数据挖掘十大算法(八):k-邻近算法(KNN)python和sklearn实现
《机器学习实战》,为了更深的理解经典的数据挖掘算法,我开始了这本书的学习。(我感觉这本书写的代码太复杂而且用了很多python的底层方法)我看了一个大概的思路,然后根据自己的理解(主要pandas数据结构处理数据特征)完成了书上的内容,花了多一点时间,可能整体逻辑没有它严谨,但我是比较容易理解,也能顺便练一下手的(所需数据在这本书下载的文件夹里)。下面开始正文。以及后面使用sklearn来实现KNN。
k-邻近算法 的优缺点:
优点:精准度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用范围:数值型和标称型。
k-邻近算法的原理:
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一条数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集每个样本数据对应的特征进行比较,然后提取样本集中特征最相似数据(k个最邻近数据)的分类标签。k一般不超过20,最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
在我完成了整个内容后的总结:
k-邻近算法算是最基本最简单的一种方法了,主要需要注意的一点就是在选择计算距离算法上,观察数据特征的数量、特征的格式,然后选择最合适的距离计算算法,我推荐几种主流的方法,一般都能应付。其它的代码量可能不算少、样式可能有改变,但都是一样的思路,(选取最相似的k条数据,然后选择k条数据中标签最多的那个标签就OK了)。下面的两个例子,各用了一种距离计算的方法。
以上就是所有k-邻近的描述,下面附上我对本章代码的编写源码:
一:约会网站优化程序
数据样例如下:飞行常客里程数 玩游戏百分比 冰淇淋公升数 好感度(这是我们需要预测的)

import numpy as np
import pandas as pd
from math import sqrt
from sklearn.model_selection import train_test_split #划分数据集
#欧几里德距离 计算数据集间的距离 distance(数据集,行号,测试数据行)
def distance(data,person1,person2):
n = len(data.iloc[0])
sum_of_squares = sum(pow(data.iloc[person1][item] - person2[item],2) for item in range(n))
return 1/(1+sum_of_squares)
#kNN核心预测函数 predict(数据集,目标变量,测试数据行,kNN数,计算距离函数)
def predict(data,target,test_data,cnt=3,calculate=distance):
k = []
n = len(data)
for i in range(n):
score = calculate(data,i,test_data)
k.append((score,target.iloc[i]))
k.sort(reverse=True) #k 获得所有距离元组列表
rank = k[:cnt] #rank 获得排序后的前cnt个列表
only_labels = set(target) #only_labels 获得唯一标签集合
dic_labels = {} #dic_labels 获得标签出现次数
for i in only_labels: #初始化字典
dic_labels[i] = 0
for i in rank: #计算出现次数
dic_labels[i[1]] +=1
result = [(j,i) for i,j in dic_labels.items()] #i:类 j:次数 需要交换位置以便排序
result.sort(reverse=True)
return result[0][1]
#归一化计算函数
def normal(data,mins=0,ranges=0):
if(mins == 0):
return data.map(lambda x: (x-min(data)) / (max(data)-min(data))) #这一行与下面5行功能一致
# m = []
# for i in range(len(data)):
# k = ((data[i] - min(data)) / (max(data) - min(data)))
# m.append(k)
# return m
else:
#上面的return为原始数据集处理,这里为输入数据集处理
return np.array([(data[i]-mins[i])/ranges[i] for i in range(len(mins))])
#归一化函数
def autoNorm(data):
n = len(data.iloc[0])-1
names = data.columns
labels = data.iloc[:,n:]
df_norm = data.iloc[:,:n].apply(normal,axis=0)
# df_norm.insert(3,3,labels) #其实这里改变这种方法更好,代码的兼容性
df_norm[3] = labels
mins = []
ranges = []
for i in range(n):
mins.append(min(data[names[i]]))
ranges.append(max(data[names[i]]-min(data[names[i]])))
df_data = df_norm.iloc[:,:n-1] #数据集
df_target = df_norm.iloc[:,n:] #目标变量
df_target = df_target[df_target.columns[0]]
return df_data,df_target,mins,ranges
#二值化,转换目标变量为数字等级
def change_grade(data):
if(data[3] == 'didntLike'):
data[3] = int(1)
elif(data[3] == 'smallDoses'):
data[3] = int(2)
elif(data[3] == 'largeDoses'):
data[3] = int(3)
return data
#处理文本数据
def change(file):
df = pd.read_table(file,header=None)
df = df.apply(change_grade,axis=1)
return df
