至于solr概念等不在赘述,直接进入正题,自己之前研究了一些东西,现在写下来,希望对需要的人有所帮助!有不对的地方请指正!
1.Solr的安装及配置
1.1下载地址:http://lucene.apache.org/
从lucene的官网下载,lucene和solr的版本是同步更新的。我当时下的是4.7.0 ,目前版本7.4.0。
1.2 solr的文件夹结构
1.3 Solr的环境
要求jdk1.7以上。
要求tomcat也是7以上,我们使用的版本是apache-tomcat-8.0.
1.4 Solr集成tomcat
第一步:安装tomcat,如果解压版就直接解压。
第二步:把\solr-4.7.0\dist\solr-4.7.0.war文件复制到to mcat的webapp下。改名为solr.war。改名不是必须的,便于访问。
第三步:解压solr.war,启动tomcat自动解压。
第四步:把\solr-4.7.0\example\lib\ext文件夹下的jar包,日志相关的jar包添加到sorl工程的lib文件夹下。

第五步:创建一个solrhome,solrhome就是solr服务器配置文件存放的目录。\solr-4.7.0\example\solr文件夹就是一个标准的solrhome可以直接使用。

把solr文件夹复制到D:\temp\jee15目录下,然后改名为solrhome。改名不是必须,为了便于理解。
1、在solrhome中有一个collection1文件夹就是一个solrcore。一个solrcore就是一个完整的索引库。
2、在collection1文件夹下有一个conf文件夹,在此文件夹中包含了这个solrcore的所有配置文件。
3、solrconfig.xml和schema.xml两个重要的配置文件。先了解solrconfig.xml:
Lib:配置了索引库的扩展jar包的位置。默认是collection1\lib文件夹,如果没有就创建一个。
dataDir:索引库存放的目录。默认是collection1\data文件夹,如果没有solr启动后会自动创建。
requestHandler:配置了solr对外提供服务的url。
查询索引使用的url:
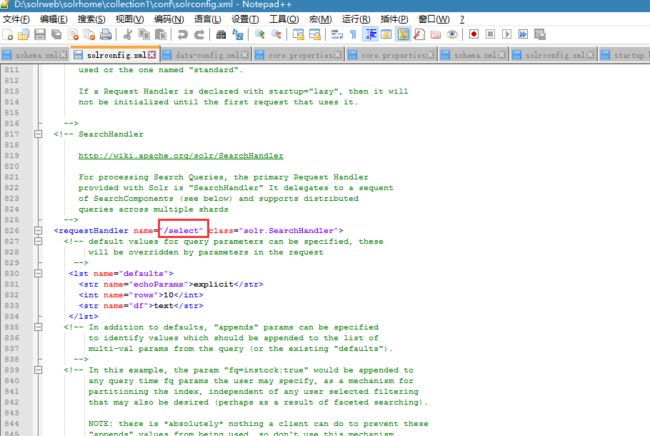
维护索引时使用的url:
defaultQuery:默认的查询语法
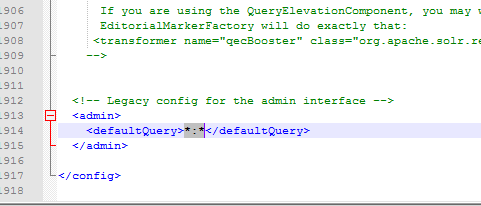
可以根据实际情况对solrconfig.xml进行配置,如果使用默认配置可以不修改此配置文件。
第六步:告诉solr服务器solrhome的位置。使用jndi的方式。修改solr工程的web.xml文件

