Tensorflow2.0之理解语言的 Transformer 模型
文章目录
- 项目介绍
- 代码实现
- 1、导入需要的库
- 2、导入数据集
- 3、将文本编码成数字形式
- 3.1 使用 tfds.features.text.Tokenizer() 函数
- 3.1.1 建立词汇表并统计词汇表中的单词数量
- 3.1.2 建立编码器
- 3.1.3 对所有样本进行编码
- 3.1.3.1 删除过长的样本
- 3.1.3.2 编码函数
- 3.1.3.3 将样本打乱、分批
- 3.2 使用 tf.keras.preprocessing.text.Tokenizer 类
- 3.2.1 将样本写入元组
- 3.2.2 生成词典并将文本转化为数字向量
- 3.2.3 将数据集全部转化为数字向量
- 3.2.4 将样本打乱、分批
- 4、位置编码
- 5、遮挡(Masking)
- 5.1 填充遮挡
- 5.2 前瞻遮挡
- 5.3 生成所有遮挡
- 6、Scaled dot-product attention
- 7、Multi-head attention(多头注意力)
- 8、Position-wise feed-forward networks(点式前馈网络)
- 9、编码与解码
- 9.1 编码器层
- 9.2 解码器层
- 9.3 编码器
- 9.4 解码器
- 10、创建 Transformer
- 11、配置超参数
- 12、优化器
- 13、损失函数与指标
- 14、训练
- 14.1 检查点
- 14.2 梯度下降
- 14.3 训练
- 15、评估
- 15.1 评估函数
- 15.2 注意力权重图
- 15.3 翻译函数
- 两种分词方法的总结
- 1、tfds.features.text.Tokenizer() 函数
- 2、使用 tf.keras.preprocessing.text.Tokenizer 类
项目介绍
我们将训练一个 Transformer 模型 用于将葡萄牙语翻译成英语。在此之前,建议先了解有关文本生成和注意力机制的相关内容。
Transformer 模型的核心思想是自注意力机制(self-attention)——能注意输入序列的不同位置以计算该序列的表示的能力。Transformer 创建了多层自注意力层(self-attetion layers)组成的堆栈,下文的按比缩放的点积注意力(Scaled dot product attention)和多头注意力(Multi-head attention)部分对此进行了说明。
一个 transformer 模型用自注意力层而非 RNNs 或 CNNs 来处理变长的输入。这种通用架构有一系列的优势:
- 它不对数据间的时间/空间关系做任何假设。这是处理一组对象(objects)的理想选择(例如,星际争霸单位(StarCraft units))。
- 层输出可以并行计算,而非像 RNN 这样的序列计算。
- 远距离项可以影响彼此的输出,而无需经过许多 RNN 步骤或卷积层(例如,参见场景记忆 Transformer(Scene Memory Transformer))
- 它能学习长距离的依赖。在许多序列任务中,这是一项挑战。
该架构的缺点是:
- 对于时间序列,一个单位时间的输出是从整个历史记录计算的,而非仅从输入和当前的隐含状态计算得到。这可能效率较低。
- 如果输入确实有时间/空间的关系,像文本,则必须加入一些位置编码,否则模型将有效地看到一堆单词。
训练完模型后,您将能输入葡萄牙语句子,得到其英文翻译。
代码实现
1、导入需要的库
import tensorflow_datasets as tfds
import tensorflow as tf
import time
import numpy as np
import matplotlib.pyplot as plt
2、导入数据集
在这里我们使用 tensorflow_datasets 来导入 葡萄牙语-英语翻译数据集,该数据集来自于 TED 演讲开放翻译项目.
