2020 BAT大厂深度学习算法面试经验:“高频面经”之深度学习篇
注:深度学习同机器学习相似,注重原理理解、算法对比及多场景实战,同时知识迭代更加迅速,相对于机器学习更加前沿。以下试题为作者日常整理的通用高频面经,包含题目,答案与参考文章,欢迎纠正与补充。
其他相应高频面试题可参考如下内容:
2020 BAT大厂数据分析面试经验:“高频面经”之数据分析篇
2020 BAT大厂数据挖掘面试经验:“高频面经”之数据结构与算法篇
2020 BAT大厂数据开发面试经验:“高频面经”之大数据研发篇
2020 BAT大厂机器学习算法面试经验:“高频面经”之机器学习篇
目录
1.反向传播主要思想及推导
2.简要概述HMM、CRF、EM、GMM
3.衡量分类器好坏指标
4.正负样本不平衡的解决办法
5.常用激活函数
6.Tensorflow的工作原理
7.深度学习框架对比
8.ResNet原理及与DenseNet对比
9.BatchNormalization思想及作用
10.卷积层和池化层有什么区别?
11.为什么使用小卷积核而不是大卷积核?
12.Faster-RCNN跟RCNN有什么区别?
13.GRU、LSTM对比
14.梯度消失、梯度爆炸原因及解决方案
15.Seq2Seq模型理解
16.怎么提升网络的泛化能力
17.attention机制原理
18.GAN网络的思想
19.word2vec训练过程
20.布隆过滤器原理及场景
1.反向传播主要思想及推导
反向传播算法(Backpropagation)是目前用来训练人工神经网络(Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:
-
将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
-
由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
-
在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
具体推导公式可参考链接:
https://blog.csdn.net/u014313009/article/details/51039334
2.简要概述HMM、CRF、EM、GMM
-
HMM:隐含马尔科夫模型(hidden Markov model, HMM), 可以用于标注问题的统计学习模型,由隐藏的马尔科夫链,随机生成观测序列的过程,属于生成模型。HMM的三个基本问题为概率计算问题、学习问题、预测问题。
-
CRF:条件随机场(Conditional Random Field, CRF),仅讨论在标注问题中的应用,这里主要是线性链(linear chain)条件随机场。CRF模型实际上是定义在时序数据上的对数线性模型。学习方法包括极大似然估计、正则化的极大似然估计。优化方法有:改进的迭代尺度法、梯度下降法、拟牛顿法。
-
EM:最大期望算法(Expectation-Maximizationalgorithm, EM)是用于含有隐变量(hidden variable)的概率模型参数的极大似然估计、或极大后验概率估计。EM 是一种迭代算法 每次迭代分两步:E步,求期望;M步, 求极大值。概率模型, 有时含有 观测变量(observablevariable), 也可能含有隐变量(hidden variable), 或者潜在变量(latent variable)。都是观测变量的话,给定数据,可以直接用极大似然估计法,或贝叶斯估计法估计模型参数,含有隐变量的话,就要用EM.