#测试错误率函数 errop_test(数据集DataFrame,目标变量Series)
def error_test(df_data,df_target):
train_X,test_X,train_y,test_y = train_test_split(df_data,df_target,test_size=0.1,random_state=10)
error = 0
n = len(test_X)
for i in range(n):
print("{} 条数据运行中...".format(i))
value = predict(train_X,train_y,test_X.iloc[i],5)
if(value != test_y.iloc[i]):
error +=1
print("预测值:{0},真实值:{1}".format(value,test_y.iloc[i]))
error_rate = error / float(n)
print("测试结果所得错误率为:{}".format(error_rate))
#手动输入数据进行测试
def judgment(df_data,df_target,mins,ranges):
target = {1:"didntLike",2:"smallDoses",3:"largeDoses"}
flight = float(input("此处输入飞行常客里程数:"))
game = float(input("此处输入玩游戏所占时间比:"))
ice_cream = float(input("此处输入每周冰淇淋公升数:"))
test_data = np.array([flight,game,ice_cream])
test_data = normal(test_data,mins,ranges) #输入数据需要归一化
result = predict(df_data,df_target,test_data)
print("对您输入数据的最终判断为:{}".format(target[result]))
if __name__=="__main__":
# 读取文本信息,并且转换列格式,后文数据准备
df = change("datingTestSet.txt")
# 归一化除目标变量的其它所有列
df_data,df_target,mins,ranges = autoNorm(df) #数据集(DataFrame) 目标变量(Series) 最小值列表list 范围列表list
# 该函数为错误测试函数,格外函数无需输入数据,用来检查我们的KNN
error_test(df_data,df_target)
# 手动输入参数函数。如需手动输入数据则取消该行注释
# judgment(df_data,df_target,mins,ranges)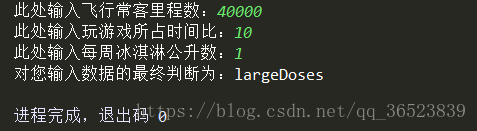
二:手写数字识别系统
样例数据如下:许许多多这样的文本,我们需要先读出每个文件到数据集中,然后在后续分类(提供有格外的测试文件夹)

import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import os
#Tanimoto距离 计算数据集间的距离
def tanimoto(data,person1,person2):
n = len(person2)
combine = [person2[item] for item in range(n) if data.iloc[person1][item] == person2[item]]
return float(len(combine)) / (2*n - len(combine))
#kNN核心预测函数 predict(数据集,目标变量,测试数据行,kNN数,计算距离函数)
def predict(data,target,test_data,cnt=3,calculate=tanimoto):
k = []
n = len(data)
for i in range(n):
score = calculate(data,i,test_data)
k.append((score,target.iloc[i]))
k.sort(reverse=True) #k 获得所有距离元组列表
rank = k[:cnt] #rank 获得排序后的前cnt个列表
only_labels = set(target) #only_labels 获得唯一标签集合
dic_labels = {} #dic_labels 获得标签出现次数
for i in only_labels: #初始化字典
dic_labels[i] = 0
for i in rank: #计算出现次数
dic_labels[i[1]] +=1
result = [(j,i) for i,j in dic_labels.items()] #i:类 j:次数 需要交换位置以便排序
result.sort(reverse=True)
return result[0][1]
#测试错误率函数 errop_test(数据集DataFrame,目标变量Series)
def error_test(df_data,df_target):
train_X,test_X,train_y,test_y = train_test_split(df_data,df_target,test_size=0.1,random_state=10)
error = 0
n = len(test_X)
for i in range(n):
print("{} 条数据运行中...".format(i))
value = predict(train_X,train_y,test_X.iloc[i],5)
if(value != test_y.iloc[i]):
error +=1
print("预测值:{0},真实值:{1}".format(value,test_y.iloc[i]))
error_rate = error / float(n)
print("测试结果所得错误率为:{}".format(error_rate))
#读取文件内容
def img2vector(filename):
returnVect = np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
#处理数据格式,然后测试错误率
def handwriting():
train_hwtarget = []
train_hwdata = []
train_filelists = os.listdir(r"./digits/trainingDigits") #获取数据集
n = len(train_filelists)
for i in range(n):
