Spark大数据分布式处理实战笔记(四):Spark Streaming

前言
Spark是一种大规模、快速计算的集群平台,本公众号试图通过学习Spark官网的实战演练笔记提升笔者实操能力以及展现Spark的精彩之处。有关框架介绍和环境配置可以参考以下内容:
1.大数据处理框架Hadoop、Spark介绍
2.linux下Hadoop安装与环境配置
3.linux下Spark安装与环境配置
本文的参考配置为:Deepin 15.11、Java 1.8.0_241、Hadoop 2.10.0、Spark 2.4.4、scala 2.11.12
本文的目录为:
一、流处理介绍及示例
1.流处理介绍
2.流处理示例
二、基础概念
1.初始化 StreamingContext
2.离散化流(Discretized Stream)
3.DataFrame 和 SQL 操作
4.MLlib 操作
5.缓存 / 持久性
6.建立检查点
7.应用程序部署与监控
三、性能调优
一、流处理介绍及示例
1.流处理介绍
Spark Streaming 是 Spark Core API 的扩展,它支持弹性的,高吞吐的,容错的实时数据流的处理。数据可以通过多种数据源获取,例如 Kafka,Flume,Kinesis 以及 TCP sockets,也可以通过例如 map,reduce,join,窗口函数等的高级函数组成的复杂算法处理。最终,处理后的数据可以输出到文件系统,数据库以及实时仪表盘中。事实上,你还可以在 data streams(数据流)上使用机器学习以及图计算算法。

在内部,它工作原理如下,Spark Streaming 接收实时输入数据流并将数据切分成多个 batch(批)数据,然后由 Spark 引擎处理它们以生成最终的分批流结果。

Spark Streaming 提供了一个名为 discretized stream 或 DStream 的高级抽象,它代表一个连续的数据流。本文将展示如何用DStream来编写一个 Spark Streaming 程序。
2.流处理示例
首先,我们将Spark Streaming类的名称以及从StreamingContext进行的一些隐式转换导入到我们的环境中,以便向我们需要的其他类(如DStream)添加有用的方法。StreamingContext是所有流功能的主要入口点。我们创建具有两个执行线程和1秒批处理间隔的本地StreamingContext。
import org.apache.spark._import org.apache.spark.streaming._import org.apache.spark.streaming.StreamingContext._// 考虑到套接字传输,设置master节点为local[2]scala> val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")conf: org.apache.spark.SparkConf = org.apache.spark.SparkConf@69c7eafd// 实例化ssc并设置为1s更新scala> val ssc = new StreamingContext(conf, Seconds(1))ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@5f606ab6
接着创建一个DStream,该DStream表示来自TCP源的流数据,指定为主机名(此处为localhost)和端口(此处为9999)。
scala> val lines = ssc.socketTextStream("localhost", 9999)lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@60eb9c29
此linesDStream表示将从数据服务器接收的数据流。此DStream中的每个记录都是一行文本。接下来,我们要通过空格字符将行拆分为单词。flatMap是一对多DStream操作,它通过从源DStream中的每个记录生成多个新记录来创建新的DStream。在这种情况下,每行将拆分为多个单词,单词流表示为 wordsDStream。接下来,我们要计算这些单词。
// 一对多操作scala> val words = lines.flatMap(_.split(" "))words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@6ef5e46a// 转换为[k,v]scala> val pairs = words.map(word => (word, 1))pairs: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.MappedDStream@561494af// 累加scala> val wordCounts = pairs.reduceByKey(_ + _)wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@546ab02b// 设置每秒输出scala> wordCounts.print()