-
GMM:高斯混合模型(Gaussian Mixed Model, GMM),指的是多个高斯分布函数的线性组合,理论上GMM可以拟合任意类型的分布。通常用于解决,同一集合下的数据包含多个不同分布的情况(或同一分布,但参数不一样,或不同类型分布)给定一组输入随机变量条件下,另一组输出随机变量条件下,的条件概率模型。假设输出随机变量构成马尔可夫随机场。
参考链接:
https://blog.csdn.net/mrwilliamvs/article/details/89338231
3.衡量分类器好坏指标
首先通过下图(混淆矩阵图)了解TP、TN、FP、FN概念:

-
准确率(Accuracy)。顾名思义,就是所有的预测正确(正类负类)的占总的比重。
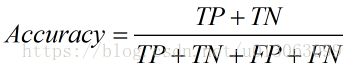
-
精确率(Precision),查准率。即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例。
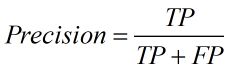
-
召回率(Recall),查全率。即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例。
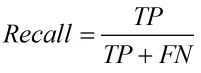
-
F1值(H-mean值)。F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。
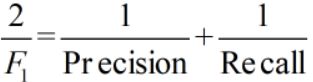
公式转化之后为:
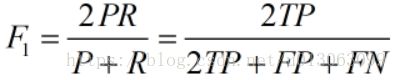
-
ROC曲线。接收者操作特征曲线(receiver operatingcharacteristic curve),是反映敏感性和特异性连续变量的综合指标,ROC曲线上每个点反映着对同一信号刺激的感受性。真正的理想情况,TPR应接近1,FPR接近0,即图中的(0,1)点。ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。

-
AUC值。AUC (Area Under Curve) 被定义为ROC曲线下的面积,AUC = 1,是完美分类器,绝大多数预测的场合,不存在完美分类器。0.5 < AUC < 1,优于随机猜测。AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。总的来说,AUC值越大的分类器,正确率越高。
参考链接:
https://blog.csdn.net/u013063099/article/details/80964865
4.正负样本不平衡的解决办法
-
采样:采样方法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集,在大部分情况下会对最终的结果带来提升。采样分为上采样(Oversampling)和下采样(Undersampling),上采样是把小众类复制多份,下采样是从大众类中剔除一些样本,或者说只从大众类中选取部分样本。
-
数据合成:数据合成方法是利用已有样本生成更多样本(无中生有),这类方法在小数据场景下有很多成功案例,比如医学图像分析等。SMOTE算法为每个小众样本合成相同数量的新样本,这带来一些潜在的问题:一方面是增加了类之间重叠的可能性,另一方面是生成一些没有提供有益信息的样本。为了解决这个问题,出现两种方法:Borderline-SMOTE与ADASYN。
-
加权:基于加权矩阵,横向是真实分类情况,纵向是预测分类情况,C(i,j)是把真实类别为j的样本预测为i时的损失,我们需要根据实际情况来设定它的值。这种方法的难点在于设置合理的权重,实际应用中一般让各个分类间的加权损失值近似相等。当然这并不是通用法则,还是需要具体问题具体分析。
-
