基于opencv的物体识别
1.级联分类器
到底什么是级联分类器,其实就是把分类器按照一定的顺序联合到一起。一个分类器也许不好用,没关系,我给你多加几个。
具体来说,OpenCV实现的Cascade(级联)分类器就是基于多个弱分类器对不同的特征进行依次处理(分类)来完成对目标的检测,每一级都比前一级复杂,简单的说有多个弱分类器串起来,然后提取每个平滑窗上的不同特征,把这些特征依次放进不同的弱分类器里判断,如果所有的弱分类器都判断正标签,则表示该平滑窗内检测到目标。这样做的好处是不但通过多个弱分类器来形成一个强的级联分类器,而且可以减少运算量,比如当一个平滑窗第一个特征没有通过第一个分类器,那么就没有必要继续运算下去,直接拒绝掉当前平滑窗,转而处理下一个平滑窗,事实上作者的目的就是为了快速抛弃没有目标的平滑窗,从而达到快速检测目标。
每一个强分类器对负样本的判别准确度非常高,所以一旦发现检测到的目标位负样本,就不在继续调用下面的强分类器,减少了很多的检测时间。因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分娄器的速度是非常快的;只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正(falsepositive)的可能性非常低。
2.矩阵特征
Haar算法实际上是运用了boosting算法中的Adaboost算法。Haar分类器利用Adaboost算法构建一个强分类器进行级联,而在底层特征抽取上采用的是高校的矩形特征以及积分图方法。
Haar分类器=类Haar特征+积分图法+Adaboost算法+级联。
Haar分类器主要步骤如下:
1.提取类Haar特征。
2. 利用积分图法对类Haar特征提取进行加速。
3. 使用Adaboost算法训练强分类器,区分出人脸和非人脸。
4. 使用筛选式级联把强的分类器级联在一起,从而提高检测准确度。
人脸检测的大概流程:
我们用一个小的窗口在一幅图片中不断的滑动,每滑动到一个位置,就对该小窗口内的图像进行特征提取,若提取到的特征通过了所有训练好的强分类器的判定,则我们判定该小窗口的图片内含有人脸。