执行这些行时,Spark Streaming仅设置启动时将执行的计算,并且尚未开始任何实际处理。此前我们需要通过使用以下命令将Netcat(在大多数类Unix系统中找到的一个小实用程序)作为数据服务器运行(并在输入框输入任意内容):
phenix@phenix-PC:~$ nc -lp 9999再从spark-shell中执行以下命令开启:
scala> ssc.start()scala> ssc.awaitTermination()-------------------------------------------Time: 1582619784000 ms--------------------------------------------------------------------------------------Time: 1582619785000 ms-------------------------------------------(spark,4)(hadoop,2)-------------------------------------------Time: 1582619786000 ms-------------------------------------------
此外,在spark内置示例中也有相应实现:
$phenix@phenix-PC:~$ /usr/local/spark/bin/run-example streaming.NetworkWordCount localhost 9999二、基础概念
1.初始化 StreamingContext
要初始化Spark Streaming程序,必须创建StreamingContext对象,该对象是所有Spark Streaming功能的主要入口点。
import org.apache.spark._import org.apache.spark.streaming._val conf = new SparkConf().setAppName(appName).setMaster(master)val ssc = new StreamingContext(conf, Seconds(1))
appName参数即为应用程序在集群UI上显示的名称。master是Spark,Mesos,Kubernetes或YARN群集URL或特殊的“ local [*]”字符串,以本地模式运行。以上命令会在内部创建一个SparkContext(所有Spark功能的起点),可以通过访问ssc.sparkContext。按上文定以后,必须执行以下操作:
-
通过创建输入DStream定义输入源。
-
通过将转换和输出操作应用于DStream来定义流计算。
-
开始接收数据并使用进行处理streamingContext.start()。
-
等待使用停止处理streamingContext.awaitTermination()。
-
可以使用手动停止处理streamingContext.stop()。
2.离散化流(Discretized Stream)
离散流或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示:
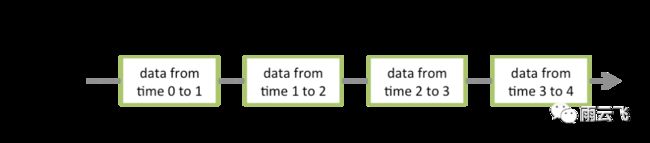
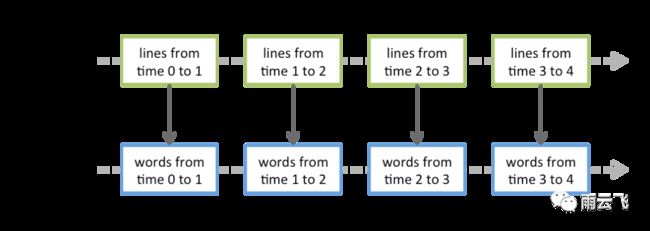
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,在较早的将行流转换为单词的示例中,将flatMap操作应用于linesDStream中的每个RDD 以生成DStream的 wordsRDD。如下图所示:
我们已经通过前文的入门示例了解到可以接收TCP套接字,除此之外,StreamingContext API还提供了从文件作为输入源创建DStream的方法(还有自定义流此处不做讨论)。对于文本数据,Spark Streaming将监视目录dataDirectory并处理在该目录中创建的所有文件:
streamingContext.textFileStream(dataDirectory)与 RDD 类似,transformation 允许从 input DStream 输入的数据做修改。DStreams 支持很多在 RDD 中可用的 transformation 算子。例如map、flatMap、filter、repatation、union、count、reduce、countByValue、reduceByKey、join、cogroup、transform、updateStateByKey等。
Spark Streaming还提供了窗口计算,可让您在数据的滑动窗口上应用转换。下图说明了此滑动窗口。:
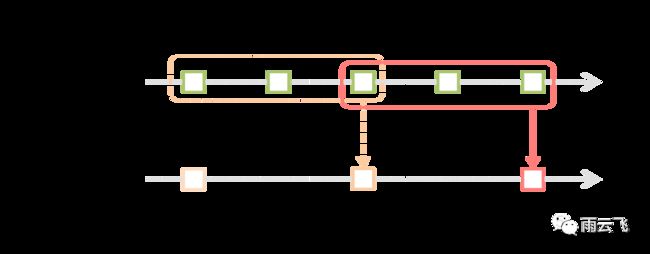