一分类:对于正负样本极不平衡的场景,我们可以换一个完全不同的角度来看待问题:把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括One-class SVM等。
参考链接:
https://blog.csdn.net/fantacy10000/article/details/90552584
5.常用激活函数
-
Sigmoid:可解释,比如将0-1之间的取值解释成一个神经元的激活率(firing rate),缺陷是有饱和区域,是软饱和,在大的正数和负数作为输入的时候,梯度就会变成零,使得神经元基本不能更新。只有正数输出(不是zero-centered)。激活函数公式及图象如下:

-
tanh:tanh和sigmoid函数是具有一定的关系的,可以从公式中看出,它们的形状是一样的,只是尺度和范围不同。tanh是zero-centered,但是还是会饱和.激活函数公式及图象如下:

-
ReLU:CNN中常用。对正数原样输出,负数直接置零。在正数不饱和,在负数硬饱和。relu计算上比sigmoid或者tanh更省计算量,因为不用exp,因而收敛较快。但是还是非zero-centered。relu在负数区域被kill的现象叫做dead relu,这样的情况下,有人通过初始化的时候用一个稍微大于零的数比如0.01来初始化神经元,从而使得relu更偏向于激活而不是死掉,但是这个方法是否有效有争议。激活函数公式及图象如下:
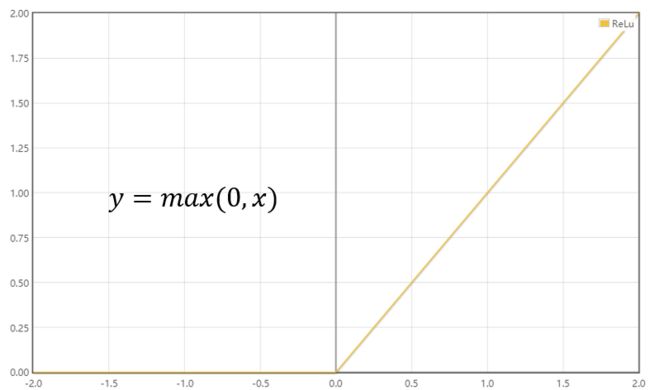
-
LeakyReLU:为了解决上述的dead ReLU现象。这里选择一个数,让负数区域不在饱和死掉。这里的斜率都是确定的。激活函数公式及图象如下:
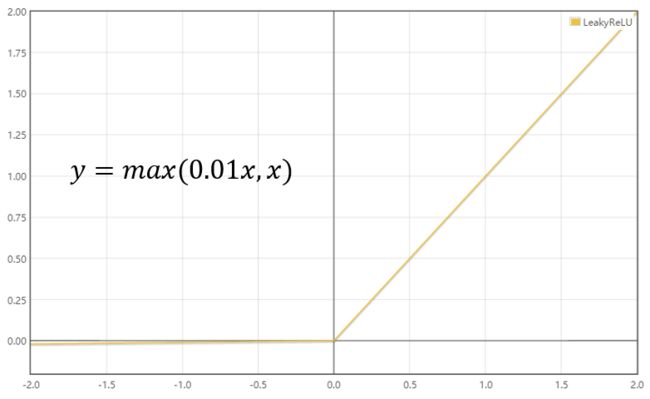
-
ELU:具有relu的优势,且输出均值接近零,实际上prelu和LeakyReLU都有这一优点。有负数饱和区域,从而对噪声有一些鲁棒性。可以看做是介于relu和LeakyReLU之间的一个东西。当然,这个函数也需要计算exp,从而计算量上更大一些。激活函数公式及图象如下:

-
maxout:maxout是通过分段线性函数来拟合所有可能的凸函数来作为激活函数的,但是由于线性函数是可学习,所以实际上是可以学出来的激活函数。具体操作是对所有线性取最大,也就是把若干直线的交点作为分段的界,然后每一段取最大。maxout可以看成是relu家族的一个推广。缺点在于增加了参数量。
参考链接:
https://blog.csdn.net/edogawachia/article/details/80043673
6.Tensorflow的工作原理
-
TensorFlow计算模型一一计算图:TensorFlow 的名字中己经说明了它最重要的两个概念一一Tensor和Flow。Tensor就是张量,张量可以被简单地理解为多维数组。Flow则体现了它的计算模型。Flow翻译成中文就是“流”,它直观地表达了张量之间通过计算相互转化的过程。TensorFlow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。TensorFlow 程序一般可以分为两个阶段。在第一个阶段需要定义计算图中所有的计算;第二个阶段为执行计算。
-
TensorFlow数据模型——张量:在 TensorFlow程序中,所有的数据都通过张量的形式来表示,从功能的角度上看,张量可以被简单理解为多维数组。张量中并没有存储真正的数字,而是存储张量的结构。一个张量中主要保存了三个属性 : 名字( name )、维度( shape )和类型( type )。
-
TensorFlow运行模型——会话:TensorFlow中的会话(session)来执行定义好的运算。会话拥有并管理 TensorFlow 程序运行时的所有资源。所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄漏的问题。
参考链接:
https://blog.csdn.net/Sophia_11/article/details/85244352
