用Pandas在Python中可视化机器学习数据
https://machinelearningmastery.com/visualize-machine-learning-data-python-pandas/
用Pandas在Python中可视化机器学习数据
作者 Jason Brownlee 于 2016 年5月16日在 Python机器学习
您必须了解您的数据才能从机器学习算法中获得最佳结果。
了解更多有关数据的最快方法是使用数据可视化。
在这篇文章中,您将会发现如何使用Pandas在Python中可视化您的机器学习数据。
让我们开始吧。
- 更新March / 2018:添加备用链接以下载数据集,因为原始文件似乎已被删除。
在Python随着熊猫可视化机器学习资料
图片由亚历克斯·奇克,保留某些权利。
关于食谱
本文中的每个配方都是完整且独立的,因此您可以将其复制并粘贴到您自己的项目中并立即使用。
该皮马印第安人数据集用于演示每个小区(更新:从这里下载)。该数据集描述皮马印第安人的医疗记录,以及每位患者是否在五年内发生糖尿病。因此这是一个分类问题。
这是一个很好的演示数据集,因为所有的输入属性都是数字的,并且要预测的输出变量是二进制(0或1)。
这些数据可以从UCI机器学习库中免费获得,并作为每个配方的一部分直接下载
单变量情节
在本节中,我们将看看可以用来独立理解每个属性的技术。
直方图
了解每个属性分布的一种快速方法是查看直方图。
直方图将数据分组为数据,并为您提供每个分箱中观察次数的计数。从箱子的形状,你可以很快得到一个属性是否是高斯的感觉,倾斜或甚至具有指数分布。它还可以帮助您查看可能的异常值。
| 1 2 3 4 5 6 7 8 |
# Univariate Histograms import matplotlib.pyplot as plt import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) data.hist() plt.show() |
我们可以看到,也许属性年龄,pedi和测试可能有指数分布。我们也可以看到,mass或pres和plas属性可能具有高斯或接近高斯分布。这很有趣,因为许多机器学习技术假设输入变量具有高斯单变量分布。
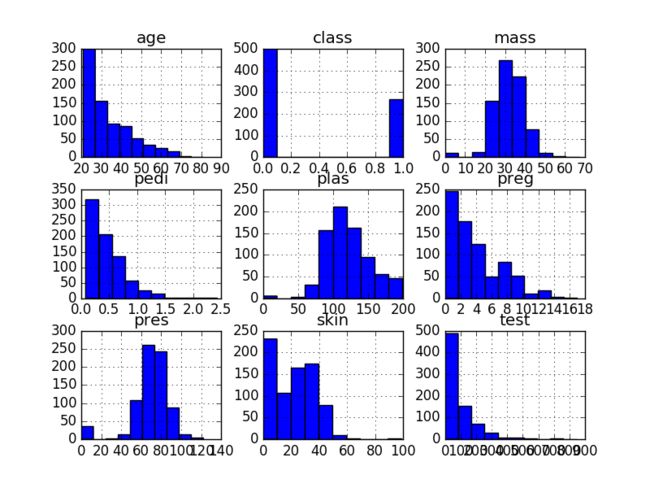
单变量直方图
密度图
密度图是快速了解每个属性分布情况的另一种方式。这些图像看起来像是一个抽象的直方图,在每个bin的顶部绘制了一条平滑的曲线,就像您的眼睛试图处理直方图一样。
| 1 2 3 4 5 6 7 8 |
# Univariate Density Plots import matplotlib.pyplot as plt import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) data.plot(kind='density', subplots=True, layout=(3,3), sharex=False) plt.show() |
我们可以看到每个属性的分布比直方图更清晰。
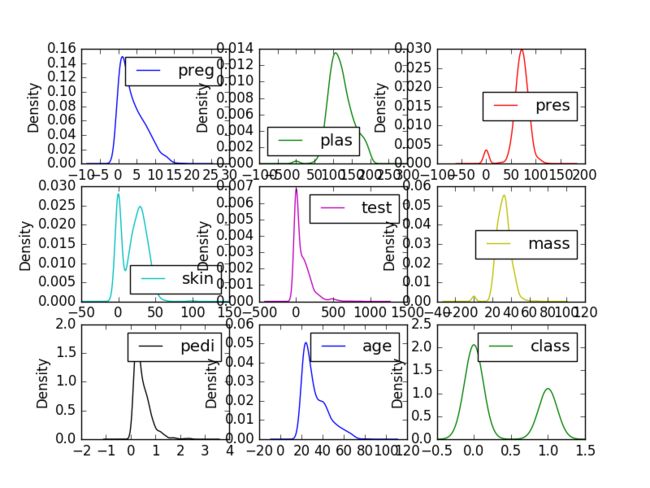
单变量密度图
盒和晶须情节
查看每个属性分布的另一种有用方法是使用Box和Whisker Plots或简称盒形图。
Boxlotots总结每个属性的分布,为中值(中间值)绘制一条线,并在第25和第75百分位(中间数据的50%)附近画一个框。晶须表明数据的扩散以及晶须外部的点显示候选离群值(数值比中间50%数据的扩散大小大1.5倍)。
| 1 2 3 4 5 6 7 8 |
