大数据云计算学习路线分析(纯属个人看法和观点)
1.Linux基础和Hadoop分布式架构计算处理模块

学完此阶段可掌握的核心能力:
熟练使用Linux,熟练安装Linux上的软件,了解熟悉负载均衡、高可靠等集群相关概念,搭建互联网高并发、高可靠的服务架构;
学完此阶段可解决的现实问题:
搭建负载均衡、高可靠的服务器集群,可以增大网站的并发访问量,保证服务不间断地对外服务;
学完此阶段可拥有的市场价值:
具备初级程序员必要具备的Linux服务器运维能力。
2.Storm实时计算处理

实时课程分为两个部分:流式计算核心技术和流式计算计算案例实战。
1.流式计算核心技术
流式计算核心技术主要分为两个核心技术点:Storm和Kafka,学完此阶段能够掌握Storm开发及底层原理、Kafka的开发及底层原理、Kafka与Storm集成使用。具备开发基于storm实时计算程序的技术能力。
学完此阶段可掌握的核心能力:
(1)、理解实时计算及应用场景
(2)、掌握Storm程序的开发及底层原理、掌握Kafka消息队列的开发及底层原理
(3)、具备Kafka与Storm集成使用的能力
学完此阶段可解决的现实问题:
具备开发基于storm的实时计算程序的能力
学完此阶段可拥有的市场价值:
具备实时计算开发的技术能力、但理解企业业务的能力不足
1.1、流式计算一般结构
2011年在海量数据处理领域,Hadoop是人们津津乐道的技术,Hadoop不仅可以用来存储海量数据,还以用来计算海量数据。因为其高吞吐、高可靠等特点,很多互联网公司都已经使用Hadoop来构建数据仓库,高频使用并促进了Hadoop生态圈的各项技术的发展。一般来讲,根据业务需求,数据的处理可以分为离线处理和实时处理,在离线处理方面Hadoop提供了很好的解决方案,但是针对海量数据的实时处理却一直没有比较好的解决方案。就在人们翘首以待的时间节点,storm横空出世,与生俱来的分布式、高可靠、高吞吐的特性,横扫市面上的一些流式计算框架,渐渐的成为了流式计算的首选框架。如果庞麦郎在的话,他一定会说,这就是我要的滑板鞋!
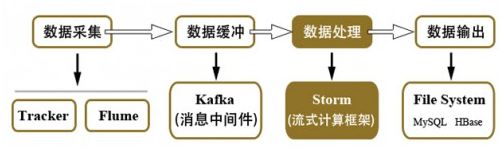
上图是流式分析的一般架构图,抽象出四个步骤就是数据采集、数据缓冲、数据处理、数据输出。一般情况下,我们采用Flume+kafka+Storm+Redis的结构来进行流式数据分析。实时部分的课程主要是针对Kafka、Storm进行学习
1.2、流式计算可以用来干什么
一淘-实时分析系统:实时分析用户的属性,并反馈给搜索引擎。最初,用户属性分析是通过每天在云梯上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
携程-网站性能监控:实时分析系统监控携程网的网站性能。利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
一个游戏新版本上线,有一个实时分析系统,收集游戏中的数据,运营或者开发者可以在上线后几秒钟得到持续不断更新的游戏监控报告和分析结果,然后马上针对游戏的参数和平衡性进行调整。这样就能够大大缩短游戏迭代周期,加强游戏的生命力。
实时计算在腾讯的运用:精准推荐(广点通广告推荐、新闻推荐、视频推荐、游戏道具推荐);实时分析(微信运营数据门户、效果统计、订单画像分析);实时监控(实时监控平台、游戏内接口调用)
为了更加精准投放广告,阿里妈妈后台计算引擎需要维护每个用户的兴趣点(理想状态是,你对什么感兴趣,就向你投放哪类广告)。用户兴趣主要基于用户的历史行为、用户的实时查询、用户的实时点击、用户的地理信息而得,其中实时查询、实时点击等用户行为都是实时数据。考虑到系统的实时性,阿里妈妈使用Storm维护用户兴趣数据,并在此基础上进行受众定向的广告投放。
1.3、Storm核心技术点
基础技术点
linux环境准备、zookeeper集群搭建、Storm集群搭建、Storm配置文件配置项讲解、集群搭建常见问题解决。
Storm练习案例
根据蚂蚁金服提供的最新数据,今年双十一的交易峰值为8.59万笔/秒,是去年3.85万笔/秒的2.23倍。这一数据也超过了6万笔/秒的预估。如何实时的计算订单金额,让公司领导层看到呢?

(图为双十一支付宝成交金额)
Storm基础及原理
Storm常用组件和编程API:Topology、 Spout、Bolt、Storm分组策略(stream groupings)、Storm项目maven环境搭建、使用Strom开发一个WordCount例子、Storm程序本地模式debug、Storm消息可靠性及容错原理、Storm任务提交流程、Strom消息容错机制。
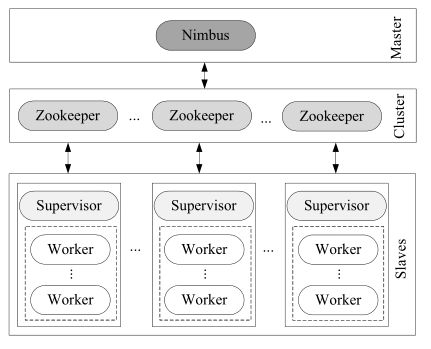
(图为storm组件)
3.Spark内存计算处理