7.深度学习框架对比
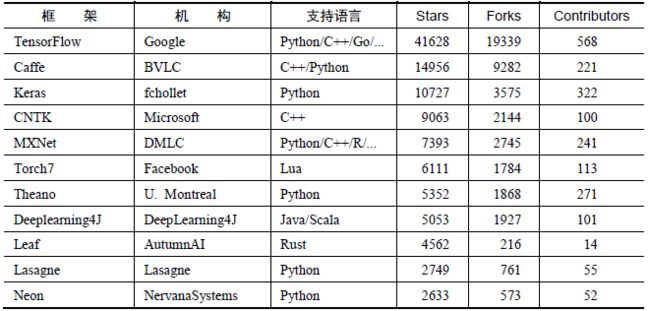
参考链接:
https://blog.csdn.net/lynchyueliu/article/details/104370067
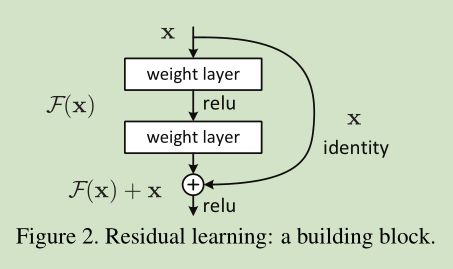
8.ResNet原理及与DenseNet对比
ResNet是何凯明大神在2015年提出的一种网络结构,ResNet又名残差神经网络,指的是在传统卷积神经网络中加入残差学习(residual learning)的思想,解决了深层网络中梯度弥散和精度下降(训练集)的问题,使网络能够越来越深,既保证了精度,又控制了速度。出发点在于随着网络的加深,梯度弥散问题会越来越严重,导致网络很难收敛甚至无法收敛。ResNet中则设计了一种skip connection结构,使得网络具有更强的identity mapping的能力,从而拓展了网络的深度,同时也提升了网络的性能。
Dense Block,它包括输入层在内共有5层,H是BN+ReLU+3x3Conv的操作,并不改变feature map的大小。对于每一层来说,前面所有层的feature map都被直接拿来作为这一层的输入。growth rate就是除了输入层之外,每一层feature map的个数。它的目的是,使得block中的任意两层都能够直接”沟通“。

该架构与ResNet相比,在将特性传递到层之前,没有通过求和来组合特性,而是通过连接它们的方式来组合特性。因此第x层(输入层不算在内)将有x个输入,这些输入是之前所有层提取出的特征信息。因为它的密集连接特性,研究人员将其称为Dense Convolutional Network (DenseNet)
参考链接:
https://zhuanlan.zhihu.com/p/66093272
9.BatchNormalization思想及作用
思想:Batch Normalization通过一定的规范化手段,把每层神经网络输入值的分布强行拉回到均值为0方差为1的标准正态分布。(纠偏回正过程)使得分布回到非线性函数对输入比较敏感的区域,使得损失函数能发生较大的变化(梯度变大),避免梯度消失问题。同时梯度变大能加快模型收敛速度,提高训练速度。
作用:在深度神经网络训练过程,使得每一层神经网络的输入保持相同分布。神经网络随着深度加深,训练变得困难。relu激活函数, 残差网络都是解决梯度消失等由于深度带来的问题。BN同样也是为了解决深度带来的问题。
参考链接:
https://blog.csdn.net/liuxiangxxl/article/details/85248470
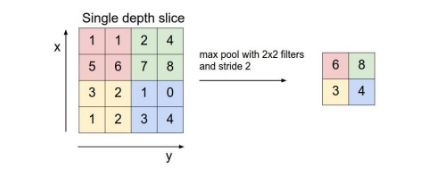
10.卷积层和池化层有什么区别?
CNN网络一共有5个层级结构:输入层、卷积层、激活层、池化层、全连接FC层。
-
卷积层用于局部感知:人的大脑识别图片的过程中,并不是一下子整张图同时识别,而是对于图片中的每一个特征首先局部感知,然后更高层次对局部进行综合操作,从而得到全局信息。

-
池化(Pooling)也称为欠采样或下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。主要有最大池化和平均池化。
参考链接:
https://blog.csdn.net/fu6543210/article/details/82817916
11.为什么使用小卷积核而不是大卷积核?
-
首先,使用几个较小的核而不是几个较大的核来获得相同的感受野并捕获更多的空间上下文,但是使用较小的内核时,使用的参数和计算量较少。
-
其次,因为使用更小的核,您将使用更多的滤波器,您将能够使用更多的激活函数,从而使您的CNN学习到更具区分性的映射函数。
参考链接:
https://www.jianshu.com/p/c8f896dc3fe5
12.Faster-RCNN跟RCNN有什么区别?