该数据集包含来约 50000 条训练样本,1100 条验证样本,以及 2000 条测试样本。
examples, metadata = tfds.load('ted_hrlr_translate/pt_to_en', with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']
train_examples
<_OptionsDataset shapes: ((), ()), types: (tf.string, tf.string)>
此时得到的 train_examples 和 val_examples 的类型都是 dataset,所以我们可以用它的 take 属性打印其中一个样本:
for pt, en in train_examples.take(1):
print(pt)
print(en)
tf.Tensor(b'os astr\xc3\xb3nomos acreditam que cada estrela da gal\xc3\xa1xia tem um planeta , e especulam que at\xc3\xa9 um quinto deles tem um planeta do tipo da terra que poder\xc3\xa1 ter vida , mas ainda n\xc3\xa3o vimos nenhum deles .', shape=(), dtype=string)
tf.Tensor(b"astronomers now believe that every star in the galaxy has a planet , and they speculate that up to one fifth of them have an earth-like planet that might be able to harbor life , but we have n't seen any of them .", shape=(), dtype=string)
3、将文本编码成数字形式
在这里我们使用两种方法实现目的,它们的不同之处会在文章末尾给出总结。
3.1 使用 tfds.features.text.Tokenizer() 函数
3.1.1 建立词汇表并统计词汇表中的单词数量
tokenizer_pt = tfds.features.text.Tokenizer()
tokenizer_en = tfds.features.text.Tokenizer()
vocabulary_set_pt = set()
vocabulary_set_en = set()
for pt, en in train_examples:
some_tokens_en = tokenizer_en.tokenize(en.numpy())
vocabulary_set_en.update(some_tokens_en)
some_tokens_pt = tokenizer_pt.tokenize(pt.numpy())
vocabulary_set_pt.update(some_tokens_pt)
vocab_size_en = len(vocabulary_set_en)
vocab_size_pt = len(vocabulary_set_pt)
vocab_size_en
26595
其中 tokenizer = tfds.features.text.Tokenizer() 的目的是实例化一个分词器,tokenizer.tokenize 可以将一句话分成多个单词。
3.1.2 建立编码器
encoder_en = tfds.features.text.TokenTextEncoder(vocabulary_set_en)
encoder_pt = tfds.features.text.TokenTextEncoder(vocabulary_set_pt)
我们可以拿一个样本实验:
sample_string = next(iter(train_examples))[1].numpy()
print ('The sample string: {}'.format(sample_string))
tokenized_string = encoder_en.encode(sample_string)
print ('Tokenized string is {}'.format(tokenized_string))
original_string = encoder_en.decode(tokenized_string)
print ('The original string: {}'.format(original_string))
The sample string is b"except , i 've never lived one day of my life there ."
Tokenized string is [21883, 16754, 12892, 4950, 23143, 10288, 15354, 2589, 5321, 25368, 14355]
The original string is except i ve never lived one day of my life there
然后,我们将编码器写成函数供以后调用:
def encode(lang1, lang2):
lang1 = [encoder_pt.vocab_size] + encoder_pt.encode(
lang1.numpy()) + [encoder_pt.vocab_size+1]
lang2 = [encoder_en.vocab_size] + encoder_en.encode(
lang2.numpy()) + [encoder_en.vocab_size+1]
return lang1, lang2
这里要将开始和结束标记添加到输入和目标,所以要在原来的 encoder_pt.encode(lang1.numpy()) 前后加上两个新的数字,假设 encoder_pt 中一共有 n 个单词,那么开始标记被记为 n,结束标记被记为 n+1。
3.1.3 对所有样本进行编码
这里可以参考文章Tensorflow2.0加载和预处理数据的方法汇总中的第七部分,其中对以下代码中使用的函数做了详细说明。
3.1.3.1 删除过长的样本
为了使训练速度变快,我们删除长度大于40个单词的样本。
MAX_LENGTH = 40
def filter_max_length(x, y, max_length=MAX_LENGTH):
return tf.logical_and(tf.size(x) <= max_length,
tf.size(y) <= max_length)
3.1.3.2 编码函数
def tf_encode(pt, en):
