一文读懂APU/BPU/CPU/DPU/EPU/FPU/GPU等处理器
致谢:一文读懂APU/BPU/CPU/DPU/EPU/FPU/GPU等处理器
随着AI概念火爆全球,做AI芯片的公司也层出不穷。为了让市场和观众能记住自家的产品,各家在芯片命名方面都下了点功夫,既要独特,又要和公司产品契合,还要朗朗上口,也要容易让人记住。比较有意思的是,很多家都采用了“xPU”的命名方式。
本文就来盘点一下目前各种“xPU”命名AI芯片,以及芯片行业里的各种“xPU”缩写,供吃瓜群众消遣,也供后来者起名参考。此外,除了“xPU”命名方式,本文也扩展了一些“xxP”方式的以Processor命名的芯片或IP。此外的此外,拍脑袋拍出了一些xPU命名备选方案,用下划线标示,并欢迎读者一起来开脑洞。
有心在AI芯片发力的公司,赶紧先抢个字母吧。
APU
Accelerated Processing Unit。目前还没有AI公司将自己的 处理器命名为APU,因为AMD早就用过APU这个名字了。APU是AMD的一个处理器品牌。AMD在一颗芯片上集成传统CPU和图形处理器GPU,这样主板上将不再需要北桥,任务可以灵活地在CPU和GPU间分配。AMD将这种异构结构称为加速处理单元,即APU。
Audio Processing Unit。声音处理器,顾名思义,处理声音数据的专用处理器。不多说,生产APU的芯片商有好多家。声卡里都有。
BPU
Brain Processing Unit。地平线机器人(Horizon Robotics)以BPU来命名自家的AI芯片。地平线是一家成立于2015年的start-up,总部在北京,目标是“嵌入式人工智能全球领导者”。地平线的芯片未来会直接应用于自己的主要产品中,包括:智能驾驶、智能生活和智能城市。地平线机器人的公司名容易让人误解,以为是做“机器人”的,其实不然。地平线做的不是“机器”的部分,是在做“人”的部分,是在做人工智能的“大脑”,所以,其处理器命名为BPU。相比于国内外其他AI芯片start-up公司,地平线的第一代BPU走的相对保守的TSMC的40nm工艺。BPU已经被地平线申请了注册商标,其他公司就别打BPU的主意了。

Biological Processing Unit。一个口号“21 世纪是生物学的世纪”忽悠了无数的有志青年跳入了生物领域的大坑。其实,这句话需要这么理解,生物学的进展会推动21世纪其他学科的发展。比如,对人脑神经系统的研究成果就会推动AI领域的发展,SNN结构就是对人脑神经元的模拟。不管怎么说,随着时间的推移,坑总会被填平的。不知道生物处理器在什么时间会有质的发展。
Bio-Recognition Processing Unit。生物特征识别现在已经不是纸上谈兵的事情了。指纹识别已经是近来智能手机的标配,电影里的黑科技虹膜识别也上了手机,声纹识别可以支付了...不过,除了指纹识别有专门的ASIC芯片外,其他生物识别还基本都是sensor加通用cpu/dsp的方案。不管怎样,这些芯片都没占用BPU或BRPU这个宝贵位置。
CPU
CPU就不多说了,也不会有AI公司将自己的处理器命名为CPU的。不过,CPU与AI处理器并不冲突。
首先,很多公司的AI处理器中还是会使用CPU做控制调度。比如,wave computing用的是Andes的CPU core;Mobileye用了好几个MIPS的CPU core;国内的某些AI芯片公司用的ARM的CPU core。
此外,在现有的移动市场的AP中,在CPU之外,再集成一两个AI加速器IP(例如针对视觉应用的DSP,见VPU部分)也是一种趋势。例如,华为近期就在为其集成了AI加速器的麒麟970做宣传。
另外一种趋势,做高性能计算CPU的公司也不甘错过AI的浪潮。例如,
