,math.sqrt(2./n))
elif isinstance(m,nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride = 1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size = 1, stride = stride, bias = False),
nn. BatchNorm2d(planes * block.expansion)
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet18(pretrained = False):
model = ResNet(BasicBlock,[2,2,2,2])
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
调用网络:
net = resnet18()
需要注意的是,第一个任务是一个二分类问题,所以num_class设为默认的2,但是对第二类问题,它是多分类问题,num_class不能取默认数值,应赋值为3,对于第三类问题,因为需要同时预测“纲”和“种”,因此,最后一层为两个全连接层,一个负责“纲”的分类,一个负责“种”的分类,固需要设置两个参数:num_classes和num_species,这里他们分别为2和3。
四、训练及测试函数介绍
下面以最复杂的第三类问题的训练测试函数为例,代码及注释如下:
def train_model(model, criterion, optimizer, scheduler, num_epochs=50):
Loss_list = {'train': [], 'val': []}
Accuracy_list_species = {'train': [], 'val': []}
Accuracy_list_classes = {'train': [], 'val': []}
best_model_wts = copy.deepcopy(model.state_dict())
best_class_acc = 0.0
best_specy_acc = 0.0
best_acc = 0.0
best_loss = 10000
#epoch循环训练
for epoch in range(num_epochs):
print('epoch {}/{}'.format(epoch,num_epochs - 1))
print('-*' * 10)
# 每个epoch都有train(训练)和val(测试)两个阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
corrects_classes = 0
corrects_species = 0
for idx,data in enumerate(data_loaders[phase]):
#将数据存在gpu上
inputs = Variable(data['image'].cuda())
labels_classes = Variable(data['classes'].cuda())
labels_species = Variable(data['species'].cuda())
optimizer.zero_grad()
#训练阶段
with torch.set_grad_enabled(phase == 'train'):
x_classes,x_species = model(inputs)
_, preds_classes = torch.max(x_classes, 1)
_, preds_species = torch.max(x_species, 1)
#计算训练误差
loss = (criterion(x_species, labels_species)+criterion(x_classes, labels_classes))/2
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
corrects_classes += torch.sum(preds_classes == labels_classes)
corrects_species += torch.sum(preds_species == labels_species)
epoch_loss = running_loss / len(data_loaders[phase].dataset)
Loss_list[phase].append(epoch_loss)
epoch_acc_classes = corrects_classes.double() / len(data_loaders[phase].dataset)
epoch_acc_species = corrects_species.double() / len(data_loaders[phase].dataset)
Accuracy_list_classes[phase].append(100 * epoch_acc_classes)
Accuracy_list_species[phase].append(100 * epoch_acc_species)
print('{} Loss: {:.4f} Acc_classes: {:.2%} Acc_species: {:.2%}'
.format(phase, epoch_loss,epoch_acc_classes,epoch_acc_species))
#测试阶段
if phase == 'val':
#如果当前epoch下的准确率总体提高或者误差下降,则认为当下的模型最优
if epoch_acc_classes + epoch_acc_species > best_acc or epoch_loss < best_loss:
best_acc_classes = epoch_acc_classes
best_acc_species = epoch_acc_species
best_acc = best_acc_classes + best_acc_species
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