result_pt, result_en = tf.py_function(encode, [pt, en], [tf.int64, tf.int64])
result_pt.set_shape([None])
result_en.set_shape([None])
return result_pt, result_en
3.1.3.3 将样本打乱、分批
BUFFER_SIZE = 20000
BATCH_SIZE = 64
train_dataset = train_examples.map(tf_encode)
train_dataset = train_dataset.filter(filter_max_length)
# 将数据集缓存到内存中以加快读取速度。
train_dataset = train_dataset.cache()
train_dataset = train_dataset.shuffle(BUFFER_SIZE).padded_batch(BATCH_SIZE, ((None, ), (None, )))
train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)
val_dataset = val_examples.map(tf_encode)
val_dataset = val_dataset.filter(filter_max_length).padded_batch(BATCH_SIZE, ((None, ), (None, )))
此时,我们得到的最终 train_dataset 和 val_dataset 中的样本已经从文本转换成了数字向量:
pt_batch, en_batch = next(iter(train_dataset))
pt_batch, en_batch
(<tf.Tensor: id=884035, shape=(64, 38), dtype=int64, numpy=
array([[37503, 22040, 25913, ..., 0, 0, 0],
[37503, 14863, 33404, ..., 0, 0, 0],
[37503, 27883, 1899, ..., 0, 0, 0],
...,
[37503, 11538, 37504, ..., 0, 0, 0],
[37503, 25837, 27826, ..., 0, 0, 0],
[37503, 37130, 6792, ..., 0, 0, 0]], dtype=int64)>,
<tf.Tensor: id=884036, shape=(64, 36), dtype=int64, numpy=
array([[26597, 24117, 14025, ..., 0, 0, 0],
[26597, 6900, 22616, ..., 0, 0, 0],
[26597, 436, 15562, ..., 0, 0, 0],
...,
[26597, 1627, 26598, ..., 0, 0, 0],
[26597, 5490, 16754, ..., 0, 0, 0],
[26597, 7492, 15118, ..., 0, 0, 0]], dtype=int64)>)
可见该批次中葡萄牙语样本(输入样本)的最大长度为 38 个字母,英语样本(目标样本)的最大长度为 36 个字母。
3.2 使用 tf.keras.preprocessing.text.Tokenizer 类
3.2.1 将样本写入元组
我们需要返回这样格式的单词对:[葡萄牙语, 英语]。
因为 Tokenizer 类中的方法 fit_on_texts() 需要输入列表或元组,所以要将 train_examples 数据集中的样本写入元组。
def create_dataset(dataset):
word_pairs = [[pt.numpy().decode('utf-8'), en.numpy().decode('utf-8')] for pt, en in dataset]
return zip(*word_pairs)
将数据集输入后得到:
pt, en = create_dataset(train_examples)
pt[:3]
('os astrónomos acreditam que cada estrela da galáxia tem um planeta , e especulam que até um quinto deles tem um planeta do tipo da terra que poderá ter vida , mas ainda não vimos nenhum deles .',
'o problema é que nunca vivi lá um único dia .',
'agora aqui temos imagens sendo extraídas em tempo real diretamente do feed ,')
3.2.2 生成词典并将文本转化为数字向量
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,
padding='post')
return tensor, lang_tokenizer
3.2.3 将数据集全部转化为数字向量
def load_dataset(dataset):
# 创建经过处理后的输入输出对
inp_lang, targ_lang = create_dataset(dataset)
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
input_tensor_train, target_tensor_train, inp_lang, targ_lang = load_dataset(train_examples)
3.2.4 将样本打乱、分批
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 64
steps_per_epoch = len(input_tensor_train)//BATCH_SIZE
embedding_dim = 256
units = 1024
vocab_inp_size = len(inp_lang.word_index)+1
vocab_tar_size = len(targ_lang.word_index)+1
dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
4、位置编码
因为该模型并不包括任何的循环神经网络,所以此模型中不包括任何的词序信息,而这些信息是非常重要的。
比如一个单词在句子中的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like apple, but I do like banana.
I do like apple, but I do not like banana.
