Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍
目录
一、什么是 Mapping?
二、Mapping的数据类型
2.1. 核心数据类型
2.1.1、字符串类型
2.1.2、数字类型
2.1.3、日期类型
2.1.4、布尔类型
2.1.5、二进制类型
2.1.5、范围类型
2.2、复杂类型
2.2.1、对象类型(object)
2.2.2 嵌套类型(nested)
2.3. 地理数据类型
2.4. 特殊数据类型
2.5.数组类型
三、Dynamic Mapping (动态Mapping)
3.1、类型自动识别
3.2、能否更改mapping的字段类型
四、显式Mapping及常见参数
4.1、映射参数
4.1.1、analyzer 分词器(重点)和 search_analyzer
4.1.2、index
4.1.3、index_options参数
4.1.4、null_value设置
4.1.5、copy_to
五、精确值和全文本
六. 小结
Elasticsearch的Mapping,定义了索引的结构,类似于关系型数据库的Schema。Elasticsearch的Setting定义中定义分片和副本数以及搜索的最关键组件,即:Analyzer,也就是分析器。
一、什么是 Mapping?
Mapping类似于关系型数据库的Schema,主要包含以下内容:
- 定义索引中字段的名称
- 定义字段的数据类型,如:字符串、数字、boolean等
- 可对字段设置倒排索引的相关配置,如是否需要分词,使用什么分词器
从7.x开始,一个Mapping只属于一个索引的type 默认type 为:_doc
- 每个文档属于一个type
- 一个type有且仅有一个Mapping定义
- 从7.x开始,不需要在Mapping中指定type信息,默认type为
_doc
二、Mapping的数据类型
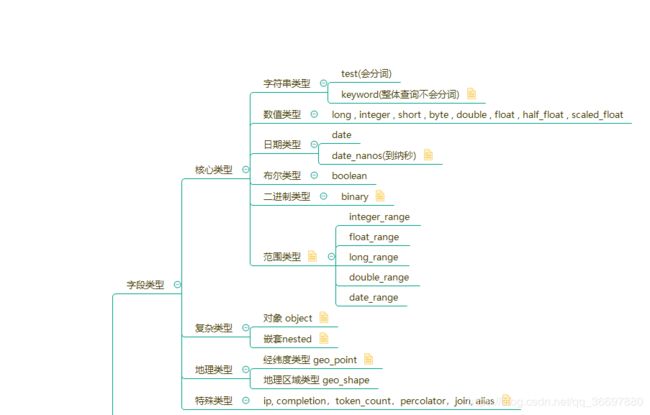
ES 字段类型类似于 MySQL 中的字段类型,ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型,具体的数据类型如下图所示:
官网参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/mapping-params.html
2.1. 核心数据类型
核心数据类型与我们常使用的强类型语言中的数据类型类似,可分为以下几类:
| 属性名字 | 说明 |
| text | 用于全文索引,该类型的字段将通过分词器进行分词,最终用于构建索引 |
| keyword | 不分词 |
| long | 有符号64-bit integer:-2^63 ~ 2^63 - 1 |
| integer | 有符号32-bit integer,-2^31 ~ 2^31 - 1 |
| short | 有符号16-bit integer,-32768 ~ 32767 |
| byte | 有符号8-bit integer,-128 ~ 127 |
| double | 64-bit IEEE 754 浮点数 |
| float | 32-bit IEEE 754 浮点数 |
| half_float | 16-bit IEEE 754 浮点数 |
| boolean | true,false |
| date | https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html |
| binary | 该类型的字段把值当做经过 base64 编码的字符串,默认不存储,且不可搜索 |
2.1.1、字符串类型
在 ES 7.x 有两种字符串类型:text 和 keyword,在 ES 5.x 之后 string 类型已经不再支持了。
text :类型适用于需要被全文检索的字段,例如新闻正文、邮件内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。
keyword:不会被分词,适合简短、结构化字符串,例如主机名、姓名、商品名称等,可以用于过滤、排序、聚合检索,也可以用于精确查询。
2.1.2、数字类型
数字类型分为 long、integer、short、byte、double、float、half_float、scaled_float。
数字类型的字段在满足需求的前提下应当尽量选择范围较小的数据类型,字段长度越短,搜索效率越高,对于浮点数,可以优先考虑使用 scaled_float 类型,该类型可以通过缩放因子来精确浮点数,例如 12.34 可以转换为 1234 来存储。
2.1.3、日期类型
在 ES 中日期可以为以下形式:
格式化的日期字符串,例如 2020-03-17 00:00、2020/03/17时间戳(和 1970-01-01 00:00:00 UTC 的差值),单位毫秒或者秒即使是格式化的日期字符串,ES 底层依然采用的是时间戳的形式存储。
{
"mappings": {
"_doc": {
"properties": {
"create_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}2.1.4、布尔类型