print('Best_model: classes Acc: {:.2%}, species Acc: {:.2%}'
.format(best_acc_classes,best_acc_species))
model.load_state_dict(best_model_wts)
torch.save(model.state_dict(), 'best_model.pt')
print('Best_model: classes Acc: {:.2%}, species Acc: {:.2%}'
.format(best_acc_classes,best_acc_species))
return model, Loss_list,Accuracy_list_classes,Accuracy_list_species
函数定义好后,设置参数并调用:
network = net.cuda()
optimizer = torch.optim.SGD(network.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1) # Decay LR by a factor of 0.1 every 1 epochs
model, Loss_list, Accuracy_list_classes, Accuracy_list_species = train_model(network, criterion, optimizer, exp_lr_scheduler, num_epochs=100)
则会出现下面的输出界面(截取部分片段):

五、结果可视化
根据上述第四步函数,我们可以得到Loss_list, Accuracy_list_classes, Accuracy_list_species,那么为了更方便的观察模型的训练过程,可以将它可视化,使用matplotlib即可:
x = range(0, 100)
y1 = Loss_list["val"]
y2 = Loss_list["train"]
plt.figure(figsize=(18,14))
plt.subplot(211)
plt.plot(x, y1, color="r", linestyle="-", marker="o", linewidth=1, label="val")
plt.plot(x, y2, color="b", linestyle="-", marker="o", linewidth=1, label="train")
plt.legend()
plt.title('train and val loss vs. epoches')
plt.ylabel('loss')
plt.subplot(212)
y3 = Accuracy_list_classes["train"]
y4 = Accuracy_list_classes["val"]
y5 = Accuracy_list_species["train"]
y6 = Accuracy_list_species["val"]
plt.plot(x, y3, color="y", linestyle="-", marker=".", linewidth=1, label="train_class")
plt.plot(x, y4, color="g", linestyle="-", marker=".", linewidth=1, label="val_class")
plt.plot(x, y5, color="r", linestyle="-", marker=".", linewidth=1, label="train_specy")
plt.plot(x, y6, color="b", linestyle="-", marker=".", linewidth=1, label="val_specy")
plt.legend()
plt.title('train and val classes_acc & Species_acc vs. epoches')
plt.ylabel('accuracy')
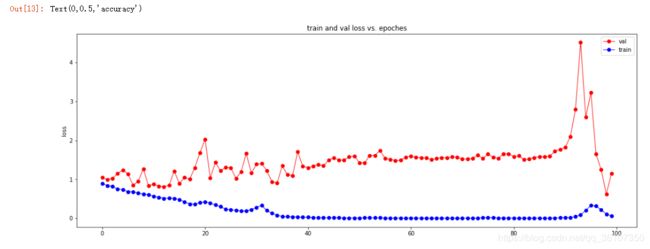
则可得到下面两张图:
loss:
accuracy:
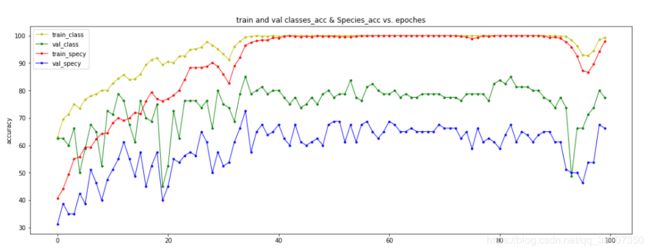
我们可以从这样的图大致走向判断模型训练的一个稳定性过程。
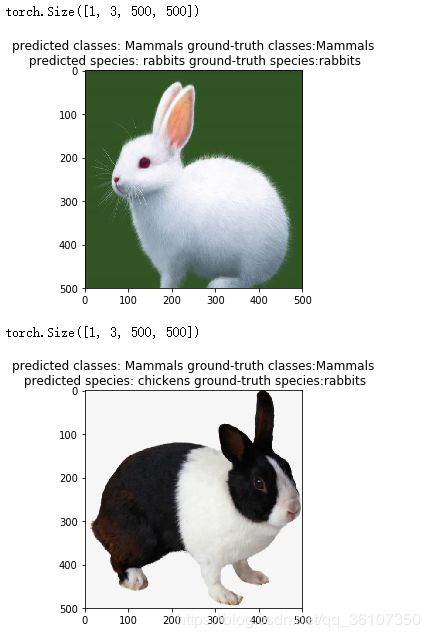
另外,还有一种可视化方法,将图片以及图片的标签和预测结果直接打印出来:
def visualize_model(model):
model.eval()
with torch.no_grad():
for i, data in enumerate(data_loaders['val']):
inputs = data['image']
labels_classes = Variable(data['classes'].cuda())
labels_species = Variable(data['species'].cuda())
x_classes,x_species = model(Variable(inputs.cuda()))
x_classes=x_classes.view(-1,2)
_, preds_classes = torch.max(x_classes, 1)
x_species=x_species.view(-1,3)
_, preds_species = torch.max(x_species, 1)
print(inputs.shape)
plt.imshow(transforms.ToPILImage()(inputs.squeeze(0)))
plt.title('predicted classes: {} ground-truth classes:{}\n predicted species: {} ground-truth species:{}'.format(CLASSES[preds_classes],CLASSES[labels_classes],SPECIES[preds_species],SPECIES[labels_species]))
plt.show()
调用:
visualize_model(model)
结果如下(截取片段):