上图中两个矩形特征,表示出人脸的荒些特征.比如中间一幅表示眼晴区域的颜色比脸粟区域的颜色深,右边一幅表示鼻梁两侧比鼾梁的颜色要深。同样,其他目标,如眼晰等,也可以用一些矩形特征来表示。使用特征比单纯地仰用像素点,其有很大的优越性,并且速度更快。在给定有限的数据情况下,基于特征的检测能够编码特定区域的状态,而且基于特征的系统比基于象素的系统要快得多。
矩形特征对一些简单的图形结构,比如边缘、线段,比较敏感,但是其只能描述特定走向(水平、垂直、对角)的结构,因此比较粗略。如上图,脸部一些特征能够由矩形特征简单地描绘,例如,通常,眼晴要比脸颊颜色更深;鼻梁两例要比鼾梁颜色要深;嘴巴要比周围颜色更深。
对于一个24x24检测器,其内的符形特征数量超过160000个,必须通过特定算法甄选合适的矩形特征,并将其组合成强分类器才能检测人脸:
常用的矩形特征有三种:两矩形特征、三矩形特征、四矩形特征,如图:
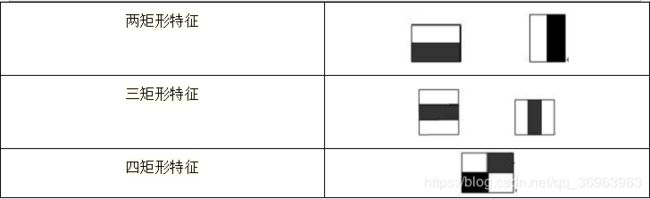
由表可以看出,两矩形特征反应的是边缘特征,三矩形特征反应的是线性特征,四矩形特征反应的是特定方向特征。
特征模板的特征值定义为:白色矩形像素和减去黑色矩形像素和。接下来,要解设两个问题:
1:求出每个待检测子窗口中的特征个数。
2:求出每个特征的特征值:
子窗口中的特征个数即为特征矩形的个数。训练时。将每一个特征在训练图像子窗口中进行滑动计算,获取各个位置的各类矩形特征。在子窗口中位于不同位置的同一类型矩形特征,属于不同的特征。可以证明,在确定了特征的形式之后,矩形特征的数量只与子窗口的大小有关。在24x24的检测窗口中,矩形特征的数量约为160000个。
特征模板可以在子窗口内以“任意“尺寸“任意“放置,每一种形态称为一个特征
找出子窗口所有特征,是进行弱分类训练的基础
3.子窗口内的条件矩形,矩形特征个数的计算
入下图所示的一个m*m大小的子窗口,可以计算在这么大的子窗口内存在多少个矩形特征。
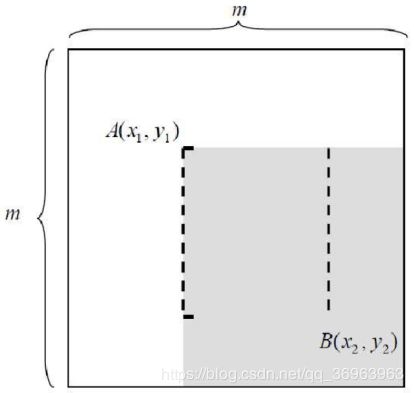
以mm像素分辨率的检测器为例,其内部存在的满足特定条件的所有矩形的总数可以这样计算:
对于mxm子窗口,我们只需要确定了矩形左上顶点A(xl,y1)和右下顶点B(x2,63),即可以确定一个矩形;如果这个矩形还必须满足下面两个条件(称为(s,t)条件,满足(s,t)条件的矩形称为条件矩形)::
1.x方向边长必须能被自然数s整除(能均等分成s段)
2.Y方向边长必须能被自然数t整除(能均等分成t段)
则这个矩形的最小尺寸为st,最大尺寸为[m/s]s[m/t]*t,其中[]为取整运算符。
4.积分图
概念:
在获取了矩形特征后,要计算矩形特征的值。Viola等人提出了利用祝分图求特征值的方法。积分图的概念可用下图表示:
坐标A(x,y)的积分图是其左上角的所有像素之和(图中的阴影部分)。定义为:
其中ii(x,y)表示积分图,i(x,y)表示原始图像,对于彩色图像,是此点的颜色值;对于灰度图像,是其灰度值,范围为0~255。
在上图中,A(x,y)表示点(x,y)的积分图;s(x,y)表示点(x,y)的y方向的所有原始图像之和。积分图也可以得出:
利用积分图计算特征值
一个区域的像素值,可以利用该区域的端点的积分图来计算,如下图所示
在上图中,ii(l)表示区域A的像素值,ii(2)表示区域A+B的像素值,ii(3)表示区域A+C的像素值,ii(4)表示区域A+B+C+D的像素值。而区域D的像素值=区域A+B+C+D的像素值+区域A的像素值-区域A+B的像素值-区域A+C的像素值,即:区域D的像素值=ii(4)+ii(l)-ii(2)-ii(3)
4.计算特征值
由上面已经知道,一个区域的像素值,可以由该区域的端点的积分图来计算由前面特征模板的特征值的定义可以推出,矩形特征的特征值可以由特征端点的积分图计算出来。以“两矩形特征“中的第二个特征为例,如下图,使用祝分图计算其特征值:
该矩形特征的特征值,由定义,为区域A的像素值减去区域B的像素值。由上节可知:
区域A的像素值=ii(5)+ii(l)-ii(2)-ii(4)
区域B的像素值=ii(6)+ii(2)-ii(5)-ii(3)
所有,该矩形特征的特征值=ii(5)+ii(l)-ii(2)-[ii(6)+ii(2)-ii(5)-ii(3)]
=[ii(5)-ii(4)]+[ii(3)-ii(2)]-[ii(2)-ii(1)]-[ii(6)-ii(5)]
所以,矩形特征的特征值,只与特征矩形的端点的积分图有关,而与图像的坐标无关。通过计算特征矩形的端点的积分图,再进行简单的加减运算,就可以得到特征值。正因为如此,特征的计算速度大大提高,也提高了目标的检测速度。
5.弱分类器的构建
我们可以用决策树来构建一个简单的弱分类器, 将提取到的特征与分类器的特征进行逐个比较,从而判断该特征是否属于人脸,如下图所示:

分类器: 判别某个事物是否属于某种分类的器件,两种结果:是、否
训练属于自己的xml文件,需以下几个步骤:
准备数据集,分为正样本集pos和负样本集neg,负样本一般是正样本的3~5倍;
正样本就是我们的分类目标,负样本不能有和包含一丁点正样本(随便其他图像)
1、训练分类器
需要两个工具,下载opencv_createsamples.exe和opencv_haartraining.exe,这两个已经放在工程目录下了;
正样本由opencv_createsamples.exe生成。正样本可以由包含待检测物体的一张图片生成,也可由一系列标记好的图像生成。
6.生成描述文件

我们这里是训练狗的分类器,一共一百张狗的照片,我们写一个脚本(脚本.py)把正样本生成描述文件(pos.txt文本文件),这是在生成向量化数据时所需要的,只需要运行这个脚本就可以了。
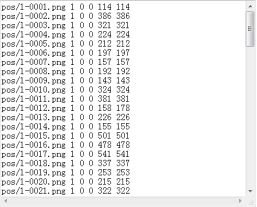
准备正样本vec文件所需的info文件(pos.txt),格式如下所示:
pos/1-0001.png 1 0 0 114 114
pos/1-0002.png 1 0 0 386 386
pos/1-0003.png 1 0 0 321 321
负样本只需要图片的路径即可,格式如下所示。同样是运行这个脚本,只需要把正样本的相关代码注释掉,运行负样本的代码。
neg/1-f001.png
neg/1-f002.png
neg/1-f003.png
所有的正样本都是放在pos放在一个文件夹,所有的负样本都放在neg文件夹。其中,pos.txt文件为所有正样本图像的列表文件,格式如上面所示:
第一列为图片路径名,
第二列是图片中能检测出的样本表数量,由于训练的目标是小狗,所以图片中只有一只狗。当然如果有两只就写2;
第三第四列是图像的坐标,(0,0)就行;
第五第六列是图像宽和高,需要注意是一样的,宽高比需要一样的。
如果你们的正样本图片的宽高不一样,可以根据需求修改‘规范正样本大小.py’文件,修改成自己的目录和cv2.resize图片大小。
pos.txt文件的生成方式:我们编写一个脚本(脚本.py),遍历这个pos文件,逐一添加数据,代码如下
import os
import cv2
def convertjpg(jpgfile ):
img = cv2.imread("pos/" +jpgfile, cv2.IMREAD_GRAYSCALE) ##cv2.imread读取图片是为了获取图片的宽高
w,h=img.shape[:2] ##shape获取图片宽高
'''
够造数据格式
pos/'+jpgfile 就是图片路径,列如:pos/1.jpg
' 1 0 0 ' +str(w)+' '+str(h)+ '\n' 1是样本目标数量,一张图片一个目标;
0 0是类似坐标;
str(w)+' '+str(h)是宽高,需要转换为字符串类型;
\n 是换行
'''
line = 'pos/'+jpgfile + ' 1 0 0 ' +str(w)+' '+str(h)+ '\n'
f.write(line) ##写入数据
with open('pos.txt', 'w') as f: ##打开一个pos.txt文本文件
for jpgfile in os.listdir("pos/"): ##遍历pos文件夹下的所有正样本
print(jpgfile)
convertjpg(jpgfile )
运行这个脚本,会生成一个pos.txt文件,内容如下:
以同样的方式生成负样本,负样本neg.txt只需要负样本图片的路径即可
import os
with open('neg.txt', 'w') as f:
for img in os.listdir('neg'):
print(img)
line = 'neg/'+img +'\n'
print(line)
f.write(line)
运行后生成如下文件
7.向量化正样本集(生成.vec文件)
训练时,需要将正样本集的数据要存成 pos.vec格式的数据文件,opencv提供了opencv_createsamples.exe脚本可以生成vec数据文件;负样本集的路径不要求做,只需生成neg.txt就可以;所以我们对正样本数据进行进一步处理生成描述文件
生成样本描述文件,首先在dos中cd进入到当前目录,也就是opencv_createsamples.exe所在的目录下;然后输入:
opencv_createsamples.exe -info pos.txt -vec pos.vec -num 100 -bgcolor 0 -bgthresh 0 -w 20 -h 20
回车之后文件夹下就会出现pos.vec文件。其中pos.txt是我们刚刚生成的文本文件。
或者新建批处理脚本vec.bat,输入: opencv_createsamples.exe -info pos.txt -vec pos.vec -num 100 -bgcolor 0 -bgthresh 0 -w 20 -h 20 ,然后保存点击运行也同样可以