上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,我们需要引入词序信息来区别这两句话的意思。
所以模型添加了位置编码,为模型提供一些关于单词在句子中相对位置的信息。
Transformer 模型本身不具备像循环神经网络那样的学习词序信息的能力,所以我们需要主动地将词序信息输入模型。那么,模型原先的输入是不含词序信息的词向量,位置编码需要将词序信息和词向量结合起来形成一种新的表示输入给模型(在编码器和解码器中使用),这样模型就具备了学习词序信息的能力。
计算位置编码的公式如下:

其中, p o s pos pos 是单词的位置索引,设句子长度为 L L L,那么 p o s = 0 , 1 , . . . , L − 1 pos=0,1,...,L−1 pos=0,1,...,L−1。 i i i 是向量的某一维度,假设词向量维度 d m o d e l = 512 d_{model}=512 dmodel=512,那么 i = 0 , 1 , . . . , 255 i=0,1,...,255 i=0,1,...,255。
举例来说,假设 d m o d e l = 5 d_{model}=5 dmodel=5,那么在一个样本中:
第一个单词的位置编码为:
[ s i n ( 0 1000 0 2 × 0 5 ) c o s ( 0 1000 0 2 × 0 5 ) s i n ( 0 1000 0 2 × 1 5 ) c o s ( 0 1000 0 2 × 1 5 ) s i n ( 0 1000 0 2 × 2 5 ) ] \begin{bmatrix} sin(\frac{0}{10000^{\frac{2\times 0}{5}}}) & cos(\frac{0}{10000^{\frac{2\times 0}{5}}}) & sin(\frac{0}{10000^{\frac{2\times 1}{5}}}) & cos(\frac{0}{10000^{\frac{2\times 1}{5}}}) & sin(\frac{0}{10000^{\frac{2\times 2}{5}}}) \\ \end{bmatrix} [sin(1000052×00)cos(1000052×00)sin(1000052×10)cos(1000052×10)sin(1000052×20)]
第二个单词的位置编码为:
[ s i n ( 1 1000 0 2 × 0 5 ) c o s ( 1 1000 0 2 × 0 5 ) s i n ( 1 1000 0 2 × 1 5 ) c o s ( 1 1000 0 2 × 1 5 ) s i n ( 1 1000 0 2 × 2 5 ) ] \begin{bmatrix} sin(\frac{1}{10000^{\frac{2\times 0}{5}}}) & cos(\frac{1}{10000^{\frac{2\times 0}{5}}}) & sin(\frac{1}{10000^{\frac{2\times 1}{5}}}) & cos(\frac{1}{10000^{\frac{2\times 1}{5}}}) & sin(\frac{1}{10000^{\frac{2\times 2}{5}}}) \\ \end{bmatrix} [sin(1000052×01)cos(1000052×01)sin(1000052×11)cos(1000052×11)sin(1000052×21)]
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# 将 sin 应用于数组中的偶数索引(indices);2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 将 cos 应用于数组中的奇数索引;2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
5、遮挡(Masking)
5.1 填充遮挡
遮挡一批序列中所有的填充标记(即将文本转换到数字向量后标记为零的位置)。这确保了模型不会将填充作为输入。在填充值 0 出现的位置 mask 输出 1,否则输出 0。
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# 添加额外的维度来将填充加到
# 注意力对数(logits)。
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
5.2 前瞻遮挡
前瞻遮挡用于遮挡未来的信息。这意味着,如果要预测第三个词,将仅使用第一个和第二个词。与此类似,预测第四个词,仅使用第一个,第二个和第三个词,依此类推。 举例来说:
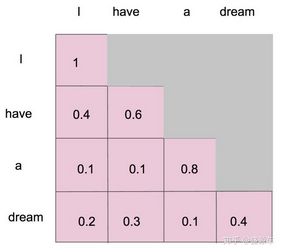
比如说输入是一句话 “I have a dream” 总共4个单词, 这里就会形成一张4x4的注意力机制(在下面介绍)的图。
I 作为第一个单词,只能有和 I 自己的 attention。have 作为第二个单词,有和 I, have 两个 attention。 a 作为第三个单词,有和 I, have, a 前面三个单词的 attention。到了最后一个单词 dream 的时候,才有对整个句子 4 个单词的 attention。
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
