ELK(七):ElasticSearch常用命令
- ElasticSearch常用命令
- 1、启动
- 2、ELasticsearch集群已经启动并且正常运行
- 3、计算集群中的文档数量
- 4、查看集群健康状况
- 5、查看my_index的mapping和setting的相关信息
- 6、查看所有的index
- 7、空查询
- 8、分页搜索
- 9、range查询
- 10、组合查询
- 11、带过滤器的查询
- 12、验证查询
- 13、删除索引
- 14、只查询部分字段
- 15、修改密码
- 16、其它命令
ElasticSearch常用命令
1、启动
bin/elasticsearch
2、ELasticsearch集群已经启动并且正常运行
curl http://127.0.0.1:9200/?pretty3、计算集群中的文档数量
curl -XGET http://127.0.0.1:9200/_count?pretty -d "{\"query\": {\"match_all\": {} }}"
我们看不到HTTP头是因为我们没有让curl显示它们,如果要显示,使用curl命令后跟-i参数:
curl -i -XGET localhost:9200/
4、查看集群健康状况
GET /_cat/health?v
curl -XGET http://127.0.0.1:9200/_cat/health?v

5、查看my_index的mapping和setting的相关信息
GET /index_china?pretty
curl -XGET http://127.0.0.1:9200/index_china?pretty 
6、查看所有的index
GET /_cat/indices?v
curl -XGET http://127.0.0.1:9200/_cat/indices?v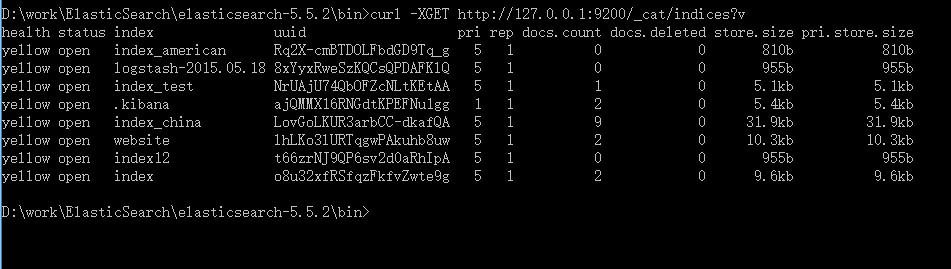
7、空查询
GET /_search8、分页搜索
GET /_search?from=0&size=5 从0页开始搜索,每页大小是5个记录
GET /_search?from=1&size=5 从1页开始搜索,每页大小是5个记录
POST /_search // 从1页开始搜索,每页大小是5个记录,和上面的效果一样
{
"from": 1,
"size": 5
}9、range查询
range 查询找出那些落在指定区间内的数字或者时间:
被允许的操作符如下:
- gt:大于
- gte:大于等于
- lt:小于
- lte:小于等于
GET /index_china/fulltext/_search
{
"query": {
"range": {
"age": {
"gte": 20,
"lt": 50
}
}
}
} 
10、组合查询
现实的查询需求从来都没有那么简单;它们需要在多个字段上查询多种多样的文本,并且根据一系列的标准来过滤。为了构建类似的高级查询,你需要一种能够将多查询组合成单一查询的查询方法。
你可以用 bool 查询来实现你的需求。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
- must:文档 必须 匹配这些条件才能被包含进来。
- must_not:文档 必须不 匹配这些条件才能被包含进来。
- should:如果满足这些语句中的任意语句,将增加
_score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。 - filter:必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
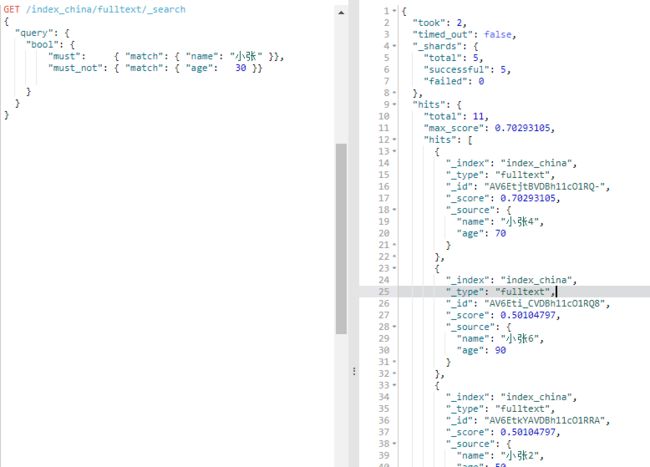
GET /index_china/fulltext/_search
{
"query": {
"bool": {
"must": { "match": { "name": "小张" }},
"must_not": { "match": { "age": 30 }}
}
}
} 
11、带过滤器的查询
GET /index_china/fulltext/_search
{
"query": {
"bool": {
"must": { "match": { "name": "小张" }},
"must_not": { "match": { "age": 30 }},
"filter": {
"range": { "age": { "gte": "80" }}
}
}
}
}
通过将 range 查询移到 filter 语句中,我们将它转成不评分的查询,将不再影响文档的相关性排名。由于它现在是一个不评分的查询,可以使用各种对 filter 查询有效的优化手段来提升性能。
所有查询都可以借鉴这种方式。将查询移到 bool 查询的 filter 语句中,这样它就自动的转成一个不评分的 filter 了。
如果你需要通过多个不同的标准来过滤你的文档,bool 查询本身也可以被用做不评分的查询。简单地将它放置到 filter 语句中并在内部构建布尔逻辑:
GET /index_china/fulltext/_search
{
"query": {
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
}12、验证查询
查询可以变得非常的复杂,尤其 和不同的分析器与不同的字段映射结合时,理解起来就有点困难了。不过 validate-query API 可以用来验证查询是否合法。
GET /index_china/fulltext/_validate/query
{
"query": {
"fulltext" : {
"match" : "really powerful"
}
}
}
说明以上 validate 请求的应答告诉我们这个查询是不合法的
理解错误信息
GET /index_china/fulltext/_validate/query?explain
{
"query": {
"fulltext" : {
"match" : "really powerful"
}
}
}explain参数可以提供更多关于查询不合法的信息