通过一个例子来说明窗口操作。假设我们想扩展前面的示例,方法是每10秒在数据的最后30秒生成一次字数统计。为此,我们必须在最后30秒的数据reduceByKey上对pairsDStream (word, 1)对应用该操作。这是通过操作完成的reduceByKeyAndWindow。
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))一些常见的窗口函数如下:
| 转换操作 | 含义 |
|---|---|
| window(windowLength,slideInterval) | 返回根据源DStream的窗口批处理计算的新DStream。 |
| countByWindow(windowLength,slideInterval) | 返回流中元素的滑动窗口计数。 |
| reduceByWindow(func,windowLength,slideInterval) | 返回一个新的单元素流,该流是通过使用func在滑动间隔内聚合流中的元素而创建的。 |
| reduceByKeyAndWindow(func,windowLength,slideInterval,[numTasks]) | 在(k,v)对的DStream上调用时,返回新的(K,V)对的DStream,其中使用给定的reduce函数func 在滑动窗口中的批处理上汇总每个键的值。 |
| countByValueAndWindow(windowLength, slideInterval,[ numTasks ]) | 在(k,v)对的DStream上调用时,返回新的(K,Long)对的DStream,其中每个键的值是其在滑动窗口内的频率。像in中一样 reduceByKeyAndWindow,reduce任务的数量可以通过可选参数配置。 |
输出操作允许将 DStream 的数据推送到外部系统,如数据库或文件系统。由于输出操作实际上允许外部系统使用变换后的数据,所以它们触发所有 DStream 变换的实际执行(类似于RDD的动作)。目前,定义了以下输出操作:
| 输出操作 | 含义 |
|---|---|
| print() | 在运行流应用程序的 driver 节点上的DStream中打印每批数据的前十个元素。 |
| saveAsTextFiles(prefix, [_suffix_]) | 将此 DStream 的内容另存为文本文件。 |
| saveAsObjectFiles(prefix, [_suffix_]) | 将此 DStream 的内容另存为序列化 Java 对象的 SequenceFiles。 |
| saveAsHadoopFiles(prefix, [_suffix_]) | 将此 DStream 的内容另存为 Hadoop 文件。 |
| foreachRDD(func) | 对从流中生成的每个 RDD 应用函数 func 的最通用的输出运算符。 |
dstream.foreachRDD是一个强大的语句,可以将数据发送到外部系统。但是,重要的是要了解如何正确有效地使用此语句。通常,将数据写入外部系统需要创建一个连接对象(例如,到远程服务器的TCP连接),并使用该对象将数据发送到远程系统。为此,开发人员可能会无意间尝试在Spark驱动程序中创建连接对象,然后尝试在Spark辅助程序中使用该对象以将记录保存在RDD中。例如在Scala中:
// 这样可以在多个记录上分摊连接创建开销。dstream.foreachRDD { rdd =>rdd.foreachPartition { partitionOfRecords =>val connection = createNewConnection()partitionOfRecords.foreach(record => connection.send(record))connection.close()}}
3.DataFrame 和 SQL 操作
我们可以轻松地在流数据上使用 DataFrames and SQL 和 SQL 操作。
/** DataFrame operations inside your streaming program */val words: DStream[String] = ...words.foreachRDD { rdd =>// Get the singleton instance of SparkSessionval spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()import spark.implicits._// Convert RDD[String] to DataFrameval wordsDataFrame = rdd.toDF("word")// Create a temporary viewwordsDataFrame.createOrReplaceTempView("words")// Do word count on DataFrame using SQL and print itval wordCountsDataFrame =spark.sql("select word, count(*) as total from words group by word")wordCountsDataFrame.show()}