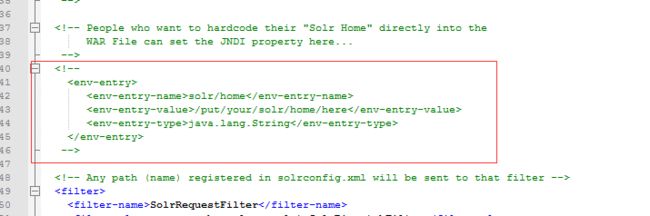

如我的solrhome是在D:\solr\solrhome

第七步:启动tomcat
第八步:访问http://localhost:9999/solr/
2.Solr的功能介绍
2.1 Core Admin配置管理solrcore的功能。每个solr服务可以有多个solrcore每个solrcore是独立的索引库。类似于mysql的数据库。
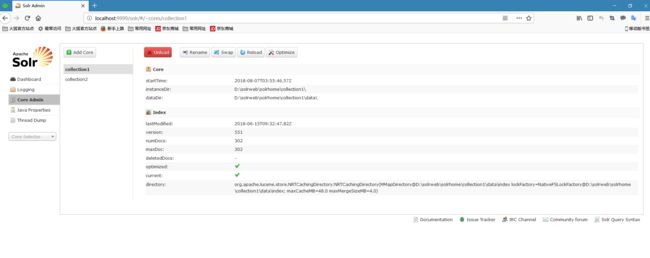
2.2 添加solrcore
步骤:
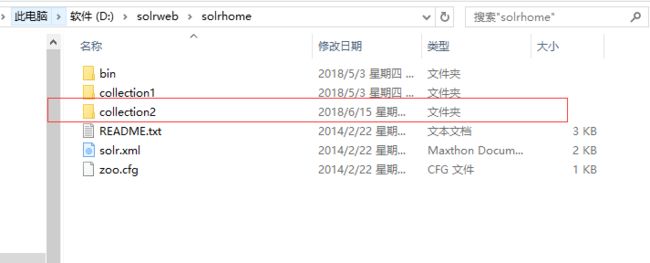
第一步:把collection1复制一份改名为collection2
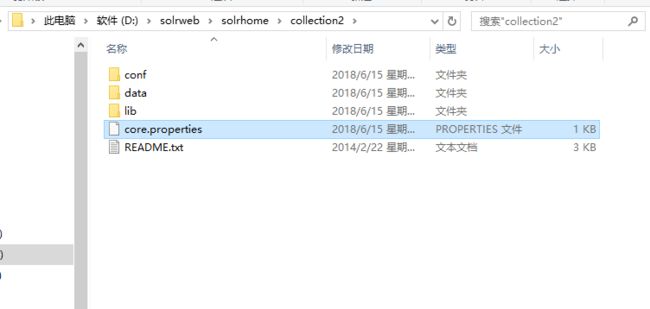
第二步:修改collection2下的core.properties文件,修改name=collection2

第三步:重新启动tomcat

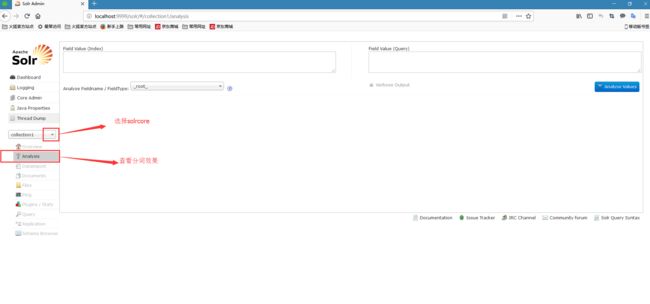
2.3 Analysis
查看某个域的分析效果。
2.4Dataimport
把数据库中的数据批量导入到索引库中使用的功能。需要手工配置。
2.5Documents
实现对索引库的增删改操作

2.6Query
查询索引使用的功能

3 . Schema.xml
在solr中域必须先定义后使用,不能随便起名字。所有的域都是定义在schema.xml中。
3.1Field
域的定义
Name:域的名称
Type:域的类型
Indexed:是否索引
Stored:是否存储
multiValued:是否多值。在一个域下存储多个值。一个域下存储一个数组。

3.2dynamicField
动态域。
Name:动态域的名称的表达式,域的名称只需要和表达式向匹配就可以使用。
Type:域的类型
Indexed:是否索引
Stored:是否存储
multiValued:是否多值。