可以看到相关的一些参数:
-info:是生成的pos.txt文本文件 ;
-vec:是.vec文件存放的路径;
-num:指的是正样本数量;
-bgcolor:这是创建样本是样本扭曲函数中用来决定像素是有效还是作为背景过滤的基本值,因为操作的是灰度图,所以这个值0范围是~255。
-bgthresh:决定背景掩码的实际取值范围为bgcolor-bgthresh ——bgcolor-bgthresh
-w和-h:要创建的样本图片的宽度和高度,后面的训练样本步骤要使用和这时一样的值,不然会报错
在这过程中有可能会遇到的问题
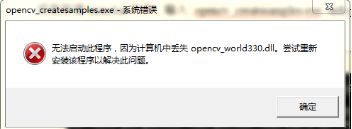
解决办法:
![]()
将bin目录(我的opencv是 C:\Program Files (x86)\Opencv\opencv\build\x64\vc15\bin)中的3个dll文件复制在(C:\Windows\System32)或者(C:\Windows\SysWOW64)中。注意:64位系统用户需要注意,32位的DLL文件放在“C:\Windows\SysWOW64”,64位的DLL文件放在“C:\Windows\System32”
如果在实验过程中遇到““计算机丢失api-ms-win-downlevel-shlwapi-l1-1-0.dll”、“应用程序无法正常启动(0x000007b)” ”,出现如下弹框

到‘工具’文件夹里面将api-ms-win-downlevel-shlwapi-l1-1-0.dll复制到 C:\Windows\SysWOW64路径下;

在同一目录下(C:\Windows\SysWOW64)新建register_my.bat文件,内容如下:(先建文本文档,编辑保存后再改后缀名,不然不能编辑)
@echo 开始注册
copy api-ms-win-downlevel-shlwapi-l1-1-0.dll %windir%\system32\
regsvr32 %windir%\system32\api-ms-win-downlevel-shlwapi-l1-1-0.dll /s
@echo api-ms-win-downlevel-shlwapi-l1-1-0.dll注册成功
@pause
然后双击执行register_my.bat文件运行即可
如果命令栏中出现api-ms-win-downlevel-shlwapi-l1-1-0.dll注册成功信息,即完成。
8.训练分类器
pos.vec文件创建后 ,就可以进行训练分类器了。利用opencv_traincascade.exe工具进行训练 。

在命令行输入:
opencv_traincascade -data xml -vec pos.vec -bg neg.txt -numPos 85 -numNeg 400 -numStages 12 -featureType LBP -w 20 -h 20 -minHitRate 0.996 -maxFalseAlarmRate 0.5 -mode ALL
按回车 ,等待训练
或者创建HARR_train.bat文件同样输入
opencv_traincascade -data xml -vec pos.vec -bg neg.txt -numPos 85 -numNeg 400 -numStages 12 -featureType LBP -w 20 -h 20 -minHitRate 0.996 -maxFalseAlarmRate 0.5 -mode ALL
保存后点击运行。
参数:
-data:目录名,用于存放训练好的分类器。
-vec:正样本文件,由open_createsamples.exe生成,正样本文件后缀名为.vec。
-bg:负样本说明文件,主要包含负样本文件所在的目录及负样本文件名。
-numPos:每级分类器训练时所用的正样本数目,使用正样本的80%-90%即可。
-numNeg:每级分类器训练时所用的负样本数目,可以大于负样本的图片数目。
-numStages:训练分类器的级数,强分类器的个数(训练层数:这个参数不能太大也不能太小,一般10到15)。
-w:训练的正样本的宽度,Haar特征的w和h一般为20,LBP特征的w和h一般为24,HOG特征的w和h一般为64。
-h:训练样本的高(单位为像素),必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致。
-minHitRate:影响每个强分类器阈值,每一级分类器最小命中率,表示每一级强分类器对正样本的的分类准确率(一般取值0.95-0.995)。
-maxFalseAlarmRate:最大虚警率,影响弱分类器的阈值,表示每个弱分类器将负样本误分为正样本的比例,一般默认值为0.5。
-mode all:指定haar特征的种类,all表示使用垂直以及45度旋转特征。
-featureType:训练使用的特征类型,目前支持的特征有Haar,LBP和HOG。
可以用LBP和HAAR两种来训练,但是HAAR训练会久一点,但是精准度好一点;LBP训练的快一点,但是识别度没那么好。我这里使用了HARR训练。
当训练完成后会出现下情况,可以在xml文件夹内找到cascade.xml模型。
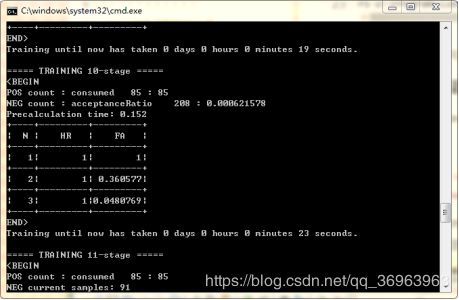
如果卡在POS这里,慢慢等待 ,我是等了十分钟左右才跳出 如果很久都没跳出 -numStages参数说明太大,改小一点即可, 当然如果太小的话, 生成的xml文档分类效果可能就不太好。
当出现如下提示 ,表示训练完毕