和在大量区域上工作不同,RCNN算法提出在图像中创建多个边界框,检查这些边框中是否含有目标物体。RCNN使用选择性搜索来从一张图片中提取这些边框。
首先,让我们明确什么是选择性搜索,以及它是如何辨别不同区域的。组成目标物体通常有四个要素:变化尺度、颜色、结构(材质)、所占面积。选择性搜索会确定物体在图片中的这些特征,然后基于这些特征突出不同区域。
现在,我们了解了RCNN能如何帮助进行目标检测,但是这一技术有自己的局限性。训练一个RCNN模型非常昂贵,并且步骤较多。
RCNN的作者Ross Girshick提出了一种想法,在每张照片上只运行一次CNN,然后找到一种方法在2000个区域中进行计算。在Fast RCNN中,我们将图片输入到CNN中,会相应地生成传统特征映射。利用这些映射,就能提取出感兴趣区域。之后,我们使用一个Rol池化层将所有提出的区域重新修正到合适的尺寸,以输入到完全连接的网络中。所以,和RCNN所需要的三个模型不同,Fast RCNN只用了一个模型就同时实现了区域的特征提取、分类、边界框生成。
参考链接:
https://my.oschina.net/u/3994209/blog/3002187
13.GRU、LSTM对比
LSTM是一种特殊的RNN类型,如图所示,标准LSTM模型是一种特殊的RNN类型,在每一个重复的模块中有四个特殊的结构,以一种特殊的方式进行交互。在图中,每一条黑线传输着一整个向量,粉色的圈代表一种pointwise 操作(将定义域上的每一点的函数值分别进行运算),诸如向量的和,而黄色的矩阵就是学习到的神经网络层。
LSTM模型的核心思想是“细胞状态”。“细胞状态”类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。

概括的来说,LSTM和GRU都能通过各种Gate将重要特征保留,保证其在long-term 传播的时候也不会被丢失。
可以看出,标准LSTM和GRU的差别并不大,但是都比tanh要明显好很多,所以在选择标准LSTM或者GRU的时候还要看具体的任务是什么。
使用LSTM的原因之一是解决RNN Deep Network的Gradient错误累积太多,以至于Gradient归零或者成为无穷大,所以无法继续进行优化的问题。GRU的构造更简单:比LSTM少一个gate,这样就少几个矩阵乘法。在训练数据很大的情况下GRU能节省很多时间。
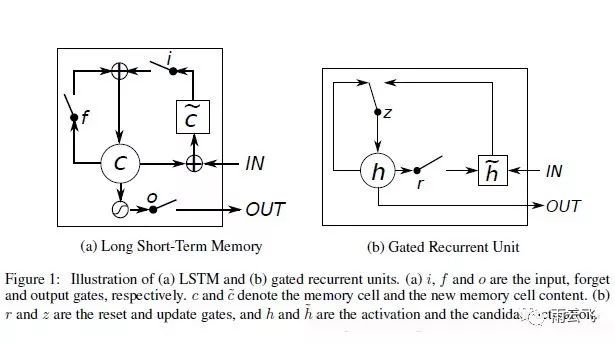
参考链接:
https://blog.csdn.net/lreaderl/article/details/78022724
14.梯度消失、梯度爆炸原因及解决方案
生物神经元似乎是用 Sigmoid(S 型)激活函数活动的,因此研究人员在很长一段时间内坚持 Sigmoid 函数。如果网络非常深,就可能会使得前几层网络参数的梯度接近于0,也就发生了梯度消失现象。
如果网络非常深,就可能会使得前几层网络参数的梯度非常大,也就发生了梯度爆炸现象。
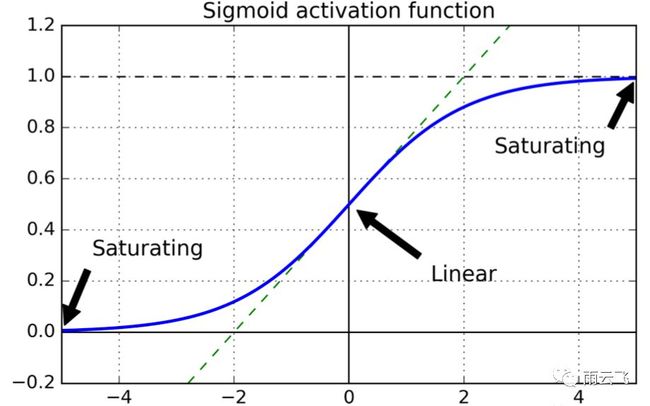
解决方案:
-
好的参数初始化方式,如He初始化