这里的 tf.linalg.band_part(input, num_lower, num_upper) 函数可以返回一个三角矩阵,input 是输入的矩阵;num_lower 是下三角中保留的行数;num_upper 是上三角中保留的行数,当 num_lower 或 num_upper 等于 -1 时,表示下三角或上三角全部保留。
5.3 生成所有遮挡
def create_masks(inp, tar):
# 编码器填充遮挡
enc_padding_mask = create_padding_mask(inp)
# 在解码器的第二个注意力模块使用。
# 该填充遮挡用于遮挡编码器的输出。
dec_padding_mask = create_padding_mask(inp)
# 在解码器的第一个注意力模块使用。
# 用于填充(pad)和遮挡(mask)解码器获取到的输入的后续标记(future tokens)。
look_ahead_mask = create_look_ahead_mask(tf.shape(tar)[1])
dec_target_padding_mask = create_padding_mask(tar)
combined_mask = tf.maximum(dec_target_padding_mask, look_ahead_mask)
return enc_padding_mask, combined_mask, dec_padding_mask
在编码器中,我们对其中唯一的注意力模块使用填充遮挡;在解码器中,我们对其中第一个注意力模块使用填充遮挡和前瞻遮挡,对第二个注意力模块使用填充遮挡。
6、Scaled dot-product attention
Scaled dot-product attention 的结构为:
 Transformer 使用的注意力函数有三个输入:Q(请求(query))、K(主键(key))、V(数值(value))。用于计算注意力权重的等式为:
Transformer 使用的注意力函数有三个输入:Q(请求(query))、K(主键(key))、V(数值(value))。用于计算注意力权重的等式为:

这里的 d k d_k dk 其实就是词嵌入向量的维度 d m o d e l d_{model} dmodel。
假设 Q 和 K 的均值为0,方差为1。它们的矩阵乘积将有均值为0,方差为 d k d_k dk。因此, d k d_k dk 的平方根被用于缩放,因为,Q 和 K 的矩阵乘积的均值本应该为 0,方差本应该为1,这样会获得一个更平缓的 softmax。
def scaled_dot_product_attention(q, k, v, mask):
"""计算注意力权重。
q, k, v 必须具有匹配的前置维度。
k, v 必须有匹配的倒数第二个维度,例如:seq_len_k = seq_len_v。
虽然 mask 根据其类型(填充或前瞻)有不同的形状,
但是 mask 必须能进行广播转换以便求和。
参数:
q: 请求的形状 == (..., seq_len_q, depth)
k: 主键的形状 == (..., seq_len_k, depth)
v: 数值的形状 == (..., seq_len_v, depth_v)
mask: Float 张量,其形状能转换成
(..., seq_len_q, seq_len_k)。默认为None。
返回值:
输出,注意力权重
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# 缩放 matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 将 mask 加入到缩放的张量上。
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax 在最后一个轴(seq_len_k)上归一化,因此分数
# 相加等于1。
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
在这里我们将遮挡(mask)与 -1e9(接近于负无穷)相乘,其目标是将这些单元在 softmax 中归零,因为 softmax 的较大负数输入在输出中接近于零。
当 softmax 在 K 上进行归一化后,它的值决定了将 K 对应的 V 分配到 Q 的重要程度。
输出表示注意力权重和 V(数值)向量的乘积。这使得要关注的词保持原样,而无关的词将被清除掉。所以它的机制可以被理解为:

7、Multi-head attention(多头注意力)
在上一部分中,我们介绍了注意力函数的三个输入为:Q(请求(query))、K(主键(key))、V(数值(value)),那么这些值是怎么来的呢?
其实,这些值是将经过处理后的文本经过 Dense 层后得到的,这些处理包括:词嵌入、位置编码等。也就是:

当然,这里的 X 不一定相同,如果相同,我们称其为 self-attention。
Multi-head attention 就是把上面的 Scaled dot-product attention 操作执行 H 次,然后把输出合并,如下图所示:

举例来说,如果 H=8,那么我们要将 V,K,Q 各分成 8 份,对每一份进行 Scaled dot-product attention 操作,最后将得到的结果合并起来。
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""分拆最后一个维度到 (num_heads, depth).