Adapteva 一家做多核MIMD结构处理器的公司。2016年tapeout的Epiphany V集成有1024个核。相对以前的版本,针对deep learning和加密增加了特定指令。
kalrayinc 一家做多核并行处理器的公司,有针对数据中心和自动驾驶的解决方案。最近公布了第三代MPPA处理器“Coolidge”的计划,并融资$26 Million。计划采用16nm FinFET工艺,集成80-160个kalray 64-bit core,以及80-160个用于机器视觉处理和深度学习计算的协处理器。
DPU
D是Deep Learning的首字母,以Deep Learning开头来命名AI芯片是一种很自然的思路。
Deep-Learning Processing Unit。深度学习处理器。DPU并不是哪家公司的专属术语。在学术圈,Deep Learning Processing Unit(或processor)被经常提及。例如ISSCC 2017新增的一个session的主题就是Deep Learning Processor。以DPU为目标的公司如下。
Deephi Tech(深鉴) 深鉴是一家位于北京的start-up,初创团队有很深的清华背景。深鉴将其开发的基于FPGA的神经网络处理器称为DPU。到目前为止,深鉴公开发布了两款DPU:亚里士多德架构和笛卡尔架构,分别针对CNN以及DNN/RNN。虽然深鉴号称是做基于FPGA的处理器开发,但是从公开渠道可以看到的招聘信息以及非公开的业内交流来看,其做芯片已成事实。

TensTorrent 一家位于Toronto的start-up,研发专为深度学习和智能硬件而设计的高性能处理器,技术人员来自NVDIA和AMD。
Deep Learning Unit。深度学习单元。Fujitsu(富士通)最近高调宣布了自家的AI芯片,命名为DLU。名字虽然没什么创意,但是可以看到DLU已经被富士通标了“TM”,虽然TM也没啥用。在其公布的信息里可以看到,DLU的ISA是重新设计的,DLU的架构中包含众多小的DPU(Deep Learning Processing Unit)和几个大的master core(控制多个DPU和memory访问)。每个DPU中又包含了16个DPE(Deep-Learning Processing Element),共128个执行单元来执行SIMD指令。富士通预计2018财年内推出DLU。

Deep Learning Accelerator。深度学习加速器。NVIDA宣布将这个DLA开源,给业界带来了不小的波澜。大家都在猜测开源DLA会给其他AI公司带来什么。参考这篇吧"从Nvidia开源深度学习加速器说起"
Dataflow Processing Unit。数据流处理器。创立于2010年的wave computing公司将其开发的深度学习加速处理器称为Dataflow Processing Unit(DPU),应用于数据中心。Wave的DPU内集成1024个cluster。每个Cluster对应一个独立的全定制版图,每个Cluster内包含8个算术单元和16个PE。其中,PE用异步逻辑设计实现,没有时钟信号,由数据流驱动,这就是其称为Dataflow Processor的缘由。使用TSMC 16nm FinFET工艺,DPU die面积大概400mm^2,内部单口sram至少24MB,功耗约为200W,等效频率可达10GHz,性能可达181TOPS。前面写过一篇他家DPU的分析,见传输门AI芯片|浅析Yann LeCun提到的两款Dataflow Chip。