-
非饱和的激活函数(如 ReLU)
-
批量规范化(Batch Normalization)
-
梯度截断(Gradient Clipping)
-
更快的优化器
-
LSTM
参考链接:
https://blog.csdn.net/junjun150013652/article/details/81274958
15.Seq2Seq模型理解
Seq2Seq是一个Encoder-Deocder结构的模型,输入是一个序列,输出也是一个序列。Encoder将一个可变长度的输入序列变为固定长度的向量,Decoder将这个固定长度的向量解码成可变长度的输出序列。
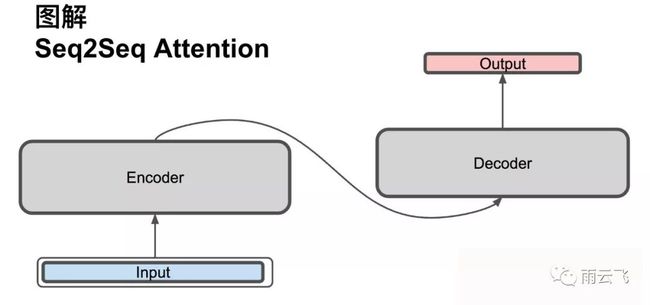
Seq2Seq的核心部分是其解码部分,大部分改进基于此:
-
greedy search:基础解码方法
-
beam search:对greedy search的改进
-
attention:它的引入使得解码时,每一步可以有针对地关注与当前有关的编码结果,从而减小了编码器输出表示的学习难度,也更容易学到长期的依赖关系。
-
memory network:从外部获取知识。
其他方法:
-
堆叠多层RNN的Decoder
-
增加dropout机制
-
与Encoder建立残差连接
参考链接:
https://blog.csdn.net/tiweeny/article/details/81512417
16.怎么提升网络的泛化能力
-
使用更多数据
-
使用更大批次
-
调整数据分布
-
调整目标函数
-
调整网络结构
-
数据增强
-
权值正则化
-
屏蔽网络节点
参考链接:
https://blog.csdn.net/qq_35290785/article/details/90107575
17.attention机制原理
attention模型用于解码过程中,它改变了传统decoder对每一个输入都赋予相同向量的缺点,而是根据单词的不同赋予不同的权重。在encoder过程中,输出不再是一个固定长度的中间语义,而是一个由不同长度向量构成的序列,decoder过程根据这个序列子集进行进一步处理。

参考链接:
https://www.jianshu.com/p/1d67638139da
18.GAN网络的思想
GAN的主要灵感来源于博弈论中零和博弈的思想,应用到深度学习神经网络上来说,就是通过生成网络G(Generator)和判别网络D(Discriminator)不断博弈,进而使G学习到数据的分布,如果用到图片生成上,则训练完成后,G可以从一段随机数中生成逼真的图像。G, D的主要功能是:
-
G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像
-
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片
训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假图像和真实的图像。这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点.