转置结果使得形状为 (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
8、Position-wise feed-forward networks(点式前馈网络)
这层主要是提供非线性变换,是一个全连接层,在编码器和解码器的最后都要使用。
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
对此过程中的维度变化进行分析:

9、编码与解码

- 输入语句经过 N 个编码器层,为序列中的每个词生成一个输出。
- 解码器使用编码器的输出以及它自身的输入(即目标语句的自注意力)来预测下一个词。
9.1 编码器层
每个编码器层包括以下子层:
- 多头注意力(包括填充遮挡);
- 点式前馈网络。
其中的多头注意力其实是输入语句的自注意力,编码器层的输出将会被输入解码器层。
每个子层在其周围有一个残差连接,然后进行层归一化。残差连接有助于避免深度网络中的梯度消失问题。
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
9.2 解码器层
每个解码器层包括以下子层:
- 第一个多头注意力(包括前瞻遮挡和填充遮挡);
- 第二个多头注意力(包括填充遮挡);
- 点式前馈网络。
其中,第一个多头注意力其实是目标语句的自注意力,它的 V,K 和 Q 都是来源于目标语句;而第二个多头注意力的 V 和 K 接收编码器输出(即输入语句的自注意力)作为输入。Q 接收第一个多头注意力的输出作为输入。
每个子层在其周围有一个残差连接,然后进行层归一化。
当 Q 接收到解码器的第一个自注意力块的输出,并且 K 接收到编码器的输出时,注意力权重表示根据编码器的输出赋予解码器输入不同的重要性。换一种说法,解码器通过查看编码器输出和对其自身输出的自注意力来预测下一个词。
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
对编码器层和解码器层中的维度变化进行分析:

9.3 编码器
编码器包括:
- 输入嵌入;
- 位置编码;
- N 个编码器层。
将输入经过词嵌入层后,再把该嵌入与位置编码相加。该加法操作的输出是编码器层的输入。编码器的输出是解码器的输入。
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding,
self.d_model)
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
# 将嵌入和位置编码相加。
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, d_model)
9.4 解码器
解码器包括:
- 输出嵌入;
- 位置编码;
- N 个解码器层。
将目标语句经过词嵌入层后,再把该嵌入与位置编码相加。该加法操作的结果是解码器层的输入。解码器的输出是最后的线性层的输入。
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size,
maximum_position_encoding, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, training,
look_ahead_mask, padding_mask)
attention_weights['decoder_layer{}_block1'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2'.format(i+1)] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
对编码器和解码器中的维度变化进行分析:

10、创建 Transformer
Transformer 包括编码器,解码器和最后的线性层。编码器的输出是解码器的输入,解码器的输出是线性层的输入,返回线性层的输出。
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff,
input_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask,
look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(inp, training, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(
tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attention_weights
对此过程中的维度变化进行分析:

11、配置超参数
超参数包括:
- num_layers:编码器层数和解码器层数;
- d_model:词嵌入维度;
- dff:点式前馈网络中第一个全连接层的神经元个数;
- num_heads:多头注意力中的头数;
- input_vocab_size:输入样本中单词的个数(含开头标记与结尾标记);
- target_vocab_size:目标样本中单词的个数(含开头标记与结尾标记);
- dropout_rate。
num_layers = 4
d_model = 128
dff = 512
num_heads = 8
input_vocab_size = tokenizer_pt.vocab_size + 2
target_vocab_size = tokenizer_en.vocab_size + 2
dropout_rate = 0.1
12、优化器
在这里我们使用 Adam 优化器,但我们规定学习率为:
![]()
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps ** -1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98,
epsilon=1e-9)
通过打印学习率随训练次数的变化,我们可以看到学习率的变化趋势:
temp_learning_rate_schedule = CustomSchedule(d_model)
plt.plot(temp_learning_rate_schedule(tf.range(40000, dtype=tf.float32)))
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")

13、损失函数与指标
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
在这里我们使用了遮挡(mask),这样就可以把我们填充的位置的损失置为0。
14、训练
14.1 检查点
transformer = Transformer(num_layers, d_model, num_heads, dff,