Digital Signal Processor。数字信号处理器。芯片行业的人对DSP都不陌生,设计DSP的公司也很多,TI,Qualcomm,CEVA,Tensilica,ADI,Freescale等等,都是大公司,此处不多做介绍。相比于CPU,DSP通过增加指令并行度来提高数字计算的性能,如SIMD、VLIW、SuperScalar等技术。面对AI领域新的计算方式(例如CNN、DNN等)的挑战,DSP公司也在马不停蹄地改造自己的DSP,推出支持神经网络计算的芯片系列。在后面VPU的部分,会介绍一下针对Vision应用的DSP。和CPU一样,DSP的技术很长时间以来都掌握在外国公司手里,国内也不乏兢兢业业在这方向努力的科研院所,如清华大学微电子所的Lily DSP(VLIW架构,有独立的编译器),以及国防科大的YHFT-QDSP和矩阵2000。但是,也有臭名昭著的“汉芯”。
EPU
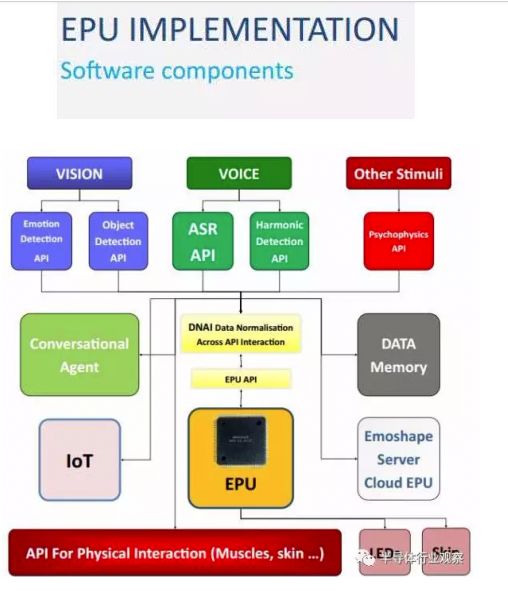
Emotion Processing Unit。Emoshape 并不是这两年才推出EPU的,号称是全球首款情绪合成(emotion synthesis)引擎,可以让机器人具有情绪。但是,从官方渠道消息看,EPU本身并不复杂,也不需要做任务量巨大的神经网络计算,是基于MCU的芯片。结合应用API以及云端的增强学习算法,EPU可以让机器能够在情绪上了解它们所读或所看的内容。结合自然语言生成(NLG)及WaveNet技术,可以让机器个性化的表达各种情绪。例如,一部能够朗读的Kindle,其语音将根据所读的内容充满不同的情绪状态。
FPU
先说一个最常用的FPU缩写:Floating Point Unit。浮点单元,不多做解释了。现在高性能的CPU、DSP、GPU内都集成了FPU做浮点运算。
Force Processing Unit。原力处理器,助你成为绝地武士。酷!
GPU
Graphics Processing Unit。图形处理器。GPU原来最大的需求来自PC市场上各类游戏对图形处理的需求。但是随着移动设备的升级,在移动端也逐渐发展起来。
NVIDIA 说起GPU,毫无疑问现在的老大是NVIDIA。这家成立于1993年的芯片公司一直致力于设计各种GPU:针对个人和游戏玩家的GeForce系列,针对专业工作站的Quadro系列,以及针对服务器和高性能运算的Tesla系列。随着AI的发展,NVIDIA在AI应用方面不断发力,推出了针对自动驾驶的DRIVE系列,以及专为AI打造的VOLTA架构。特别提一下VOLTA,今年5月份,NVIDIA发布的Tesla V100采用TSMC 12nm工艺,面积竟然815mm^2,号称相关研发费用高达30亿美元。得益于在AI领域的一家独大,NVIFIA的股价在过去一年的时间里狂涨了300%。最后,也别忘了NVIDIA家还有集成了GeForce GPU的Tegra系列移动处理器。
AMD 这几年NVIDIA的火爆,都快让大家忘了AMD的存在了。AMD是芯片行业中非常古老的一家芯片公司,成立于1969年,比NVIDIA要早很多年。AMD最出名的GPU品牌Radeon来自于其2006年以54亿美元收购的ATI公司(暴露年龄地说,本人的第一台PC的显卡就是ATI的)。本文第一个词条APU就是AMD家的产品。AMD新出的MI系列GPU将目标对准AI。

在移动端市场,GPU被三家公司瓜分,但是也阻止不了新的竞争者杀入。
ARM家的Mali Mali不是ARM的自创GPU品牌,来自于ARM于2006年收购的Falanx公司。Falanx最初的GPU是面向PC市场的,但是根本就无法参与到NVIDIA和ATI的竞争中去,于是转向移动市场;并且Falanx最初的GPU的名字也不是Mali,而是Maliak,为了好记,改为Mali,来自罗马尼亚文,意思是small,而不是我们熟悉的吃蘑菇救公主的超级玛丽(SuperMALI)。