很明显,我们将查询类型(match)与字段名称 (fulltext)搞混了:
理解查询语句
对于合法查询,使用 explain 参数将返回可读的描述,这对准确理解 Elasticsearch 是如何解析你的 query 是非常有用的
GET /_validate/query?explain
{
"query": {
"match" : {
"fulltext" : "really powerful"
}
}
} 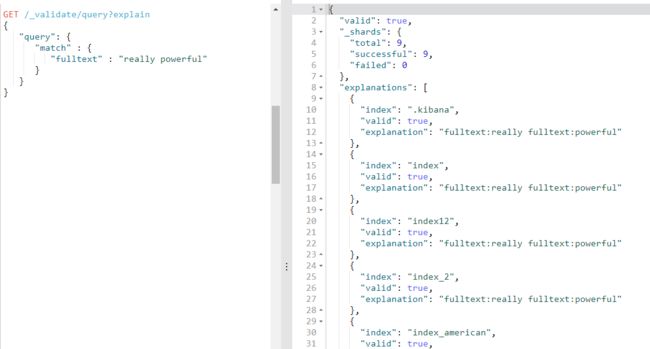
我们查询的每一个 index 都会返回对应的 explanation ,因为每一个 index 都有自己的映射和分析器;
13、删除索引
# 用以下的请求来 删除索引:
DELETE /my_index
# 你也可以这样删除多个索引:
DELETE /index_one,index_two
DELETE /index_*
# 你甚至可以这样删除 全部 索引:
DELETE /_all
DELETE /*
对一些人来说,能够用单个命令来删除所有数据可能会导致可怕的后果。如果你想要避免意外的大量删除, 你可以在你的 elasticsearch.yml 做如下配置:
action.destructive_requires_name: true
这个设置使删除只限于特定名称指向的数据, 而不允许通过指定 _all 或通配符来删除指定索引库。你同样可以通过 Cluster State API 动态的更新这个设置。
14、只查询部分字段
在一个搜索请求里,你可以通过在请求体中指定 _source 参数,来达到只获取特定的字段的效果:
查询所有字段


GET /ott_test/ott_type/_search
{
"query": {"match_all": {}}
}
#只查询title和date两个字段的数据
GET /ott_test/ott_type/_search
{
"query": {"match_all": {}},
"_source": ["title","date"]
}15、修改密码
假设用户名:ctr,密码elastic1, 登录后修改如下

16、其它命令
集群健康:GET _cluster/health
监控单个节点:GET _nodes/stats
集群统计:GET _cluster/stats
索引统计:GET ott_test/_stats;GET ott_test,ott/_stats;GET _all/_stats
xpack模块命令:GET /_xpack