使用scrapy框架爬虫并将数据保存到MySQL数据库
作者寄语:
这两天主要研究了一下爬虫,看了一些爬虫代码,整理了一些最简单的爬虫入门,也遇到很多坑,希望能帮助和我一样的初学者。
这篇文章主要讲了如何使用python实现简单的爬虫,并将爬取的数据保存到数据库中,使其结构化,因为平时爬取的文件结果多以json文件为主,有时使用时不太方便。保存到数据库里,可以更方便使用。
废话不多说,开始操作:
环境搭建:
1.python3.6版本
2.pycharm编辑器(别的编辑器也可以)。
3.mySQL数据库
4.navicat for mysql
5.scrapy爬虫框架
下载这块就不多说了,网上很多下载安装教程及解决方案。遇到问题不要着急,根据报错信息查找解决。
操作步骤:
一.爬虫的实现
1.首先我们使用命令行新建一个scrapy项目。windows使用win+R,输入cmd,进入终端。进入你想创建项目的文件目录,输入scrapy start project hellospider(文件名),等待scrapy自动生成文件,此时使用编辑器打开hellospider文件,你会看这样的结构:

2.接下来,在spiders文件夹下创建myspider.py文件,文件内容如下:
import scrapy
from hellospider.items import DetailItem
#上一行不同版本的python可能会出现红色波浪线,不用管
class MySpider(scrapy.Spider):
"""
name:scrapy唯一定位实例的属性,必须唯一
allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
start_urls:起始爬取列表
"""
# 设置name
name = "spidertieba"
# 设定域名
allowed_domains = ["baidu.com"]
#设置爬取地址列表
box = []
for num in range(301):
if num % 50 ==0:
pages = 'http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=utf-8&&pn={0}'.format(num)
box.append(pages)
else:
continue
# 填写爬取地址
start_urls = box
#print(box) 用于测试
# 编写爬取方法
def parse(self, response):
for line in response.xpath('//li[@class=" j_thread_list clearfix"]'):
# 初始化item对象保存爬取的信息
item = DetailItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# item['id'] = line.xpath(
# './/div[contains(@class,"threadlist_title pull_left j_th_tit ")]/a/@href').extract()[0][3:6]
item['title'] = line.xpath(
'.//div[contains(@class,"threadlist_title pull_left j_th_tit ")]/a/text()').extract()[0]
item['author'] = line.xpath(
'.//div[contains(@class,"threadlist_author pull_right")]//span[contains(@class,"frs-author-name-wrap")]/a/text()').extract()[0]
item['reply'] = line.xpath(
'.//div[contains(@class,"col2_left j_threadlist_li_left")]/span/text()').extract()[0]
yield item
3.修改items.py文件,文件内容如下:
import scrapy
class DetailItem(scrapy.Item):
# 抓取内容:1.帖子标题;2.帖子作者;3.帖子回复数
title = scrapy.Field()
author = scrapy.Field()
reply = scrapy.Field()
4.此时你可以通过命令行“scrapy crawl spidertieba”注意运行的要与py文件中的name值相同,运行爬虫文件查看爬取过程打印的日志。这仅仅实现了爬虫,接下来我们继续说怎样将爬取的数据保存到mysql中。
二.将数据保存到MySQL
1.通过查看爬取的数据的形式,在数据库可视化工具或直接通过命令行创建数据库。
初学者可以使用navicat直接连接数据库,点击右键会出现新建数据库,新建表,并且可以定义表的结构。这个方法比较简单。
第二种方式是进入mysql终端,登陆后,使用“CREATE DATABASE tieba(数据库名);”创建数据库,输入“USE tieba”使用数据库;使用“REATE TABLE articles (id BIGINT(5) NOT NULL AUTO_INCREMENT, reply VARCHAR(100), author VARCHAR(100), )”创建表,定义表结构,表结构要和你爬取数据的结构相对应。可通过“DESCRIBE articles”查看表结构。
2.建立好数据表后,就可以编辑pipelines.py文件,实现将爬虫与数据库相连接。文件内容如下:
import pymysql
#连接数据库
def dbHandle():
conn = pymysql.connect(
host = "localhost",
user = "****",
passwd = "******",
charset = "utf8",
use_unicode = False
)
return conn
class HellospiderPipeline(object):
def process_item(self, item, spider):
dbObject = dbHandle()
cursor = dbObject.cursor()
cursor.execute("USE tieba")
#插入数据库
sql = "INSERT INTO articles(title,author,reply) VALUES(%s,%s,%s)"
try:
cursor.execute(sql,
( item['title'], item['author'], item['reply']))
cursor.connection.commit()
except BaseException as e:
print("错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")
dbObject.rollback()
return item
3.设置settings.py文件,文件内容如下:
USER_AGENT: 'Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36'
ITEM_PIPELINES = {
'hellospider.pipelines.HellospiderPipeline': 300,
}
ROBOTSTXT_OBEY = False
最后,就可以在命令行通过scrapy crawl spidertieba 来见证神奇的一刻啦,你会看到navicat数据表里多了你想要爬取的数据,如果数据表没有数据,可以尝试关闭重新连接一下数据库。
运行结果如下:
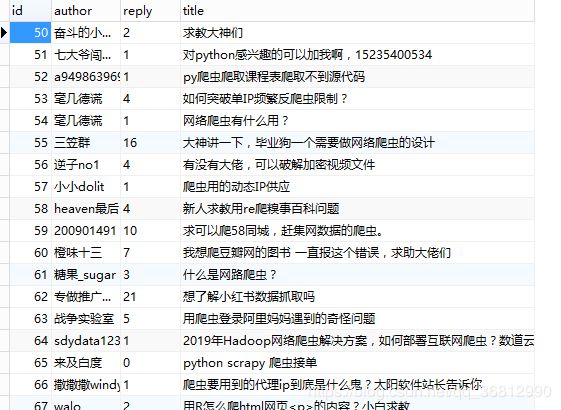
遇到的坑:
安装完成后运行程序,程序报错,报错信息为 KeyError:255
解决方案是使用 pip 更新一下 PyMSQL,命令为’python3 -m pip install --upgrade PyMySQL’
本文参考链接:
利用scrapy爬取简书文章并保存到数据库
下载工具参考链接:
scrapy