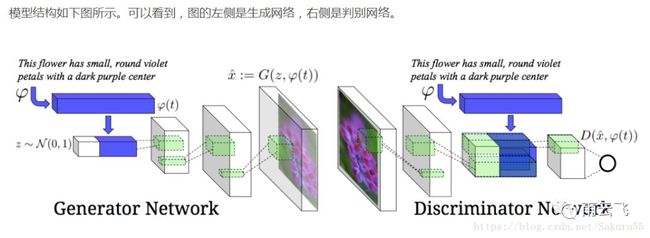
参考链接:
https://blog.csdn.net/Sakura55/article/details/81512600
19.word2vec训练过程
词向量训练的预处理步骤:
-
(1)对输入的文本生成一个词汇表,每个词统计词频,按照词频从高到低排序,取最频繁的V个词,构成一个词汇表。每个词存在一个one-hot向量,向量的维度是V,如果该词在词汇表中出现过,则向量中词汇表中对应的位置为1,其他位置全为0。如果词汇表中不出现,则向量为全0
-
(2)将输入文本的每个词都生成一个one-hot向量,此处注意保留每个词的原始位置,因为是上下文相关的
-
(3) 确定词向量的维数N
Skip-gram处理步骤:
-
(1)确定窗口大小window,对每个词生成2*window个训练样本,(i, i-window),(i, i-window+1),...,(i, i+window-1),(i, i+window)
-
(2)确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本
-
(3)训练算法有两种:层次 Softmax 和 Negative Sampling
-
(4)神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量
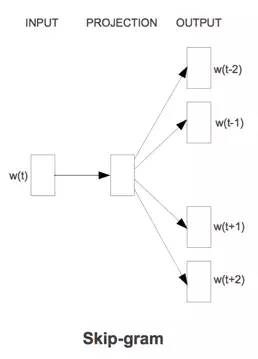
CBOW的处理步骤:
-
(1)确定窗口大小window,对每个词生成2*window个训练样本,(i-window, i),(i-window+1, i),...,(i+window-1, i),(i+window, i)
-
(2)确定batch_size,注意batch_size的大小必须是2*window的整数倍,这确保每个batch包含了一个词汇对应的所有样本
-
(3)训练算法有两种:层次 Softmax 和 Negative Sampling
-
(4)神经网络迭代训练一定次数,得到输入层到隐藏层的参数矩阵,矩阵中每一行的转置即是对应词的词向量
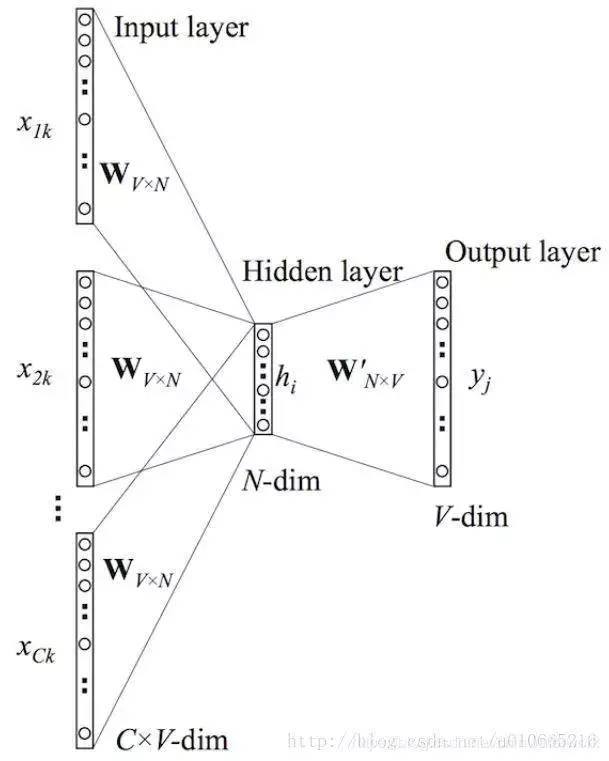
参考链接:
https://www.jianshu.com/p/d8bfaae28fa9
20.布隆过滤器原理及场景
布隆过滤器原理:当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就知道集合中有没有它了:如果这些点有任何一个 0,则被检索元素一定不在;如果都是 1,则被检索元素很可能在。
布隆过滤器优点:它的优点是空间效率和查询时间都远远超过一般的算法,布隆过滤器存储空间和插入 / 查询时间都是常数O(k)。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器缺点:但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
使用场景:主要是解决大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等。
参考链接:
https://www.cnblogs.com/wuer888/p/11236164.html
其他相应高频面试题可参考如下内容:
2020 BAT大厂数据分析面试经验:“高频面经”之数据分析篇
2020 BAT大厂数据挖掘面试经验:“高频面经”之数据结构与算法篇
2020 BAT大厂数据开发面试经验:“高频面经”之大数据研发篇
2020 BAT大厂机器学习算法面试经验:“高频面经”之机器学习篇
欢迎关注作者微信公众号:学习号,涉及数据分析与挖掘、数据结构与算法、大数据与机器学习等内容