3.3uniqueKey
文档的唯一id,每个document必须有一个id域,相当于数据库中表的主键。

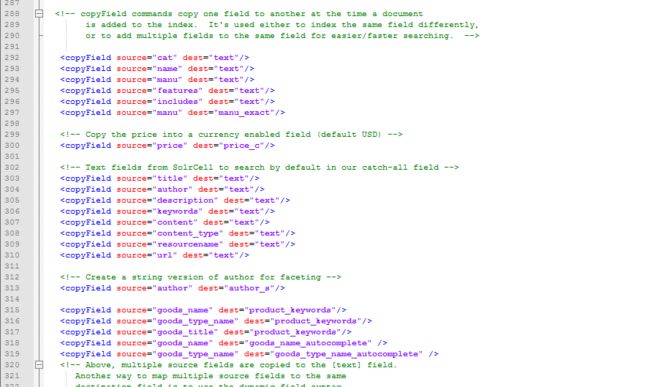
3.4copyField
复制域,功能就是在添加文档的时候自动的把源域的内容复制到目标域。可以把目标域作为默认搜索域可以提高查询的性能。
Source:源域
Dest:目标域
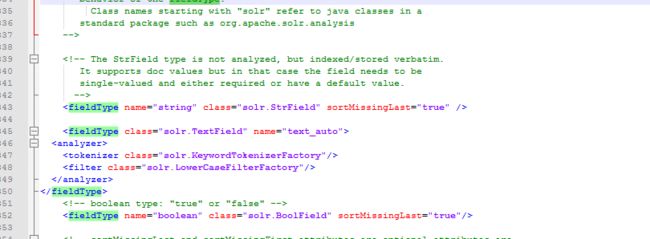
3.5 fieldType
域类型的定义。
Name:域的名称
Class:对应的java 的类,是对应的域的实际类型。
可以定义一个fieldtype使用中文分析器这样就可以满足业务需求。Class必须是class="solr.TextField"
3.6配置中文分析器
需要自定义一个fieldType,并且class是solr.TextField。中文分析器使用的是IK-Analyzer。
3.6.1实现步骤
第一步:把IKAnalyzer2012FF_u1.jar添加到solr工程的lib文件夹下。

第二步:把配置文件和自定义词典和停用词词典添加到solr工程的classpath下。注意词典的字符集是utf-8。(没有就新建一个文件夹)
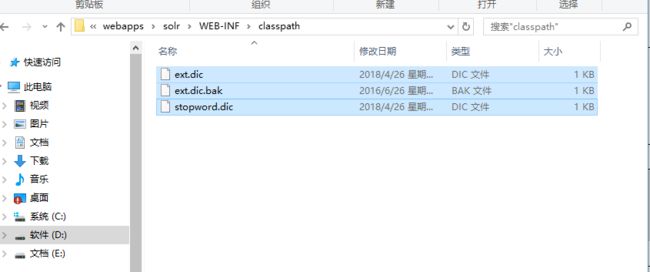
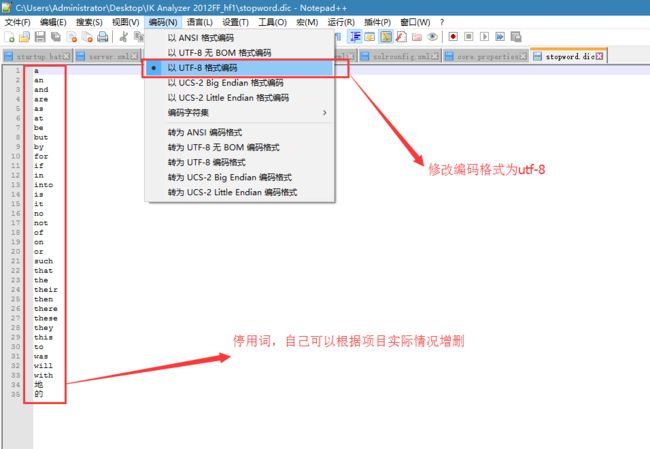
第三步:在schema.xml中添加一个自定义的fieldType。(要注意写在types标签内部,不然没用,自己当时没注意踩过坑T T...)

第四步:定义field,type使用text_ik

<!--IKAnalyzer Field-->
第五步:重新启动tomcat
3.7 设置业务系统Field
如果不使用Solr提供的Field可以针对具体的业务需要自定义一套Field,如下是商品信息Field:

4.索引库的维护
4.1 文档的添加
要求每个文档中必须有一个id域,并且文档中的域必须在shema.xml中定义。

数据格式有很多类型

4.2 文档的删除
4.2.1根据id删除文档
首先把Document Type选为xml,然后执行:
4.2.2 根据查询删除文档

4.3 修改文档
本质也是先删除后添加,只能是添加一个新的文档只要文档的id和被更新的文档一致即可。
4.4 使用dataimport插件批量导入数据
数据源是mysql数据库中的表。