JSON 文档中同样存在布尔类型,不过 JSON 字符串类型也可以被 ES 转换为布尔类型存储,前提是字符串的取值为 true 或者 false,布尔类型常用于检索中的过滤条件。
2.1.5、二进制类型
二进制类型 binary 接受 BASE64 编码的字符串,默认 store 属性为 false,并且不可以被搜索。
2.1.5、范围类型
围类型可以用来表达一个数据的区间,可以分为5种:
integer_range、float_range、long_range、double_range 以及 date_range。
#创建索引
PUT /range_test
{
"mappings": {
"_doc": {
"properties": {
"count": {
"type": "integer_range"
},
"create_date": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
#添加数据
POST /range_test/_doc/1
{
"count" : {
"gte" : 1,
"lte" : 100
},
"create_date" : {
"gte" : "2019-02-1 12:00:00",
"lte" : "2019-03-30"
}
}
#检索 其中5 在 1-100之间可以被检索出来
GET /range_test/_doc/_search
{
"query":{
"term":{
"count":5
}
}
}2.2、复杂类型
复合类型主要有对象类型(object)和嵌套类型(nested)
2.2.1、对象类型(object)
JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档:
PUT my_index/_doc/1
{
"region": "US",
"manager": {
"age": 30,
"name": {
"first": "John",
"last": "Smith"
}
}
}
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"region": {
"type": "keyword"
},
"manager": {
"properties": {
"age": { "type": "integer" },
"name": {
"properties": {
"first": { "type": "text" },
"last": { "type": "text" }
}
}
}
}
}
}
}
}
其中域manager就是一个对象类型,其中的name是它的子对象。对于对象类型,缺省设置“type”为”object”,因此不用显式定义“type”。
对于上面的对象类型,ES在索引时将其转换为"manager.age", "manager.name.first" 这样扁平的key,因此查询时也可以使用这样的扁平key作为域来进行查询。
2.2.2 嵌套类型(nested)
嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档
- 对于对象:
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
如果使用动态映射,会被ES索引为如下形式:
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
这样的索引形式在查询时会丢失对象中”first”与“last”之间的关联关系。
如果将user映射为如下形式:
"user": {
"type": "nested"
}
ES在索引时会保留对象域之间的关联关系,在查询时找对正确的对象。
如使用如下查询则找不到任何命中对象(不存在“Alice Smith”这个对象):
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "Smith" }}
]
}
}
}
}
}2.3. 地理数据类型
地理数据类型可用于LBS的应用,包括:
- geo_point类型:可用于存储某个地理坐标的经纬度。示例如下:
// location为geo_point类型
"location": {
"lat": 41.12,
"lon": -71.34
}
- geo_shape类型:用于存储地理多边形形状,有兴趣的读者可以参考文献1。
2.4. 特殊数据类型
特殊数据类型包括:
- ip类型:用于表示IPv4与IPv6的地址
- completion类型:提供自动输入关联完成功能,如常见的baidu搜索框。
- token_count类型:用于计算字符串token的长度,使用时需提供"analyzer"定义。
- percolate类型:定义为percolate类型的字段会被ES分析为一个查询并保存下来,并可用在后继对文档的查询中。Percolate可以理解为一个预置的查询。
- alias类型:定义一个已存在域的别名。
- join类型:该类型定义了文档对象之间的父子关系(可定义多层,形成一颗层次树),即同一索引中多个文档对象可以存在依赖关系,如互联网应用常见的博客文章与回复,问题与回答之间的关系。参考官方文档
定义映射字段:
{
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