input_vocab_size, target_vocab_size,
pe_input=input_vocab_size,
pe_target=target_vocab_size,
rate=dropout_rate)
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(transformer=transformer,
optimizer=optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# 如果检查点存在,则恢复最新的检查点。
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
14.2 梯度下降
目标语句被分成了 tar_inp 和 tar_real。tar_inp 作为输入被传递到解码器。tar_real 是位移了 1 的同一个输入:在 tar_inp 中的每个位置,tar_real 包含了应该被预测到的下一个标记。
例如,目标语句为 “SOS A lion in the jungle is sleeping EOS”,那么:
tar_inp = “SOS A lion in the jungle is sleeping”
tar_real = “A lion in the jungle is sleeping EOS”
Transformer 是一个自回归模型:它一次作一个部分的预测,然后使用到目前为止的自身的输出来决定下一步要做什么。
在训练过程中,我们使用了 teacher-forcing 的方法。无论模型在当前时间步骤下预测出什么,teacher-forcing 方法都会将真实的输出传递到下一个时间步骤上。
当 Transformer 预测每个词时,自注意力(self-attention)功能使它能够查看输入序列中前面的单词,从而更好地预测下一个单词。
# 该 @tf.function 将追踪-编译 train_step 到 TF 图中,以便更快地
# 执行。该函数专用于参数张量的精确形状。为了避免由于可变序列长度或可变
# 批次大小(最后一批次较小)导致的再追踪,使用 input_signature 指定
# 更多的通用形状。
train_step_signature = [
tf.TensorSpec(shape=(None, None), dtype=tf.int64),
tf.TensorSpec(shape=(None, None), dtype=tf.int64),
]
@tf.function(input_signature=train_step_signature)
def train_step(inp, tar):
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
enc_padding_mask, combined_mask, dec_padding_mask = create_masks(inp, tar_inp)
with tf.GradientTape() as tape:
predictions, _ = transformer(inp, tar_inp,
True,
enc_padding_mask,
combined_mask,
dec_padding_mask)
loss = loss_function(tar_real, predictions)
gradients = tape.gradient(loss, transformer.trainable_variables)
optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))
train_loss(loss)
train_accuracy(tar_real, predictions)
14.3 训练
EPOCHS = 20
for epoch in range(EPOCHS):
start = time.time()
train_loss.reset_states()
train_accuracy.reset_states()
# inp -> portuguese, tar -> english
for (batch, (inp, tar)) in enumerate(train_dataset):
train_step(inp, tar)
if batch % 50 == 0:
print ('Epoch {} Batch {} Loss {:.4f} Accuracy {:.4f}'.format(
epoch + 1, batch, train_loss.result(), train_accuracy.result()))
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Epoch {} Loss {:.4f} Accuracy {:.4f}'.format(epoch + 1,
train_loss.result(),
train_accuracy.result()))
print ('Time taken for 1 epoch: {} secs\n'.format(time.time() - start))
15、评估
以下步骤用于评估:
- 用葡萄牙语编码器(encoder_pt)编码输入语句。此外,添加开始和结束标记,这样输入就与模型训练的内容相同。
- 解码器的第一个输入为英语的开始标记,即tokenizer_en.vocab_size。
- 计算填充遮挡和前瞻遮挡。
- 解码器通过查看编码器输出和它自身的输出(自注意力)给出预测。
- 选择最后一个词并计算它的 argmax。
- 将预测的词连接到解码器输入,然后传递给解码器。
- 在这种方法中,解码器根据它预测的之前的词预测下一个。
15.1 评估函数
def evaluate(inp_sentence):
start_token = [encoder_pt.vocab_size]
end_token = [encoder_pt.vocab_size + 1]
# 输入语句是葡萄牙语,增加开始和结束标记
inp_sentence = start_token + encoder_pt.encode(inp_sentence) + end_token
encoder_input = tf.expand_dims(inp_sentence, 0)
# 因为目标是英语,输入 transformer 的第一个词应该是
# 英语的开始标记。
decoder_input = [encoder_en.vocab_size]
output = tf.expand_dims(decoder_input, 0)
for i in range(MAX_LENGTH):
enc_padding_mask, combined_mask, dec_padding_mask = create_masks(
encoder_input, output)