# Box and Whisker Plots import matplotlib.pyplot as plt import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) data.plot(kind='box', subplots=True, layout=(3,3), sharex=False, sharey=False) plt.show() |
我们可以看到属性的传播是完全不同的。一些像年龄,测试和皮肤似乎倾向于较小的值。

单变量盒和晶须图
多变量图
本部分显示了多个变量之间交互作用的示例。
相关矩阵图
相关性表明两个变量之间的变化是如何相关的。如果两个变量在相同方向上变化,则它们是正相关的。如果相反的方向一起变化(一个上升,一个下降),则它们是负相关的。
您可以计算每对属性之间的相关性。这被称为相关矩阵。然后,您可以绘制相关矩阵,并了解哪些变量彼此具有高度相关性。
这一点很有用,因为如果数据中存在高度相关的输入变量,那么线性和逻辑回归等一些机器学习算法的性能可能会很差。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Correction Matrix Plot import matplotlib.pyplot as plt import pandas import numpy url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) correlations = data.corr() # plot correlation matrix fig = plt.figure() ax = fig.add_subplot(111) cax = ax.matshow(correlations, vmin=-1, vmax=1) fig.colorbar(cax) ticks = numpy.arange(0,9,1) ax.set_xticks(ticks) ax.set_yticks(ticks) ax.set_xticklabels(names) ax.set_yticklabels(names) plt.show() |
我们可以看到矩阵是对称的,即矩阵的左下角与右上角相同。这很有用,因为我们可以在一个图中看到两个不同的视图。我们还可以看到,每个变量在从左上角到右下角的对角线上彼此完全正相关(如您所期望的那样)。
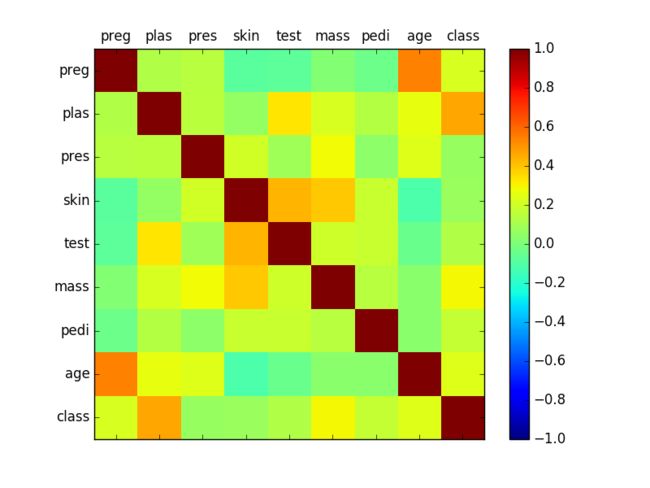
相关矩阵图
散点图矩阵
散点图将两个变量之间的关系显示为二维点,每个属性的一个轴。您可以为数据中的每对属性创建散点图。一起绘制所有这些散点图被称为散点图矩阵。
散点图对于发现变量之间的结构关系非常有用,例如您是否可以用一行来总结两个变量之间的关系。具有结构化关系的属性也可能是相关的,并且可以从数据集中移除。
| 1 2 3 4 5 6 7 8 9 |
# Scatterplot Matrix import matplotlib.pyplot as plt import pandas from pandas.plotting import scatter_matrix url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) scatter_matrix(data) plt.show() |
像相关矩阵图一样,散点图矩阵是对称的。从不同的角度来看这对成对的关系是很有用的。由于每个变量的自身散点图都没有绘制点,所以对角线显示了每个属性的直方图。
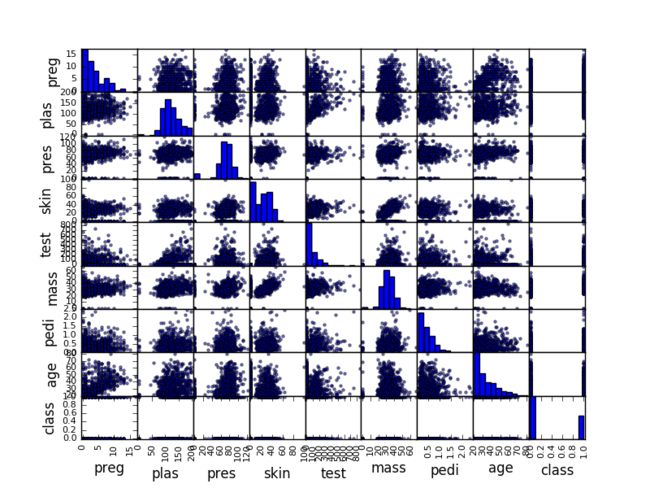
散点图矩阵
概要
在这篇文章中,您发现了许多方法,可以使用Pandas更好地理解Python中的机器学习数据。
具体而言,您学习了如何使用以下方式绘制数据:
- 直方图
- 密度图
- 盒和晶须情节
- 相关矩阵图
- 散点图矩阵
打开你的Python交互式环境并尝试每个配方。