my_join_field定义了"question"与"answer"之间关系为父子关系。
观察对于该映射的一个文档实例,路径为“my_index/_doc/1”:
{
"text": "This is a question",
"my_join_field": "question"
}
该文档的一个子文档对象示例如下,在my_join_field需要定义父亲的ID(这里根据上面的父实例,为1):
{
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
需要注意的是,一个父文档可以有多个子文档,父子文档应部署在同一个分片上。因而在向ES提交父子文档时,应在URI中使用相同的routing参数。
join类型定义了文档之间的父子依赖关系,在查询和聚合操作中可使用这种依赖关系。
2.5.数组类型
Elasticsearch不提供专门的数组类型。但任何字段,都可以包含多个相同类型的数值。
# 数组类型
PUT users/_doc/1
{
"name":"onebird",
"interests":"reading"
}
PUT users/_doc/1
{
"name":"twobirds",
"interests":["reading","music"]
}
POST users/_search
{
"query": {
"match_all": {}
}
}
# interests字段还是text类型
GET users/_mapping
三、Dynamic Mapping (动态Mapping)
Dynamic Mapping 翻译为动态Mapping:
- 在写入文档时,如果索引不存在,会自动创建索引
- 这种机制,使得我们无需手动定义mappings。Elasticsearch会自动根据文档信息,推算出字段的类型
- 有的时候,Elasticsearch可能会推算不对,如:地理位置信息
- 当类型推算得不对时,可能导致一些功能无法正常运行,如Range查询。
3.1、类型自动识别
ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:
| 类型 | 规则 |
|---|---|
| 字符串 | 匹配到日期格式,设置成Date。 字符串为数字时,当成字符串处理,但我们设置转换为数字。 其他情况,类型就是Text,并且会增加keyword的子字段 |
| 布尔值 | Boolean |
| 浮点数 | Float |
| 整数 | Long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型决定 |
| 空值 | 忽略 |
下面是具体推断 demo
# 写入文档,查看 Mapping
PUT mapping_test/_doc/1
{
"firstName": "Chan", -- Text
"lastName": "Jackie", -- Text
"loginDate": "2018-07-24T10:29:48.103Z" -- Date
}
# Dynamic Mapping,推断字段的类型
PUT mapping_test/_doc/1
{
"uid": "123", -- Text
"isVip": false, -- Boolean
"isAdmin": "true", -- Text
"age": 19, -- Long
"heigh": 180 -- Long
}
# 查看 Dynamic Mapping
GET mapping_test/_mapping3.2、能否更改mapping的字段类型
分两种情况:
1、新增加的字段
- dynamic设为true时,新增字段的文档写入时,Mapping同时被更新
- dynamic设为false时,Mapping不会被更新,新增字段的数据无法被索引,但是会出现在_source中
- dynamic设为strict,文档将写入失败
2、已存在的字段,一旦数据被写入,就不再支持修改字段定义
- Lucene本身的限制
- 如果希望更改字段类型,必须Reindex api,即:重建索引。在数据量多的时候,开销将非常大
# dynamic设置为false
PUT idx1
{
"mapping": {
"_doc": {
"dynamic": "false"
}
}
}
# 修改为dynamic为false
PUT idx1/_mapping
{
"dynamic": false
}
# 查看索引
GET idx1/_mapping
dynamic属性和索引字段可变性的规则,我们可以总结如下:
| \ | true | false | strict |
|---|---|---|---|
| 文档可索引 | yes | yes | no |
| 字段可索引 | yes | no | no |
| Mapping被更新 | yes | no | no |
四、显式Mapping及常见参数
在本文的上一段落,我们的Mapping都是自动生成的。自动生成机制虽然方便,但是也可能导致一些问题。比如:生成的字段类型不正确,字段的附加属性不满足我们的需求,等等。这时,我们可以通过显式Mapping的方式来解决。
那么,我们如何进行显式Mapping的设置呢?
