Tensorflow2.0之CycleGAN
文章目录
- CycleGAN介绍
- CycleGAN与DCGAN的对比
- CycleGAN与pix2pix模型的对比
- CycleGAN应用
- 代码实现
- 1、导入需要的库
- 2、导入horse2zebra数据集
- 3、加载数据集中的图片
- 将图片加载成Tensorflow需要的格式
- 展示图像
- 4、处理图片
- 4.1 将图像调整为更大的高度和宽度
- 4.2 随机裁剪到目标尺寸
- 4.3 随机将图像做水平镜像处理
- 4.4 图像归一化
- 4.5 处理训练集图片
- 4.6 处理测试集图片
- 4.7 将训练集所有图片进行切片操作,放入一个dataset中
- 4.8 将测试集所有图片进行切片操作,放入一个dataset中
- 4.9 建立迭代器,使每次取出1张图片
- 5、导入 Pix2Pix 模型
- 6、构造损失函数
- 6.1 定义判别器损失函数
- 6.2 定义生成器损失函数
- 6.3 定义循环一致损失函数
- 6.4 定义一致性损失函数
- 7、初始化优化器
- 8、定义图像生成函数
- 9、定义训练一次的函数
- 10、训练
- 11、测试
- 参考资料
CycleGAN介绍
CycleGAN的原理可以概述为:将一类图片转换成另一类图片。也就是说,现在有两个样本空间,X和Y,我们希望把X空间中的样本转换成Y空间中的样本。
CycleGAN与DCGAN的对比
为了进一步搞清楚CycleGAN的原理,我们可以拿它和其他几个GAN模型,如DCGAN、pix2pix模型进行对比。
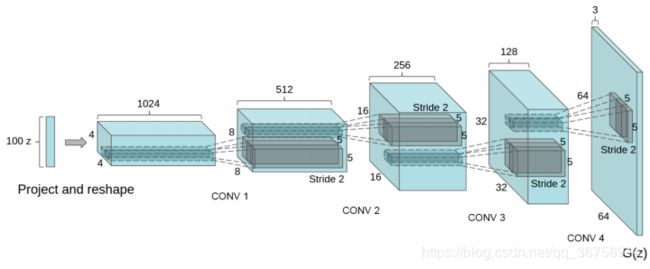
先来看下DCGAN,它的整体框架和最原始的那篇GAN是一模一样的,在这个框架下,输入是一个噪声z,输出是一张图片(如下图),因此,我们实际只能随机生成图片,没有办法控制输出图片的样子,更不用说像CycleGAN一样做图片变换了。
CycleGAN与pix2pix模型的对比
pix2pix也可以做图像变换,它和CycleGAN的区别在于,pix2pix模型必须要求成对数据(paired data),而CycleGAN利用非成对数据(unpaired data)也能进行训练。
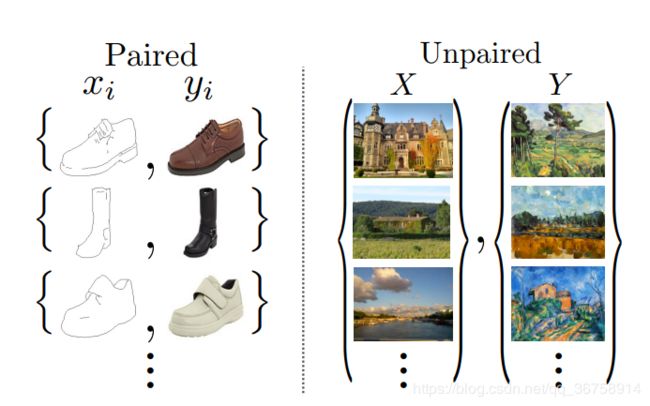
比如,我们希望训练一个将白天的照片转换为夜晚的模型。如果使用pix2pix模型,那么我们必须在搜集大量地点在白天和夜晚的两张对应图片,而使用CycleGAN只需同时搜集白天的图片和夜晚的图片,不必满足对应关系。因此CycleGAN的用途要比pix2pix更广泛,利用CycleGAN就可以做出更多有趣的应用。
CycleGAN应用
把照片转换成油画风格:

将油画中的场景还原成现实中的照片:

由于CycleGAN这个框架具有较强的通用性,因此一经发表就吸引了大量注意,很快,脑洞大开的网友想出了各种各样神奇的应用。
比如将猫变成狗:

让图片中的人露出笑容:

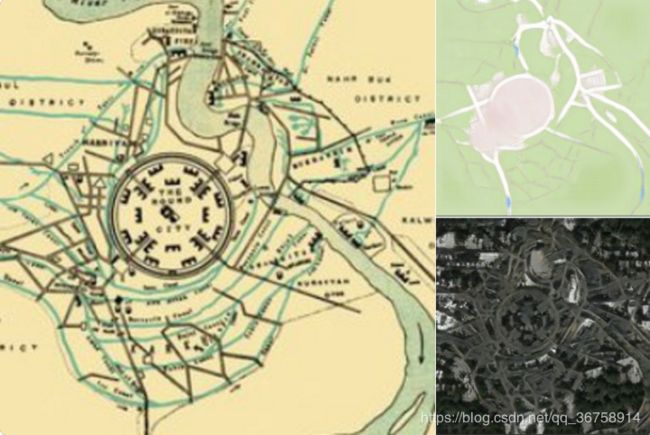
国外网友Jack Clark还搜集了巴比伦、耶路撒冷以及伦敦的古代地图,利用CycleGAN将它们还原成了真实卫星图像:

还有人使用CycleGAN将人脸转换成娃娃:

将男人变成女人:

把你自己变成一个“肌肉文身猛男”也是可以的:

代码实现
在这里,我们将演示如何利用CycleGAN将马的图片转换为斑马的图片。
1、导入需要的库
安装 tensorflow_examples 包,以导入生成器和判别器, tensorflow_examples 包中包含Pix2pix模型,当然也可以自己训练,参考:Tensorflow2.0之Pix2pix。
import tensorflow as tf
from tensorflow_examples.models.pix2pix import pix2pix
import os
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.experimental.AUTOTUNE
2、导入horse2zebra数据集
PATH = 'C:\\Users\\ThinkPad\\.keras\\datasets\\horse2zebra/'
train_horses = tf.data.Dataset.list_files(PATH+'trainA/*.jpg')
train_zebras = tf.data.Dataset.list_files(PATH+'trainB/*.jpg')
test_horses = tf.data.Dataset.list_files(PATH+'testA/*.jpg')
test_zebras = tf.data.Dataset.list_files(PATH+'testB/*.jpg')
3、加载数据集中的图片
将图片加载成Tensorflow需要的格式
def load(image_file):
image = tf.io.read_file(image_file)
image = tf.image.decode_jpeg(image)
image = tf.cast(image, tf.float32)
return image
展示图像
img = load(PATH+'trainB/n02391049_2.jpg')
# casting to int for matplotlib to show the image
plt.figure()
plt.imshow(img/255.0)
4、处理图片
4.1 将图像调整为更大的高度和宽度
为后面的Random jittering 做准备。
def resize(input_image, height, width):
image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return image
4.2 随机裁剪到目标尺寸
对一张图片进行多次(如10次)随机裁剪,将得到的10张图片放到一起看时,有一种图片在跳动的感觉。所以称这种方法为Random jittering,其主要作用是防止过拟合。
# 目标尺寸
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
4.3 随机将图像做水平镜像处理
水平镜像处理的目的也是为了防止过拟合。
def random_jitter(image):
# 调整大小为 286 x 286 x 3
image = resize(image, 286, 286)
# 随机裁剪到 256 x 256 x 3
image = random_crop(image)
# 随机镜像
image = tf.image.random_flip_left_right(image)
return image
4.4 图像归一化
# 将图像归一化到区间 [-1, 1] 内。
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
4.5 处理训练集图片
def preprocess_image_train(image_file):
image = load(image_file)
image = random_jitter(image)
image = normalize(image)
return image
4.6 处理测试集图片
def preprocess_image_test(image_file):
image = load(image_file)
image = normalize(image)
return image
4.7 将训练集所有图片进行切片操作,放入一个dataset中
BUFFER_SIZE = 1000
BATCH_SIZE = 1
train_horses = train_horses.map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
4.8 将测试集所有图片进行切片操作,放入一个dataset中
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
4.9 建立迭代器,使每次取出1张图片
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
5、导入 Pix2Pix 模型
通过安装的 tensorflow_examples 包导入 Pix2Pix 中的生成器和判别器。
CycleGAN 中使用模型体系结构与导入的 Pix2Pix 中所使用的非常相似。一些区别在于:
- Cyclegan 使用 instance normalization(实例归一化)而不是 batch normalization (批归一化)。
- CycleGAN 论文使用一种基于 resnet 的改进生成器。简单起见,本教程使用的是改进的 unet 生成器。
这里训练了两个生成器( G G G 和 F F F)以及两个判别器( X X X 和 Y Y Y)。
- 生成器 G G G 学习将图片 X X X 转换为 Y Y Y。( G : X → Y G: X\rightarrow Y G:X→Y)
- 生成器 F F F 学习将图片 Y Y Y 转换为 X X X。( F : Y → X F: Y\rightarrow X F:Y→X)
- 判别器 D X D_X DX 学习区分图片 X X X 与生成的图片 X X X ( 即 F ( Y ) ) (即F(Y)) (即F(Y))。
- 判别器 D Y D_Y DY 学习区分图片 Y Y Y 与生成的图片 Y Y Y ( 即 G ( X ) ) (即G(X)) (即G(X))。

OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
6、构造损失函数
在 CycleGAN 中,没有可训练的成对数据,因此无法保证输入 x x x 和 目标 y y y 数据对在训练期间是有意义的。所以为了强制网络学习正确的映射,有学者提出了循环一致损失。
6.1 定义判别器损失函数
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
6.2 定义生成器损失函数
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
6.3 定义循环一致损失函数
循环一致意味着结果应接近原始输出。例如,将一句英文译为法文,随后再从法文翻译回英文,最终的结果句应与原始句输入相同。
在循环一致损失中,
- 图片 X X X通过生成器 G G G传递,该生成器生成图片 Y ^ \hat{Y} Y^。
- 生成的图片 Y ^ \hat{Y} Y^通过生成器 F F F传递,循环生成图片 X ^ \hat{X} X^。
- 在 X X X和 X ^ \hat{X} X^之间计算平均绝对误差。
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
6.4 定义一致性损失函数
如6.3所示,生成器 G G G负责将图片 X X X转换为 Y ^ \hat{Y} Y^。一致性损失表明,如果将图片 Y Y Y输入给生成器 G G G,它应当生成真实图片 Y Y Y或接近于 Y Y Y的图片。即:
![]()
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
7、初始化优化器
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
8、定义图像生成函数
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# 获取范围在 [0, 1] 之间的像素值以绘制它。
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
9、定义训练一次的函数
训练循环包含四个基本步骤:
- 获取预测。
- 计算损失值。
- 使用反向传播计算损失值。
- 将梯度应用于优化器。
def train_step(real_x, real_y):
# persistent 设置为 Ture,因为 GradientTape 被多次应用于计算梯度。
with tf.GradientTape(persistent=True) as tape:
# 生成器 G 转换 X -> Y。
# 生成器 F 转换 Y -> X。
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x 和 same_y 用于一致性损失。
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# 计算损失。
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# 总生成器损失 = 对抗性损失 + 循环损失。
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# 计算生成器和判别器损失。
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# 将梯度应用于优化器。
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
10、训练
EPOCHS = 40
for epoch in range(EPOCHS):
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n+=1
clear_output(wait=True)
# 使用一致的图像(sample_horse),以便模型的进度清晰可见。
generate_images(generator_g, sample_horse)
11、测试
# 在测试数据集上运行训练的模型。
for inp in test_horses.take(5):
generate_images(generator_g, inp)
参考资料
可能是近期最好玩的深度学习模型:CycleGAN的原理与实验详解