然后就可以看到一个xml文档生成
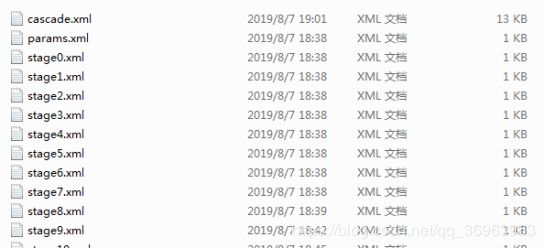
stage0.xml stage1.xml params.xml是每一阶段训练生成的xml,运行完后最终生成cascade.xml ,这个cascade.xml 文件就是最终的模型,要用的时候直接导入使用。
9.利用训练好的分类器进行目标检测
cv2.CascadeClassifier()
函数加载我们的分类器
然后调用detectMultiScale()函数检测,调整函数的参数可以使检测结果更加精确。
detectMultiScale函数原型,该函数用vector保存各个目标的坐标、大小(用矩形表示)
1.image表示的是要检测的输入图像
2.objects表示检测到的人脸目标序列
3.scaleFactor表示每次图像尺寸减小的比例
4. minNeighbors表示每一个目标至少要被检测到3次才算是真的目标(因为周围的像素和不同的窗口大小都可以检测到人脸),
5.6…minSize和maxSize为目标的最小尺寸和最大尺寸
7.flags–flags对于新的分类器没有用(但目前的haar分类器都是旧版的,CV_HAAR_DO_CANNY_PRUNING,这个值告诉分类器跳过平滑(无边缘区域)。利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域;CV_HAAR_SCALE_IMAGE,这个值告诉分类器不要缩放分类器。而是缩放图像(处理好内存和缓存的使用问题,这可以提高性能)就是按比例正常检测;CV_HAAR_FIND_BIGGEST_OBJECTS,告诉分类器只返回最大的目标(这样返回的物体个数只可能是0或1)只检测最大的物,CV_HAAR_DO_ROUGH_SEARCH,他只可与CV_HAAR_FIND_BIGGEST_OBJECTS一起使用,这个标志告诉分类器在任何窗口,只要第一个候选者被发现则结束寻找(当然需要足够的相邻的区域来说明真正找到了),只做初略检测。
检测到目标后就可以用cv2.rectangle函数画出矩形。
训练好之后我们来测试一下
打开pycharm
我们右击相应的文件目录,选择new—>点击Python File,然后输入新建的test.py,点击确定,相应的test.py文件就建好了,可以进行编写代码了
import cv2
cascade_model=cv2.CascadeClassifier('xml/cascade.xml')
img=cv2.imread('test/dog2.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = cascade_model.detectMultiScale(gray, scaleFactor=1.1,
minNeighbors=5,
minSize=(20, 20),
flags=cv2.CASCADE_SCALE_IMAGE)
##如果检测到
if len(faces)>0:
for (x, y, w, h) in faces:
cv2.rectangle(gray, (x, y), (x + w, y + h), [0,255,0], 2)
print('Detected ', len(faces), " 目标")
cv2.imshow('frame', gray)
cv2.waitKey()
效果可能不太好,因为数据集太小的原因,可以增加数据集以达到实用的效果
效果

功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片:
居中的图片: 
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
- Markdown
- Text-to- HTML conversion tool
- Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