Imagination的PowerVR 主要客户是苹果,所以主要精力都在支持苹果,对其他客户的支持不足。但是,苹果突然宣布放弃PVR转为自研,对Imagination打击不小,股价大跌六成。Imagination现在正在寻求整体出售,土财快追,但是,美国未必批。
Qualcomm的Adreno 技术来自于AMD收购ATI后出售的移动GPU品牌Imageon。有意思的是,名字改自于ATI的知名GPU品牌Radeon;
VeriSilicon的Vivante Vivante(图芯)是一家成立于2004年的以做嵌入式GPU为主的芯片公司,于2015年被VSI收购。Vivante的市场占有率较低。这里多加一段小八卦,Vivante的创始人叫戴伟进,VSI的创始人叫戴伟民,一句话对这次收购进行总结就是,戴家老大收购了戴家老二。哦,对了,戴家还有一个三妹戴伟立,创立的公司名号更响亮:Marvell。
Samsung的。。。哦,三星没有自己的GPU。作为一个IDM巨头,对于没有自家的GPU,三星一直耿耿于怀。三星也宣布要研发自家的移动端GPU芯片,不过要等到2020年了。
再简单补充国内的两家开发GPU的公司:
上海兆芯 兆芯是VIA(威盛)分离出来的。兆芯于2016年针对移动端出了一款GPU芯片ZX-2000,名字有点简单直接。主要技术来源于威盛授权,GPU核心技术来自收购的美国S3 Graphics。
长沙景嘉微电子 于2014年推出一款GPU芯片JM5400。这是一家有国防科大背景的公司,与龙芯为合作伙伴,芯片主要应用在军用飞机和神舟飞船上。
Graph Streaming Processor。图形流处理器。这是ThinCI(取意think-eye)提出的缩写。ThinCI是一家致力于打造deep learning和computer vision芯片的start-up,由4名Intel前员工创立于2010年,总部在Sacramento,在印度也有研发人员。ThinCI的视觉芯片瞄准了自动驾驶应用,投资方有世界顶级汽车零部件供应商公司日本电装DENSO。在刚结束的hotchip会议上,ThinCI介绍了他们的GSP(于是本文作者将ThinCI从VPU部分移到了这里),使用了多种结构性技术来实现任务级、线程级、数据级和指令级的并行。GSP使用TSMC 28nm HPC+工艺,功耗预计2.5W。
HPU
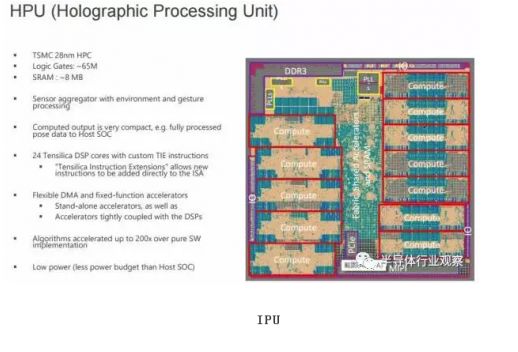
Holographic Processing Unit。全息处理器。Microsoft专为自家Hololens应用开发的。第一代HPU采用28nm HPC工艺,使用了24个Tensilica DSP并进行了定制化扩展。HPU支持5路cameras、1路深度传感器(Depth sensor)和1路动作传感器(Motion Sensor)。Microsoft 在最近的CVPR 2017上宣布了HPU2的一些信息。HPU2将搭载一颗支持DNN的协处理器,专门用于在本地运行各种深度学习。指的一提的是,HPU是一款为特定应用所打造的芯片,这个做产品的思路可以学习。据说Microsoft评测过Movidius(见VPU部分)的芯片,但是觉得无法满足算法对性能、功耗和延迟的要求,所有才有了HPU。
IPU
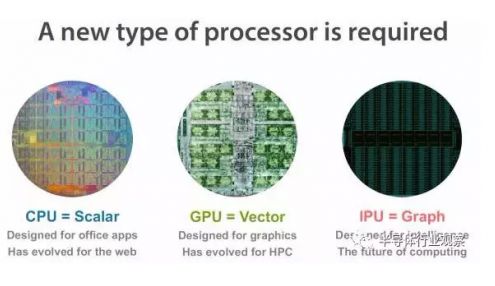
Intelligence Processing Unit。智能处理器。以IPU命名芯片的有两家公司。