- 参考官网api,纯手写
- 为减少工作量,减少出错概率,可如下进行:
- 创建一个临时index,写入一些样本数据
- 通过访问Mapping API获取该临时文件的动态Mapping定义
- 修改后,再使用此配置创建自己的索引
- 删除临时索引
我们推荐使用第二种方式,效率高,且不容易出错。
4.1、映射参数
JSON是JS对象序列化的字符串,ES接收一个JSON字符串形式的文档对象,本质上是存入一个JS对象,JS定义了对象,数组,字符串,数字,布尔型和null等数据类型。
ES中的域数据类型可视为对JS对象数据类型的扩展,如join,区间类型等都表示为js对象。
在定义域映射时,ES定义了相关的映射参数,这里简单列举并描述,详细信息可以官方文档

mappings 中field定义选择
"field": {
"type": "text", //文本类型
"index": "false"// ,设置成false,字段将不会被索引
"analyzer":"ik"//指定分词器
"boost":1.23//字段级别的分数加权
"doc_values":false//对not_analyzed字段,默认都是开启,analyzed字段不能使用,对排序和聚合能提升较大性能,节约内存,如果您确定不需要对字段进行排序或聚合,或者从script访问字段值,则可以禁用doc值以节省磁盘空间:
"fielddata":{"loading" : "eager" }//Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
"fields":{"keyword": {"type": "keyword","ignore_above": 256}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
"include_in_all":ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
"index_options":"docs"//4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
"norms":{"enable":true,"loading":"lazy"}//分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
"null_value":"NULL"//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
"position_increament_gap":0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
"store":false//是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
"search_analyzer":"ik"//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
"similarity":"BM25"//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
"term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
}
总结一下:
- 与域数据格式及约束相关的参数:normalizer,format,ignore_above,ignore_malformed,coerce
- 与索引相关的参数:index,dynamic,enabled
- 与存储策略相关的参数:store, fielddata,doc_values
- 分析器相关参数:analyzer,search_analyzer
- 其它参数:boost,copy_to,null_value
对于这些参数的描述主要基于笔者的理解,可能有不准确之处。实际上这些参数与ES的实现机制(如存储结构,索引结构密切有关),只能在实际应用中去慢慢体会。
4.1.1、analyzer 分词器(重点)和 search_analyzer
PUT /my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
}
}
}
}
}
}
#使用_analyze 测试分词器
GET my_index/_analyze
{
"field": "text",
"text": "The quick Brown Foxes."
}
GET my_index/_analyze
{
"field": "text.english",
"text": "The quick Brown Foxes."
}4.1.2、index
index,可用于设置字段是否被索引,默认为true,false即为不可搜索。在下述例子中,mobile字段将不能被搜索到。
# index属性控制 字段是否可以被索引
PUT user_test
{
"mappings": {
"properties": {
"firstName":{
"type": "text"
},
"lastName":{
"type": "text"
},
"mobile" :{
"type": "text",
"index": false
}
}
}
}4.1.3、index_options参数
index_options的作用是用于控制倒排索引记录的内容,有如下四种配置:
docs:只记录doc id
freqs:记录doc id 和term frequencies
positions:记录doc id、 term frequencies和term position
offsets:记录doc id、 term frequencies、term position、character offsets
text类型的默认配置为positions,其他默认为docs。记录的内容越多,占据的空间越大。

4.1.4、null_value设置
需要对Null值实现搜索时使用。只有keyword类型才支持设定null_value
# 设定Null_value
DELETE users
PUT users
{
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text"
},
"lastName" : {
"type" : "text"
},
"mobile" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
PUT users/_doc/1
{
"firstName":"Zhang",
"lastName": "Fubing",
"mobile": null
}
PUT users/_doc/2
{
"firstName":"Zhang",
"lastName": "Fubing2"
}
# 查看结果,有且仅有_id为2的记录
GET users/_search
{
"query": {
"match": {
"mobile":"NULL"
}
}
}4.1.5、copy_to
这个属性用于将当前字段拷贝到指定字段。
_all在7.x版本已经被copy_to所代替- 可用于满足特定场景
copy_to将字段数值拷贝到目标字段,实现类似_all的作用copy_to的目标字段不出现在_source中
DELETE user_test
#设置 Copy to
PUT user_test
{
"mappings": {
"properties": {
"firstName":{
"type": "text",
"copy_to": "fullName"
},
"lastName":{
"type": "text",
"copy_to": "fullName"
}
}
}
}
PUT user_test/_doc/1