学完此阶段可掌握的核心能力:
1.掌握Scala函数式编程特性,熟练使用Scala开发程序,可以看懂其他用Scala编写源码。
2.搭建Spark集群、使用Scala编写Spark计算程序,熟练掌握Spark原理,可以阅读Spark源码。
3.理解DataFrame和RDD之间的关系,熟练使用DataFrame的API,熟练使用Spark SQL处理结构化数据,通过Spark SQL对接各种数据源,并将处理后结果写回到存储介质中。
4.理解Spark Streaming的核心DStream,掌握DStream的编程API并编写实时计算程序。
学完此阶段可解决的现实问题:
熟练使用Scala快速开发Spark大数据应用,通过计算分析大量数据,挖掘出其中有价值的数据,为企业提供决策依据。
学完此阶段可拥有的市场价值:
学习完spark并掌握其内容,将具备中级大数据工程师能力,薪水可以达到 20K~25K。
1.Scala函数式编程
介绍:Scala是一门集面向对象和函数式编程与一身的编程语言,其强大的表达能力、优雅的API、高效的性能等优点受到越来越多程序员的青睐。Spark底层就是用Scala语言编写,如果想彻底掌握Spark,就必须学好Scala。
案例:Scala编程实战,基于Akka框架,编写一个简单的分布式RPC通信框架
2.使用Spark处理离线数据
介绍:Spark是基于内存计算的大数据并行计算框架,具有高容错性和高可伸缩性,可以在大量廉价硬件之上部署大规模集群,在同等条件下要比Hadoop快10到100倍。
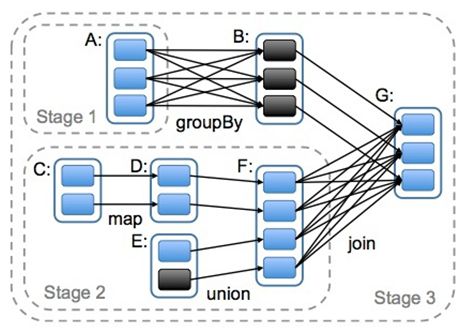
3.使用Spark SQL处理结构化数据
介绍:Spark SQL的前身是Shark,专门用来处理结构化的数据,类似Hive,是将SQL转换成一系列RDD任务提交到Spark集群中运行,由于是在内存中完成计算,要比hive的性能高很多,并且简化了开发Spark程序的难度同时提高了开发效率。

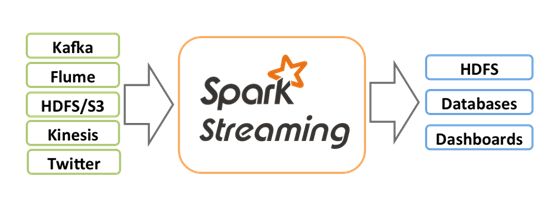
4.使用Spark Streaming完成实时计算
介绍:Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合
5.Spark综合项目:
介绍:该项目使用了Spark SQL和Spark Streaming对游戏整个生命周期产生的数据进行了分析,从玩家第一次登录游戏到每天产生的游戏日志,通过大量的数据来分析该游戏的运营情况和玩家的各种行为:如活跃用户、用户留存、充值比例、游戏收人、外挂分析等。
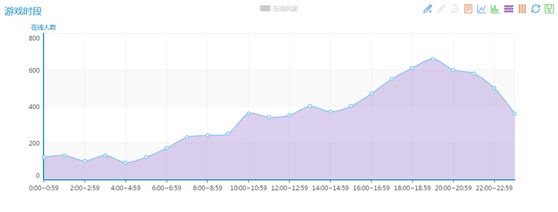
通过玩家登录游戏产生的数据分析一天之内各个时间段进入游戏的情况
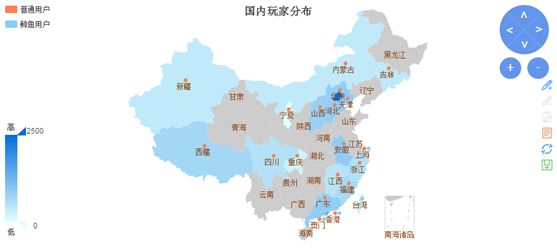
通过玩家登陆游戏产生的数据分析玩家在全国地区的分步情况,调整广告投放策略
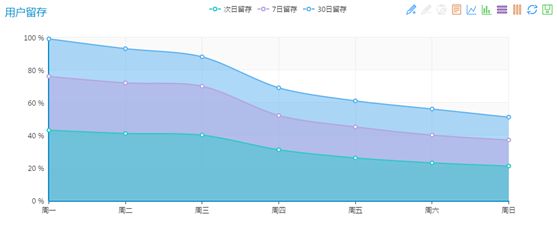
用户留存指标可以分析游戏对玩家的吸引力,分析用户流失原因
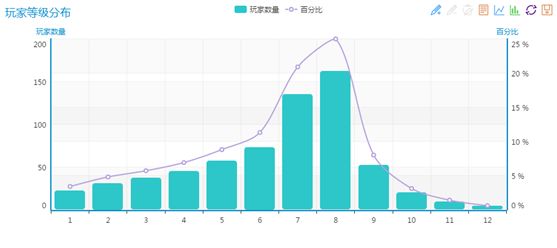
用户等级信息可以分析玩家等等级分布情况、调整装备爆率和游戏难度
通过上面游戏各个数据指标的分析,可以让游戏运维者了解游戏的运维情况,为运维者提供各种个性化的调整策略,从而保证游戏健康、稳定的运营。