Graphcore Graphcore公司的IPU是专门针对graph的计算而打造的。稍微说说Graph,Graphcore认为Graph是知识模型及相应算法的非常自然的表示,所以将Graph作为机器智能的基础表示方法,既适用于神经网络,也适用于贝叶斯网络和马尔科夫场,以及未来可能出现的新的模型和算法。Graphcore的IPU一直比较神秘,直到近期才有一些细节的信息发布。比如:16nm,同构多核(>1000)架构,同时支持training和inference,使用大量片上sram,性能优于Volta GPU和TPU2,预计2017年底会有产品发布,等等。多八卦一点,Graphcore的CEO和CTO以前创立的做无线通信芯片的公司Icera于2011年被Nvidia收购并于2015年关闭。关于IPU更细节的描述,可以看唐博士的微信公号的一篇文章,传输门:解密又一个xPU:Graphcore的IPU。
Mythic 另外一家刚融了$9.3 million的start-up公司Mythic也提到了IPU:“Mythic's intelligence processing unit (IPU) adds best-in-class intelligence to any device”。和现在流行的数字电路平台方案相比,Mythic号称可以将功耗降到1/50。之所以这么有信心,是因为他们使用的“processing in memory”结构。关于Processing in Memory,又可以大写一篇了,这里就不扩展了。有兴趣的,可以google一下“UCSB 谢源”,从他的研究开始了解。
Image Cognition Processor。图像认知处理器ICP,加拿大公司CogniVue开发的用于视觉处理和图像认知的IP。跑个题,CogniVue一开始是Freescale的IP供应商,后来于2015年被Freescale收购以进一步加强ADAS芯片的整合开发;随后,Freescale又被NXP 118亿美元拿下;还没完,高通近400亿美元吞并了NXP。 现在NXP家的ADAS SOC芯片S32V系列中,就用到了两个ICP IP。

Image Processing Unit。图像处理器。一些SOC芯片中将处理静态图像的模块称为IPU。但是,IPU不是一个常用的缩写,更常见的处理图像信号的处理器的缩写为下面的ISP。
Image Signal Processor 。图像信号处理器。这个话题也不是一个小话题。ISP的功能,简单的来说就是处理camera等摄像设备的输出信号,实现降噪、Demosaicing、HDR、色彩管理等功能。以前是各种数码相机、单反相机中的标配。Canon、Nikon、Sony等等,你能想到的出数码相机的公司几乎都有自己的ISP。进入手机摄影时代,人们对摄影摄像的要求也越来越高,ISP必不可少。说回AI领域,camera采集图像数据,也要先经过ISP进行处理之后,再由视觉算法(运行在CPU、GPU或ASIC加速器上的)进行分析、识别、分类、追踪等进一步处理。也许,随着AI技术发展,ISP的一些操作会直接被end-2-end的视觉算法统一。
JPU
请原谅鄙人的词汇量,没什么新奇的想法。。。。
KPU
Knowledge Processing Unit。 嘉楠耘智(canaan)号称2017年将发布自己的AI芯片KPU。嘉楠耘智要在KPU单一芯片中集成人工神经网络和高性能处理器,主要提供异构、实时、离线的人工智能应用服务。这又是一家向AI领域扩张的不差钱的矿机公司。作为一家做矿机芯片(自称是区块链专用芯片)和矿机的公司,嘉楠耘智累计获得近3亿元融资,估值近33亿人民币。据说嘉楠耘智近期将启动股改并推进IPO。
另:Knowledge Processing Unit这个词并不是嘉楠耘智第一个提出来的,早在10年前就已经有论文和书籍讲到这个词汇了。只是,现在嘉楠耘智将KPU申请了注册商标。
LPU
谁给我点灵感?