train_hwdata.append(img2vector(r'./digits/trainingDigits/{0}'.format(train_filelists[i]))[0])
train_hwtarget.append(int(train_filelists[i].split('_')[0]))
train_data = pd.DataFrame(train_hwdata)
train_target = pd.Series(train_hwtarget)
test_hwtarget = []
test_hwdata = []
test_filelists = os.listdir(r"./digits/testDigits") #根据文件名获取目标变量
m = len(test_filelists)
for i in range(m):
test_hwdata.append(img2vector(r'./digits/testDigits/{0}'.format(test_filelists[i]))[0])
test_hwtarget.append(int(test_filelists[i].split('_')[0]))
test_data = pd.DataFrame(test_hwdata)
test_target = pd.Series(test_hwtarget)
print("下面开始进行测试:")
# error_test(train_data,train_target) #方法一:直接利用训练数据集 进行划分后求错误率
error = 0
for i in range(m): #方法二:训练数据集只训练,利用已知答案测试数据集来求错误率
value = predict(train_data,train_target,test_data.iloc[i,:],5,tanimoto)
print("{} 条数据运行中...".format(i))
if(value != test_target.iloc[i]):
error +=1
print("预测错误:预测值:{0},真实值:{1}".format(value, test_target.iloc[i]))
error_rate = error / float(m)
print("测试结果所得错误率为:{}".format(error_rate))
if __name__=="__main__":
#手写数字
handwriting()
由于计算量太大,每个测试向量2000次距离计算,每个距离1024个维度运算,总共执行900次。所以我提前结束了,我用较少的测试集试过代码正确的。
这里也是我需要说明的一点,前面在缺点说明时提过,KNN的时间、空间复杂度很高,所以应该合理的使用该算法。
第二个例子,我是用的时Tanimoto距离计算算法,个人认为更合适,因为特征为二值化,当然欧几里德距离我也试过,具体使用哪个,还得看实际例子的测试结果,有心的朋友可以将两个算法都跑一遍,查看错误率的高低。
--------------------------------------------------------------------------------------------------------------------------------------
理解了k-邻近的底层知识,我们可以使用sklearn来方便快速完成建模和预测
以下数据依旧使用 手写数字识别 的数据集:
import pandas as pd
import numpy as np
import os
from sklearn import neighbors
#读取txt文本
def img2vector(filename):
returnVect = np.zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
#解析本地文件
def handwriting():
train_hwtarget = []
train_hwdata = []
train_filelists = os.listdir(r"./digits/trainingDigits") #获取数据集
n = len(train_filelists)
for i in range(n):
train_hwdata.append(img2vector(r'./digits/trainingDigits/{0}'.format(train_filelists[i]))[0])
train_hwtarget.append(int(train_filelists[i].split('_')[0]))
train_data = pd.DataFrame(train_hwdata)
train_target = pd.Series(train_hwtarget)
test_hwtarget = []
test_hwdata = []
test_filelists = os.listdir(r"./digits/testDigits") #根据文件名获取目标变量
m = len(test_filelists)
for i in range(m):
test_hwdata.append(img2vector(r'./digits/testDigits/{0}'.format(test_filelists[i]))[0])
test_hwtarget.append(int(test_filelists[i].split('_')[0]))
test_data = pd.DataFrame(test_hwdata)
test_target = pd.Series(test_hwtarget)
return train_data,train_target,test_data,test_target
if __name__=="__main__":
train_data, train_target, test_data, test_target = handwriting()
#下面为sklearn处理代码
knn = neighbors.KNeighborsClassifier() #参数根据需要修改
knn.fit(train_data,train_target)
# knn.predict(test_data) #直接传入没有目标变量的DataFrame 来预测
score = knn.score(test_data,test_target)
print(score)预测分数为0.981,相比于上面我自己写的代码有很大的区别,代码量仅有3、4行,计算速度也是远远高于上面的代码,所以sklearn如果能够在了解算法原理和实现机制的情况下,是相当好的工具。
![]()
以上为全部内容,有问题的朋友可以讨论。