{
"firstName":"Ruan",
"lastName": "Yiming"
}
POST user_test/_search?q=fullName:(Ruan Yiming)五、精确值和全文本
精确值(Exact Values) vs 全文本(Full Text)
精确值,包括数字、日期、具体的字符串(如“192.168.0.1”)
Elasticsearch中类型为keyword,索引时,不需要做特殊的分词处理
全文本,非结构化的文本数据
Elasticsearch中类型为text,索引时,需要对其进行分词处理
如下结构的数据,我们可以大致判断出哪些是精确值,哪些是全文本。其中的200、info、debug都是精确值。而message的内容为全文本。
{
"code": 200,
"message": "this is a error item, you can change your apollo config !",
"content": {
"tags": [
"info",
"debug"
]
}
六. 小结
视图库中对象的字段不用进行全文检索,也可以使用关系数据库作为存储容器,但需要对JSON数据进行反序列化解析相应字段入库,查询出库时需要将多个字段序列化为JSON数据。固然在编程时可以使用ORM和JSON序列化中间件来完成工作,但在海量请求下,效率会有影响。使用ES可以利用ES的restful接口和JSON存储格式的天然特性以契合规范要求。
在视图库规范中有一些自定义的约束,这些涉及数据有效性检验的服务应该部署在ES入库之前。在本实例中,更多的是把ES作为一个Nosql数据库使用。
一个完整的mapping 设置,关于分词器定义会在后面学习到
{
"settings": {
"analysis": {
"analyzer": {
"ik_pinyin_analyzer": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["my_pinyin"]#自定义filter
},
"pinyin_analyzer": {
"tokenizer": "shopmall_pinyin"
},
"first_py_letter_analyzer": {
"tokenizer": "first_py_letter"
},
"full_pinyin_letter_analyzer": {
"tokenizer": "full_pinyin_letter"
},
"onlyOne_analyzer": {
"tokenizer": "onlyOne_pinyin"
}
},
"tokenizer": {#自定义分词器
"onlyOne_pinyin": {
"type":"pinyin",
"keep_separate_first_letter": "false",
"keep_first_letter":"false"
},
"shopmall_pinyin": {
"keep_joined_full_pinyin": "true",
"keep_first_letter": "true",
"keep_separate_first_letter": "false",
"lowercase": "true",
"type": "pinyin",
"limit_first_letter_length": "16",
"keep_original": "true",
"keep_full_pinyin": "true",
"keep_none_chinese_in_joined_full_pinyin": "true"
},
"first_py_letter": {
"type": "pinyin",
"keep_first_letter": true,
"keep_full_pinyin": false,
"keep_original": false,
"limit_first_letter_length": 16,
"lowercase": true,
"trim_whitespace": true,
"keep_none_chinese_in_first_letter": false,
"none_chinese_pinyin_tokenize": false,
"keep_none_chinese": true,
"keep_none_chinese_in_joined_full_pinyin": true
},
"full_pinyin_letter": {
"type": "pinyin",
"keep_separate_first_letter": false,
"keep_full_pinyin": false,
"keep_original": false,
"limit_first_letter_length": 16,
"lowercase": true,
"keep_first_letter": false,
"keep_none_chinese_in_first_letter": false,
"none_chinese_pinyin_tokenize": false,
"keep_none_chinese": true,
"keep_joined_full_pinyin": true,
"keep_none_chinese_in_joined_full_pinyin": true
}
},
"filter": {
"my_pinyin": {
"type": "pinyin",
"keep_joined_full_pinyin": true,
"keep_separate_first_letter":true
}
}
}
},
"mappings": {
"doc": {#type名字
"properties": {#mapping的属性
"productName": {属性名字
"type": "text",#属性类型
"analyzer": "ik_pinyin_analyzer",#分词器
"fields": {#fields 指定自定义分词器 查询时通过productName.keyword_once_pinyin 可以指定
"keyword_once_pinyin": {
"type": "text",
"analyzer": "onlyOne_analyzer"#指定的自定义分词器
}
}
},
"skuNames": {
"type": "text",
"analyzer": "ik_pinyin_analyzer",
"fields": {
"keyword_once_pinyin": {
"type": "text",
"analyzer": "onlyOne_analyzer"
}
}
},
"regionCode": {
"type": "keyword"
},
"productNameSuggester": {#es6.x搜索建议实现
"type": "completion",
"fields": {
"pinyin": {
"type": "completion",
"analyzer": "pinyin_analyzer"
},
"keyword_pinyin": {
"type": "completion",
"analyzer": "full_pinyin_letter_analyzer"
},
"keyword_first_py": {
"type": "completion",
"analyzer": "first_py_letter_analyzer"
}
}
}
"info": {#es6父子类型设置
"type": "join",
"relations": {
"md_product":[ "sl_customer_character_order_list","ic_product_store_account","sl_customer_product_setting"]
}
}
}
}
}
}