4.MLlib 操作
我们还可轻松使用 MLlib 提供的机器学习算法。首先,有 streaming 机器学习算法(例如:Streaming 线性回归,Streaming KMeans 等),其可以同时从 streaming 数据中学习,并将该模型应用于 streaming 数据。除此之外,对于更大类的机器学习算法,您可以离线学习一个学习模型(即使用历史数据),然后将该模型在线应用于流数据。MLlib我们将在在下一节中进行详细展现。
5.缓存 / 持久性
与 RDD 类似,DStreams 还允许开发人员将流的数据保留在内存中。也就是说,在 DStream 上使用 persist() 方法会自动将该 DStream 的每个 RDD 保留在内存中。如果 DStream 中的数据将被多次计算(例如,相同数据上的多个操作),这将非常有用。对于基于窗口的操作,如 reduceByWindow 和 reduceByKeyAndWindow 以及基于状态的操作,如 updateStateByKey,这是隐含的。因此,基于窗口的操作生成的 DStream 会自动保存在内存中,而不需要开发人员调用 persist()。
对于通过网络接收数据(例如:Kafka,Flume,sockets 等)的输入流,默认持久性级别被设置为将数据复制到两个节点进行容错。
6.建立检查点
streaming 应用程序必须 24/7 运行,因此必须对应用逻辑无关的故障(例如,系统故障,JVM 崩溃等)具有弹性。为了可以这样做,Spark Streaming 需要 checkpoint 足够的信息到容错存储系统,以便可以从故障中恢复。checkpoint 有两种类型的数据。
-
Metadata checkpointing - 将定义 streaming 计算的信息保存到容错存储(如 HDFS)中。这用于从运行 streaming 应用程序的 driver 的节点的故障中恢复(稍后详细讨论)。
-
Data checkpointing - 将生成的 RDD 保存到可靠的存储。这在一些将多个批次之间的数据进行组合的 状态 变换中是必需的。在这种转换中,生成的 RDD 依赖于先前批次的 RDD,这导致依赖链的长度随时间而增加。为了避免恢复时间的这种无限增加(与依赖关系链成比例),有状态转换的中间 RDD 会定期 checkpoint 到可靠的存储(例如 HDFS)以切断依赖关系链。
对于具有以下任一要求的应用程序,必须启用 checkpoint:
-
使用状态转换 - 如果在应用程序中使用 updateStateByKey或 reduceByKeyAndWindow(具有反向功能),则必须提供 checkpoint 目录以允许定期的 RDD checkpoint。
-
从运行应用程序的 driver 的故障中恢复 - 元数据 checkpoint 用于使用进度信息进行恢复。
7.应用程序部署与监控
要运行 Spark Streaming 应用程序,您需要具备以下功能。
-
集群管理器集群
-
打包应用程序 JAR
-
为 executor 配置足够的内存
-
配置 checkpoint
-
配置应用程序 driver 的自动重新启动
-
配置预写日志
-
设置最大接收速率
当使用 StreamingContext 时,Spark web UI 显示一个额外的 Streaming 选项卡,显示 running receivers(运行接收器)的统计信息(无论是 receivers(接收器)是否处于 active(活动状态),接收到的 records(记录)数,receiver error(接收器错误)等)并完成 batches(批次)(batch processing times(批处理时间),queueing delays(排队延迟)等)。这可以用来监视 streaming application(流应用程序)的进度。
三、性能调优
在集群上的 Spark 流处理应用中获得最佳性能需要一些调整。宏观上可以这么考虑:
-
通过有效利用集群资源,减少每批数据的处理时间。
-
设置正确的批量大小,以便 批量的数据可以像被接收处理一样快(即数据处理与数据摄取保持一致)。
有关Spark Streaming的内容至此结束,下文将进一步对Spark MLlib即Spark机器学习的内容做详细介绍。
前文笔记请参考下面的链接:
Spark大数据分布式处理实战笔记(一):快速开始
Spark大数据分布式处理实战笔记(二):RDD、共享变量
Spark大数据分布式处理实战笔记(三):Spark SQL
你可能错过了这些~
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇
我就知道你“在看”
