2017年,Google发表论文《Attention is All You Need》,提出经典网络结构Transformer,全部采用Attention结构的方式,代替了传统的Encoder-Decoder框架必须结合CNN或RNN的固有模式。并在两项机器翻译任务中取得了显著效果。该论文一经发出,便引起了业界的广泛关注,同时,Google于2018年发布的划时代模型BERT也是在Transformer架构上发展而来。所以,为了之后学习的必要,本文将详细介绍Transformer模型的网络结构。
1、整体架构
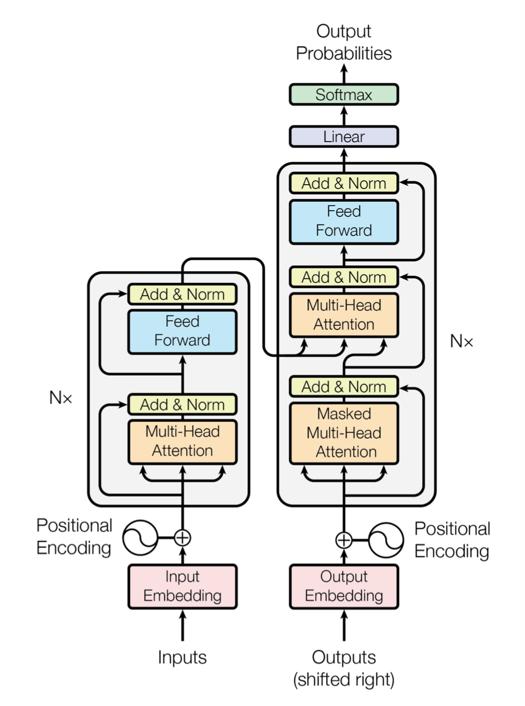
Transformer作为seq2seq,也是由经典的Encoder-Decoder模型组成。在上图中,整个Encoder层由6个左边Nx部分的结构组成。整个Decoder由6个右边Nx部分的框架组成,Decoder输出的结果经过一个线性层变换后,经过softmax层计算,输出最终的预测结果。
(1)、Encoder结构:
输入序列X经过word embedding和positional encoding做直接加和后,作为Encoder部分的输入。输入向量经过一个multi-head self-attention层后,做一次residual connection(残差连接)和Layer Normalization(层归一化,下文中简称LN),输入到下一层position-wise feed-forward network中。之后再进行一次残差连接+LN,输出到Decoder部分,这里所涉及到的相关知识会在下文中详细介绍。
(2)、Decoder结构:
输出序列Y经过word embedding和positional encoding做直接加和后,作为Decoder部分的输入。很多对seq2seq不了解的朋友看到这里可能有些糊涂,简单说明以下。以翻译任务为例,假设我们要进行一个中译英任务。我们现在有一段中文序列X,对应的英文序列Y。我们在翻译出某个单词Yt时,并非只是用中文序列X翻译,而是用中文序列X加已经翻译出来的英文序列(y1,y2,……yt-1)进行翻译,所以也要将已经翻译出来的英文序列输入其中。这也就解释了为什么会将输出序列Y作为Decoder的输入。在论文中,在训练过程中为了处理方便同时不引入未来信息,采用了一种sequence masking机制,具体的实现下文再详细介绍。
Decoder部分的输入向量首先经过一层multi-head self-attention,进行一次残差连接+LN,再经过一层multi-head context-attention,进行一次残差连接+LN,最后再经过一层position-wise feed-forward network,进行一次残差连接+LN后,输出至线性层。
以上介绍了Encoder和Decoder的基本流程,相信大家对其中具体的实现还有不明白的细节,下面我就来为大家一一阐述。
2、Attention机制
上文中提到了两个Attenton结构,multi-head self-attention和multi-head context-attention可以说是本文中最重要的概念,这里来解释下两者的实现,首先,我们来回顾以下基础的Attention机制。
(1)、基础Attention机制
之前曾经写过一篇详细介绍Attention的文章,感兴趣的朋友可以关注我的公众号查找,这里主要使用论文中描述的方式来简单介绍以下基础Attention。
在自然语言处理中,Attention的本质可以理解为一个查询(query)到一些列(key - value)对的映射。以基础的Attention计算公式为例:
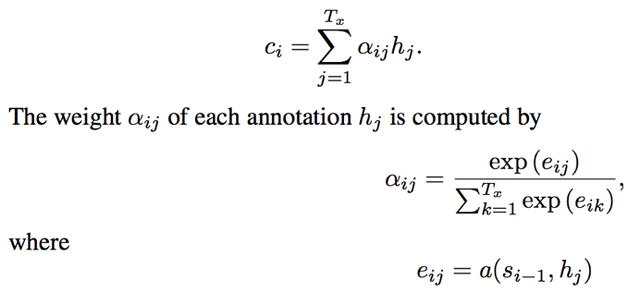
计算attention时:第一步,将query和每个key进行相似度计算得到权重,即上图中的第三个公式。第二步,一般使用一个softmax函数将这些权重进行归一化,即上图中的第二个公式,最后将权重和相应的键值value进行加权求和,得到最终的attention,即第一个公式。通常key和value取值相同,例如上图中,key=value=hj, query=si-1。
其实,Google所用到的基本attention思路是与上面一致的,只是在计算Attention分数时,采用了另一种计算机制:Scaled dot-product attention
(2)、Scaled dot-product attention
