Spark MLlib分布式机器学习源码分析:决策树算法
Spark是一个极为优秀的大数据框架,在大数据批处理上基本无人能敌,流处理上也有一席之地,机器学习则是当前正火热AI人工智能的驱动引擎,在大数据场景下如何发挥AI技术成为优秀的大数据挖掘工程师必备技能。本文结合机器学习思想与Spark框架代码结构来实现分布式机器学习过程,希望与大家一起学习进步~
目录
1.决策树理论
2.Spark实例
3.源码分析
本文采用的组件版本为:Ubuntu 19.10、Jdk 1.8.0_241、Scala 2.11.12、Hadoop 3.2.1、Spark 2.4.5,老规矩先开启一系列Hadoop、Spark服务与Spark-shell窗口:

决策树及其集成是用于机器学习任务的分类和回归的流行方法。决策树被广泛使用,因为它们易于解释,处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征交互。决策树分类算法(例如随机森林和boosting)在分类和回归任务中表现最佳。spark.mllib支持使用连续和分类功能进行二进制和多类分类以及用于回归的决策树。该实现按行对数据进行分区,从而可以对数百万个实例进行分布式训练。
1.决策树理论
决策树学习的主要目的是为了产生一棵泛化能力强的决策树。其基本流程遵循简单而直接的“分而治之”的策略。它的流程实现如下所示:
输入:训练集 D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)};
属性集 A={a_1,a_2,...,a_d}
过程:函数GenerateTree(D,A)
1: 生成节点node;
2: if D中样本全属于同一类别C then
3: 将node标记为C类叶节点,并返回
4: end if
5: if A为空 OR D中样本在A上取值相同 then
6: 将node标记为叶节点,其类别标记为D中样本数量最多的类,并返回
7: end if
8: 从A中选择最优划分属性 a*;//每个属性包含若干取值,这里假设有v个取值
9: for a* 的每个值a*_v do
10: 为node生成一个分支,令D_v表示D中在a*上取值为a*_v的样本子集;
11: if D_v 为空 then
12: 将分支节点标记为叶节点,其类别标记为D中样本最多的类,并返回
13: else
14: 以GenerateTree(D_v,A\{a*})为分支节点
15: end if
16: end for
决策树是一种贪婪算法,它执行特征空间的递归二进制分区。该树为每个最底部(叶子)的分区预测相同的标签。通过从一组可能的分割中选择最佳分割来贪婪地选择每个分区,以使树节点的信息增益最大化。换句话说,从集合argmaxsIG(D,s)中选择在每个树节点选择的拆分,其中IG(D,s)是将拆分s应用于数据集D时的信息增益。
节点杂质是节点上标记均质性的量度。 当前的实现提供了两种用于分类的杂质度量(基尼杂质和熵)和一种用于回归的杂质度量(方差)。