使用dataimport插件把数据库中的数据导入到索引库中。
4.4.1需要用到的jar包:
1. dataimport插件依赖的jar包
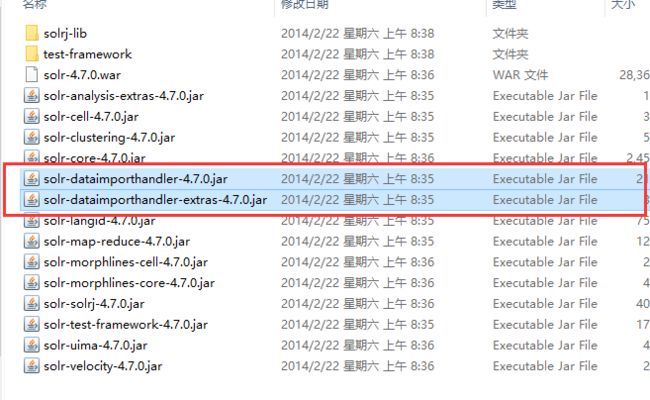
2.mysql的数据库驱动
4.4.2 配置dataimport插件
第一步:把插件依赖的jar包(dataimport插件和mysql)放到collection1\lib文件夹下。

第二步:在solrconfig.xml中添加一个requesthandler节点。
< /lst>
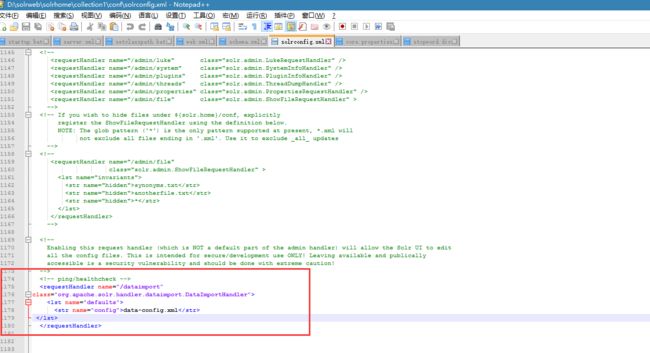
第三步:创建一个data-config.xml放到collection1\conf文件夹下也就是solrconfig.xml 所在的文件夹。


第四步:重启tomcat。
5. 索引库的查询
Q:总查询条件,完全支持lucene的语法。并且支持数值类型的范围查询。
Fq:过滤条件。和查询条条件的查询语法是一样的。并且可以有多个过滤条件,过滤的数据基础是总查询条件得到的结果集。
Sort:排序条件。排序的域 asc|desc,多个过滤条件可以使用半角逗号分隔。
start, rows:分页处理。和mysql的分页处理一样。
Fl:返回结果中域的列表
Df:默认搜素域。
Wt:返回结果的数据格式。可以是json可以是xml
Hl:高亮显示
Hl.fl:高亮显示的域
Hl.simple.pre:高亮显示的前缀
Hl.simple.post:高亮显示的后缀
6.使用SolrJ维护索引库
6.1 环境搭建
我用SpringMVC+Maven搭建项目
第一步:创建一个Maven工程。
第二步:把solr客户端solrj的依赖添加pom.xml
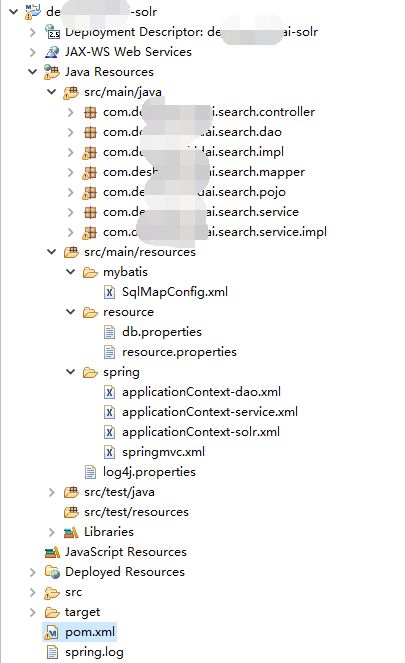