# predictions.shape == (batch_size, seq_len, vocab_size)
predictions, attention_weights = transformer(encoder_input,
output,
False,
enc_padding_mask,
combined_mask,
dec_padding_mask)
# 从 seq_len 维度选择最后一个词
predictions = predictions[: ,-1:, :] # (batch_size, 1, vocab_size)
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)
# 如果 predicted_id 等于结束标记,就返回结果
if predicted_id == encoder_en.vocab_size+1:
return tf.squeeze(output, axis=0), attention_weights
# 连接 predicted_id 与输出,作为解码器的输入传递到解码器。
output = tf.concat([output, predicted_id], axis=-1)
return tf.squeeze(output, axis=0), attention_weights
15.2 注意力权重图
def plot_attention_weights(attention, sentence, result, layer):
fig = plt.figure(figsize=(16, 8))
sentence = tokenizer_pt.encode(sentence)
attention = tf.squeeze(attention[layer], axis=0)
for head in range(attention.shape[0]):
ax = fig.add_subplot(2, 4, head+1)
# 画出注意力权重
ax.matshow(attention[head][:-1, :], cmap='viridis')
fontdict = {'fontsize': 10}
ax.set_xticks(range(len(sentence)+2))
ax.set_yticks(range(len(result)))
ax.set_ylim(len(result)-1.5, -0.5)
ax.set_xticklabels(
['' ]+[tokenizer_pt.decode([i]) for i in sentence]+['' ],
fontdict=fontdict, rotation=90)
ax.set_yticklabels([tokenizer_en.decode([i]) for i in result
if i < tokenizer_en.vocab_size],
fontdict=fontdict)
ax.set_xlabel('Head {}'.format(head+1))
plt.tight_layout()
plt.show()
15.3 翻译函数
def translate(sentence, plot=''):
result, attention_weights = evaluate(sentence)
predicted_sentence = encoder_en.decode([i for i in result
if i < encoder_en.vocab_size])
print('Input: {}'.format(sentence))
print('Predicted translation: {}'.format(predicted_sentence))
if plot:
plot_attention_weights(attention_weights, sentence, result, plot)
我们可以输入一句葡萄牙语尝试翻译:
translate("este é um problema que temos que resolver.")
print ("Real translation: this is a problem we have to solve .")
Input: este é um problema que temos que resolver.
Predicted translation: this is a problem that we have to solve
Real translation: this is a problem we have to solve .
可见翻译得还是比较准确的。
两种分词方法的总结
1、tfds.features.text.Tokenizer() 函数
tokenizer = tfds.features.text.Tokenizer()
vocabulary_set = set()
for text_tensor, _ in all_labeled_data:
some_tokens = tokenizer.tokenize(text_tensor.numpy())
vocabulary_set.update(some_tokens)
其中 vocabulary_set 是词汇表,集合形式。
text_tensor.numpy() 不需要被 decode 为 utf-8。
encoder = tfds.features.text.TokenTextEncoder(vocabulary_set) 得到编码器。
encoder.encode(文本) --> 数字向量
encoder.decode(数字向量) --> 文本
因为每个样本的长度不同,所以在设置 batch 的时候要用 .padded_batch。
2、使用 tf.keras.preprocessing.text.Tokenizer 类
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
lang_tokenizer.fit_on_texts(targ_lang)
tensor1 = lang_tokenizer.texts_to_sequences(targ_lang) # 文本 --> 数字向量
tensor2 = tf.keras.preprocessing.sequence.pad_sequences(tensor1, padding='post') # 用0填充
# convert函数:数字向量 --> 文本
def convert(lang, tensor):
for t in tensor:
if t!=0:
print ("%d ----> %s" % (t, lang.index_word[t]))
其中的targ_lang是一个包含所有样本的列表,且列表中的元素需被 decode 为 utf-8。
lang_tokenizer.index_word 是词汇表,字典形式。
因为这里已经用0填充了,所以在设置 batch 的时候直接用 .batch 即可,不用 .padded_batch。