信息增益是父节点杂质与两个子节点杂质的加权和之间的差。假设split s将大小为N的数据集D分为两个大小分别为Nleft和Nright的数据集Dleft和Dright,则信息增益为:
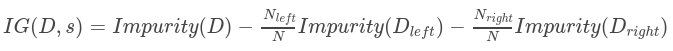
对于单机实施中的小型数据集,每个连续特征的分割候选通常是特征的唯一值。一些实现对特征值进行排序,然后将排序后的唯一值用作拆分候选,以便更快地进行树计算。
对于大型分布式数据集,对特征值进行排序非常昂贵。此实现通过对数据的采样部分执行分位数计算来计算一组近似的拆分候选集。有序拆分将创建“箱”,可以使用maxBins参数指定此类箱的最大数量。
当满足以下条件之一时,递归树构造将在节点处停止:
-
节点深度等于maxDepth训练参数。
-
没有分割候选者会导致信息增益大于minInfoGain。
-
没有拆分的候选对象会生成每个至少具有minInstancesPerNode训练实例的子节点。
2.Spark实例
下面的示例演示了如何加载LIBSVM数据文件,将其解析为LabeledPoint的RDD,然后使用决策树将基尼杂质作为杂质度量并且最大树深度为5进行分类。计算测试误差以测量算法精度。
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.model.DecisionTreeModel
import org.apache.spark.mllib.util.MLUtils
// 加载和解析数据
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// 将数据切分为训练集和测试集
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// 训练一个决策树模型
val numClasses = 2
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "gini"
val maxDepth = 5
val maxBins = 32
val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
impurity, maxDepth, maxBins)
// 在测试集上评估模型计算测试集误差
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testErr = labelAndPreds.filter(r => r._1 != r._2).count().toDouble / testData.count()
println(s"Test Error = $testErr")
println(s"Learned classification tree model:\n ${model.toDebugString}")
// 保存和加载模型
model.save(sc, "target/tmp/myDecisionTreeClassificationModel")
val sameModel = DecisionTreeModel.load(sc, "target/tmp/myDecisionTreeClassificationModel")
下面的示例演示如何加载LIBSVM数据文件,将其解析为LabeledPoint的RDD,然后使用决策树执行回归,并以方差作为杂质度量,最大树深度为5。计算均方误差(MSE) 最后评估适合度。
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.model.DecisionTreeModel
import org.apache.spark.mllib.util.MLUtils
// 加载和解析数据
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// 将数据切分为训练集和测试集
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// 训练一个决策树模型
// 空的categoricalFeaturesInfo表示所有要素都是连续的。
val categoricalFeaturesInfo = Map[Int, Int]()
val impurity = "variance"
val maxDepth = 5
val maxBins = 32
val model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity,
maxDepth, maxBins)
// 在测试集上评估模型计算测试集误差
val labelsAndPredictions = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testMSE = labelsAndPredictions.map{ case (v, p) => math.pow(v - p, 2) }.mean()
println(s"Test Mean Squared Error = $testMSE")
println(s"Learned regression tree model:\n ${model.toDebugString}")
// 保存和加载模型
model.save(sc, "target/tmp/myDecisionTreeRegressionModel")
val sameModel = DecisionTreeModel.load(sc, "target/tmp/myDecisionTreeRegressionModel")
3.源码分析
在MLlib中,决策树的实现和随机森林的实现是在一起的。随机森林实现中,当树的个数为1时,它的实现即为决策树的实现。train源码如下:
* @param input Training dataset: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]].
* For classification, 标签应采用值{0,1,...,numClasses-1}
* For regression, 标签是实数。
* @param algo 决策树的类型,分类或回归。
* @param impurity 用于信息增益计算的标准。
* @param maxDepth 树的最大深度(例如,深度0表示1个叶节点,深度1表示1个内部节点+ 2个叶节点)。
* @param numClasses用于分类的类数。 预设值为2。
* @param maxBins用于拆分要素的最大垃圾箱数。
* @paramQuantileCalculationStrategy用于计算分位数的算法。
* @param categoricalFeaturesInfo映射,用于存储分类特征的集合。 项(从n到k)表示特征n是k个类别的分。从0开始索引:{0,1,...,k-1}。
* @return DecisionTreeModel可用于预测。
@Since("1.0.0")
def train(
input: RDD[LabeledPoint],
algo: Algo,
impurity: Impurity,
maxDepth: Int,
numClasses: Int,
maxBins: Int,
quantileCalculationStrategy: QuantileStrategy,
categoricalFeaturesInfo: Map[Int, Int]): DecisionTreeModel = {
val strategy = new Strategy(algo, impurity, maxDepth, numClasses, maxBins,
quantileCalculationStrategy, categoricalFeaturesInfo)
new DecisionTree(strategy).run(input)
}
这里我们需要知道,当随机森林的树个数为1时,它即为决策树, 并且此时,树的训练所用的特征是全部特征,而不是随机选择的部分特征。即featureSubsetStrategy = "all"。
Spark决策树模型的内容至此结束,有关Spark的基础文章可参考前文:
Spark MLlib分布式机器学习源码分析:矩阵向量
Spark MLlib分布式机器学习源码分析:基本统计
Spark MLlib分布式机器学习源码分析:线性模型
Spark MLlib分布式机器学习源码分析:朴素贝叶斯
参考链接:
https://github.com/endymecy/spark-ml-source-analysis
https://blog.csdn.net/akirameiao/article/details/79953980
http://spark.apache.org/docs/latest/mllib-decision-tree.html

历史推荐
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇
爬虫实战:Selenium爬取京东商品
爬虫实战:豆瓣电影top250爬取
爬虫实战:Scrapy框架爬取QQ音乐

数据分析与挖掘
数据结构与算法
机器学习与大数据组件
欢迎关注,感谢“在看”,随缘稀罕~


一个赞,晚餐加鸡腿