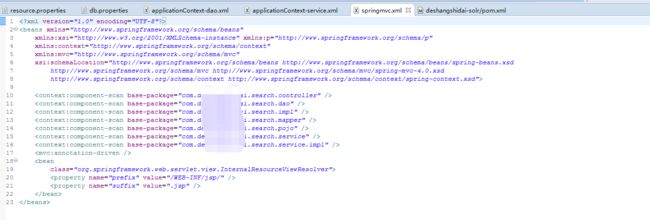
6.1.1相关配置文件
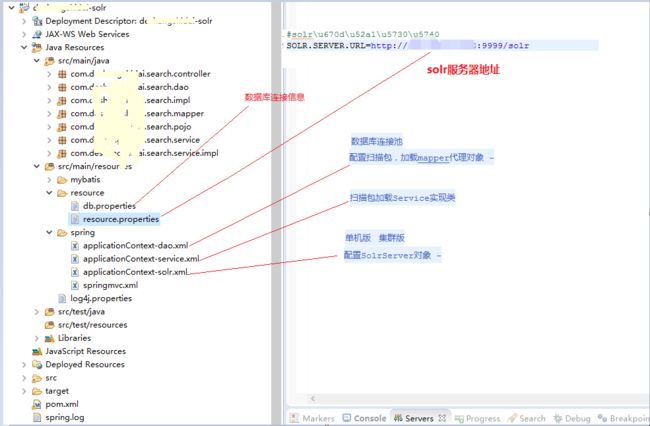
resource.properties

db.properties

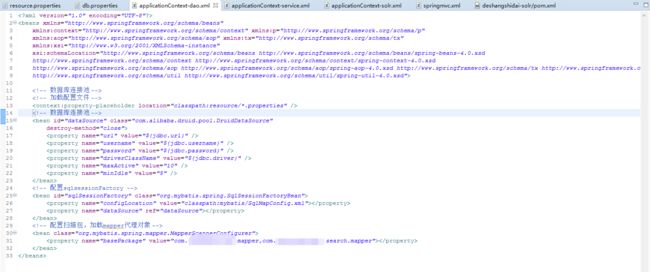
applicationContext-dao.xml
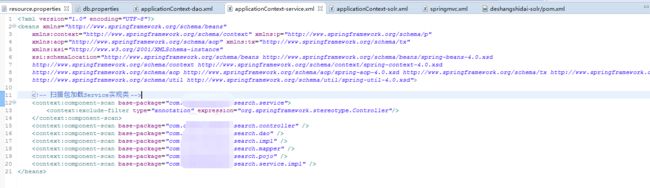
applicationContext-service.xml
applicationContext-solr.xml

springmvc.xml
6.2 使用solrJ维护索引
6.2.1导入商品数据到索引库


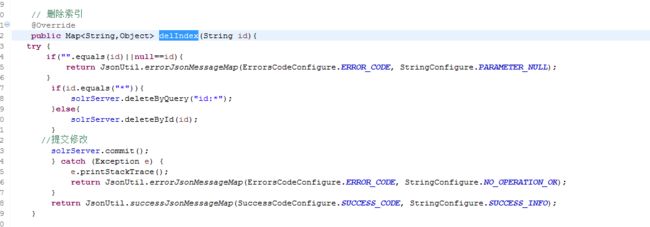
6.2.2 索引库删除商品

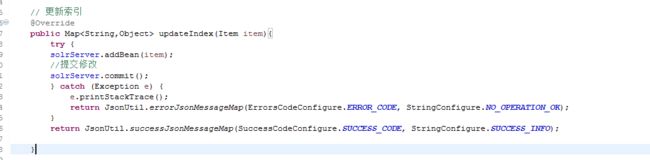
6.2.3,更新索引
6.3 使用solrj查询索引
6.3.1 查询步骤
第一步:创建一个SolrServer对象实现和服务器的连接。
第二步:创建一个SolrQuery对象。
第三步:向solrQuery对象中添加查询条件。
第四步:执行查询。返回一个文档的列表
第五步:遍历返回结果。

