Tensorflow2.0之词嵌入的原理及实现
文章目录
- 处理文本的方法
- 1、独热编码
- 2、用唯一的数字对每个字进行编码
- 3、词嵌入
- 代码实现
- 1、导入需要的库
- 2、处理数据
- 2.1 下载数据集
- 2.2 创建一个 tf.data 数据集
- 2.3 查看词汇表
- 3、创建模型
- 4、训练
处理文本的方法
深度学习的模型以向量(数字数组)作为输入。在处理文本时,我们必须首先在输字符串到模型之前,将字符串转换为数字(或将文本“矢量化”)。在此文章中,我们将介绍三种实现此目标的方法。
1、独热编码
我们可以对每个单词进行独热编码。以“The cat sat on the mat”这句话举例,这个句子中的词汇(或独特的单词)是(cat,mat,on,sat,the)。为了表示每个单词,我们将创建一个长度等于词汇表的零向量,然后在对应单词的索引中放置一个向量。这种方法如下图所示。
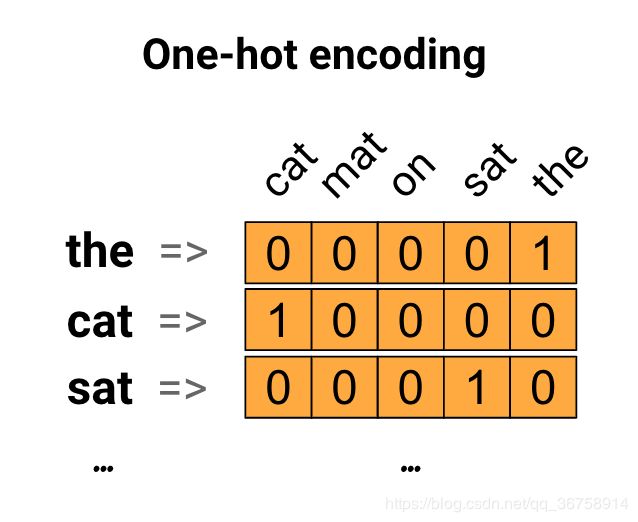 为了创建包含句子编码的向量,我们可以为每个单词创建一个独热向量。
为了创建包含句子编码的向量,我们可以为每个单词创建一个独热向量。
然而,这种方法效率比较低。一个独热编码向量是稀疏的(大多数索引都是零)。假设我们的词汇表中有10000个单词。对其中一个单词进行独热编码时,我们将创建一个向量,其中99.99%的元素为零。
2、用唯一的数字对每个字进行编码
第二种方法是使用唯一的数字对每个单词进行编码。继续上面的示例,我们可以将1指定给“cat”,将2指定给“mat”,依此类推。然后我们可以把“The cat sat on the mat”这个句子编码成一个向量,如[5,1,4,3,5,2]。现在我们有了一个稠密的向量(所有元素都是非零数),而不是稀疏的向量。
然而,这种方法有两个缺点:
- 整数编码是任意的(它不捕获单词之间的任何关系)。
- 整数编码难以对模型进行解释。例如,线性分类器为每一个特征都学习获得一个权重。由于任意两个词的相似度与其编码的相似度之间没有关系,因此这种特征-权重组合是没有意义的。
3、词嵌入
在词嵌入方法中,相似的单词具有相似的编码。每个单词都被嵌入到更高维度(几维是用户决定的)的向量中,它们不是手动指定嵌入的值,而是可训练的参数(可以理解为在训练期间模型要学习的权重)。通常将词嵌入到8到1024维的空间中。更高维度的嵌入可以捕获单词之间更细微的关系,但同时也需要更多的数据来学习。如下图,每个单词都被表示为浮点类型的四维向量。

代码实现
1、导入需要的库
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
2、处理数据
这里我们用的数据集是 IMDB 评论数据集。
2.1 下载数据集
(train_data, test_data), info = tfds.load(
'imdb_reviews/subwords8k',
split = (tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True, as_supervised=True)
2.2 创建一个 tf.data 数据集
train_batches = train_data.shuffle(1000).padded_batch(10)
test_batches = test_data.shuffle(1000).padded_batch(10)
train_batch, train_labels = next(iter(train_batches))
2.3 查看词汇表
encoder = info.features['text'].encoder
encoder.subwords[:20]
['the_',
', ',
'. ',
'a_',
'and_',
'of_',
'to_',
's_',
'is_',
'br',
'in_',
'I_',
'that_',
'this_',
'it_',
' /><',
' />',
'was_',
'The_',
'as_']
3、创建模型
embedding_dim=16
model = keras.Sequential([
layers.Embedding(encoder.vocab_size, embedding_dim),
layers.GlobalAveragePooling1D(),
layers.Dense(16, activation='relu'),
layers.Dense(1)
])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 16) 130960
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 131,249
Trainable params: 131,249
Non-trainable params: 0
_________________________________________________________________
4、训练
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(
train_batches,
epochs=10,
validation_data=test_batches, validation_steps=20)
Epoch 1/10
2500/2500 [==============================] - 10s 4ms/step - loss: 0.5008 - accuracy: 0.7014 - val_loss: 0.3832 - val_accuracy: 0.8050
Epoch 2/10
2500/2500 [==============================] - 10s 4ms/step - loss: 0.2806 - accuracy: 0.8836 - val_loss: 0.3297 - val_accuracy: 0.8950
Epoch 3/10
2500/2500 [==============================] - 9s 4ms/step - loss: 0.2294 - accuracy: 0.9109 - val_loss: 0.3606 - val_accuracy: 0.8600
Epoch 4/10
2500/2500 [==============================] - 9s 4ms/step - loss: 0.1936 - accuracy: 0.9254 - val_loss: 0.4484 - val_accuracy: 0.8450
Epoch 5/10
2500/2500 [==============================] - 10s 4ms/step - loss: 0.1727 - accuracy: 0.9347 - val_loss: 0.4735 - val_accuracy: 0.8350
Epoch 6/10
2500/2500 [==============================] - 10s 4ms/step - loss: 0.1549 - accuracy: 0.9433 - val_loss: 0.3823 - val_accuracy: 0.8650
Epoch 7/10
2500/2500 [==============================] - 9s 4ms/step - loss: 0.1401 - accuracy: 0.9491 - val_loss: 0.5040 - val_accuracy: 0.8250
Epoch 8/10
2500/2500 [==============================] - 10s 4ms/step - loss: 0.1285 - accuracy: 0.9524 - val_loss: 0.6172 - val_accuracy: 0.8150
Epoch 9/10
2500/2500 [==============================] - 10s 4ms/step - loss: 0.1160 - accuracy: 0.9580 - val_loss: 0.5485 - val_accuracy: 0.8500
Epoch 10/10
2500/2500 [==============================] - 9s 4ms/step - loss: 0.1105 - accuracy: 0.9607 - val_loss: 0.4089 - val_accuracy: 0.8800