Scaled dot-product attention的计算公式如下:
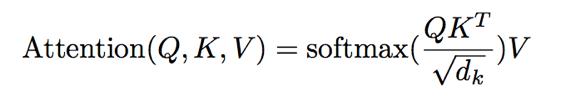
其实基本元素还是Q,K,V三项,无非就是公式变了下。具体的计算图结构文章中也给了图,公式很清晰这里就不列了。
(3)Self-attention 和Context-attention
Self-attention:自己跟自己做Attention,输入序列=输出序列。Q=K=V。
Context-attention:Encoder输出结果跟Decoder第一部分输出结果之间做Attention。
具体到网络结构中:
Encoder中的self-attention,Q,K,V均为Encoder的输入。
Decoder中的self-attention,Q,K,V均为Decoder的输入,也就是上一层Decoder的输入,具体原因见Decoder的介绍。
Decoder中context-attention,Q为decoder中第一部分的输出,K,V均为encoder的输出。
(4)、Multi-head attention
论文中采用的Multi-head attention,就是将Q, K, V先经过一个线性映射,再在在输入维度dk,dq,dv上切分成h份,再对每一份进行Scaled dot-product attention,之后将每部分结果合并起来,经过线性映射,得到最终的输出,结构图如下:
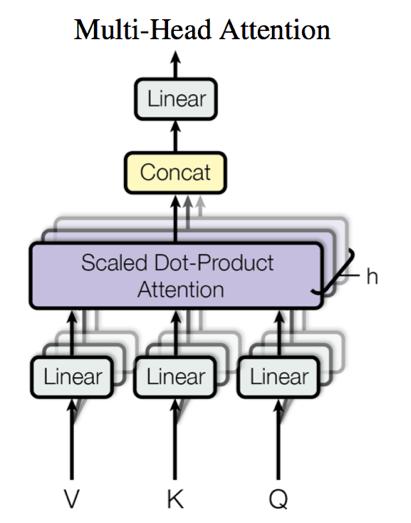
说的有些绕,举个例子,原文中d=512(即词向量和位置向量的维度),h=8。那么假设原始输入为[batch_size*seq_len*512]的三维表,处理后共分成8份[batch_size*seq_len* 64]的三维表,每份分别做Scaled dot-product,就是Multi-head attention了。这样进行了h次运算,可以允许模型在不同的表示子空间中学习到相关信息。
以上就是Attention部分的全部讲解,说清楚这一部分,其他的都是一些零碎的细节。
3、Position-wise Feed-Forward network
一个全联接神经网络,先进行一次线性变换,再通过一次ReLU激活函数,最后再进行一次线性变化。公式如下:
4、Positional encoding
位置编码,顾名思义,对序列中词语的位置进行编码,公式如下:

即奇数位置用余弦编码,偶数位置用正弦编码,最终得到一个512维的位置向量。
5、Residual connection
残差连接其实在很多网络机构中都有用到。原理很简单,假设一个输入向量x,经过一个网络结构,得到输出向量f(x),加上残差连接,相当于在输出向量中加入输入向量,即输出结构变为f(x)+x,这样做的好处是在对x求偏导时,加入一项常数项1,避免了梯度消失的问题。
6、Layer Normalization
归一化的本质都是将数据转化为均值为0,方差为1的数据。这样可以减小数据的偏差,规避训练过程中梯度消失或爆炸的情况。我们在训练网络中比较常见的归一化方法是Batch Normalization,即在每一层输出的每一批数据上进行归一化。而Layer Normalization与BN稍有不同,即在每一层输出的每一个样本上进行归一化。
7、Mask
mask的思想非常简单:就是对输入序列中没某些值进行掩盖,使其不起作用。在论文中,做multi-head attention的地方用到了padding mask,在decode输入数据中用到了sequence mask。
(1)、padding mask
在我们输入的数据中,因为每句话的长度不同,所以要对较短的数据进行填充补齐长度。而这些填充值并没有什么作用,为了减少填充数据对attention计算的影响,采用padding mask的机制,即在填充物的位置上加上一个趋紧于负无穷的负数,这样经过softmax计算后这些位置的概率会趋近于0
(2)、sequence mask
在上文中我们提到,预测t时刻的输出值yt,应该使用全部的输入序列X,和t时刻之前的输出序列(y1,y2,……,yt-1)进行预测。所以在训练时,应该将t-1时刻之后的信息全部隐藏掉。所以需要用到sequence mask。
实现也很简单,就是用一个上三角矩阵,上三角值均为1,下三角值均为0,对角线值为0,与输入序列相乘,就达到了目的。
以上就是Transformer框架的全部知识点,BERT模型也是在此基础上发展而来。