代码实现:
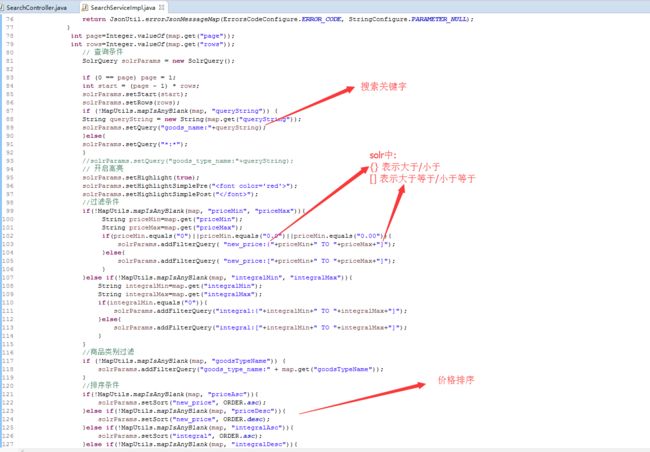
我用Postman测试:
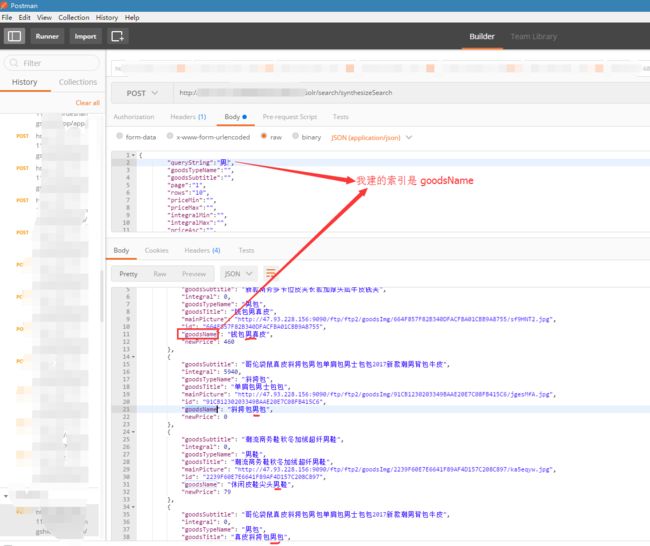
7.0 solr-facet的自动补全
用Suggester的组件来实现自动完成功能
7.1配置
在索引配置之前,我们定义一个searchComponent:
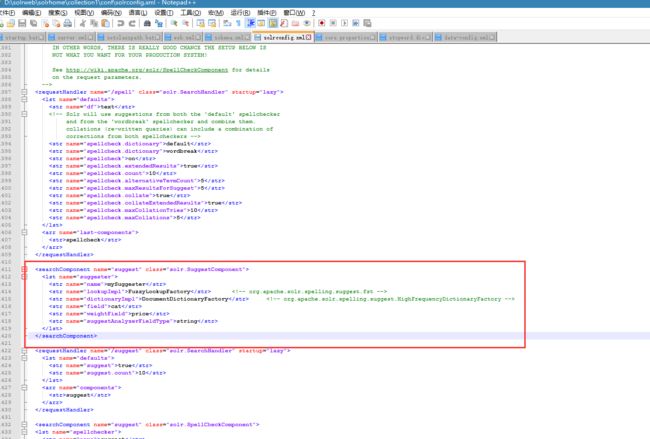
这个组件是基于solr.SpellCheckComponent的,这样我们就可以使用它的一些配置。配置中有3个非常重要的属性:
name:组件名
lookupImpl:绑定这个搜索的对象,目前有两个类可以使用-JasperLookup、TSTLookup,第二个效率更高
field:针对的字段
现在让我们添加合适的handler
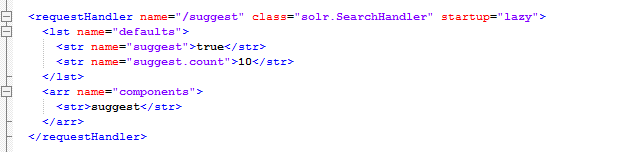
非常简单的配置,它定义了Search的组件,告诉solr每次建议的最大个数为10,使用上面定义的suggest组件。
索引假设我们的文档有三个字段:id、name、description。我们想给name字段做自动完成功能,索引配置则为:

另外,需要定义一个copyFiled:

单词建议为了完成单独词的建议,我们需要定义一个 text_autocomplete的类型:

词组建议如果实现完整的词组建议,我们的text_autocomplete类型应该定义为:
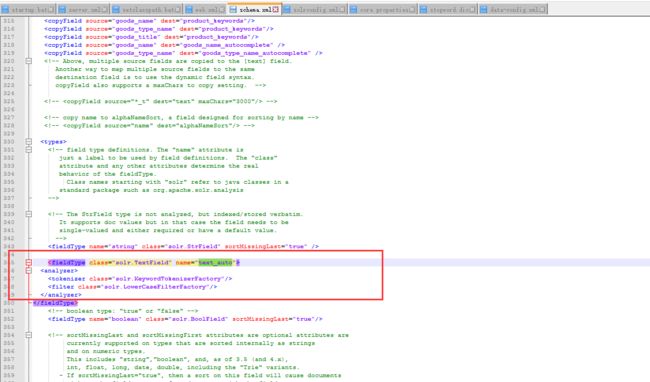
建立词典在我们开始使用该组件前,我们需要对它建立索引,可以使用solr命令:
/suggest?spellcheck.build=true
7.2 查询