MPU
Micro Processing Unit。微处理器。MPU,CPU,MCU,这三个概念差不多,知道就行了。
Mind Processing Unit。意念处理器,听起来不错。“解读脑电波”,“意念交流”,永恒的科幻话题。如果采集大量人类“思考”的脑电波数据,通过深度学习,再加上强大的意念处理器MPU,不知道能否成为mind-reader。如果道德伦理上无法接受,先了解一下家里宠物猫宠物狗的“想法”也是可以的吗。再进一步,从mind-reader发展为mind-writer,持续升级之后,是不是就可以成为冰与火中的Skinchanger?
Mobile Processing Unit。移动处理器,似乎没什么意思。
Motion Processing Unit。运动处理器。解析人类、动物的肌肉运动?
题外话:并不是所有的xPU都是处理器,比如有个MPU,是Memory Protection Unit的缩写,是内存保护单元,是ARM核中配备的具有内存区域保护功能的模块。
NPU
Neural-Network Processing Unit。与GPU类似,神经网络处理器NPU已经成为了一个通用名词,而非某家公司的专用缩写。由于神经网络计算的类型和计算量与传统计算的区别,导致在进行NN计算的时候,传统CPU、DSP甚至GPU都有算力、性能、能效等方面的不足,所以激发了专为NN计算而设计NPU的需求。这里罗列几个以NPU名义发布过产品的公司,以及几个学术圈的神经网络加速器。
中星微电子(Vimicro)的星光智能一号。中星微于2016年抢先发布了“星光智能一号”NPU。但是,这不是一个专为加速Neural Network而开发的处理器。业内都知道其内部集成了多个DSP核(其称为NPU core),通过SIMD指令的调度来实现对CNN、DNN的支持。以这个逻辑,似乎很多芯片都可以叫NPU,其他以DSP为计算核心的SOC芯片的命名和宣传都相对保守了。

Kneron 这是一家位于San Diego的start-up公司,针对IOT应用领域做deep learning IP开发。Kneron开发的NPU实现了39层CNN,28nm下的功耗为0.3W,能效200GFLOPs/W。其主页上给出的另一个能效数据是600GOPs/W。此外,Kneron同时也在FPGA开发云端的硬件IP。据可靠消息,Kneron也要在中国大陆建立研发部门了,地点涉及北京、上海、深圳。

VeriSilicon(芯原)的VIP8000。VSI创立于2001年。VSI于今年5月以神经网络处理器IP的名义发布了这款代号VIP8000的IP。从其公布的消息“VeriSilicon’s Vivante VIP8000 Neural Network Processor IP Delivers Over 3 Tera MACs Per Second”来看,这款芯片使用的并不是其DSP core,而是内置了其2015年收购的Vivante的GPU core。按照VSI的说法,VIP8000在16nm FinFET工艺下的计算力超过3 TMAC/s,能效高于1.5 GMAC/s/mW。
DNPU。Deep Neural-Network Processing Unit。DNPU来自于KAIST在ISSCC2017上发表的一篇文章。我把DNPU当做是NPU的一种别名,毕竟现在业内做的支持神经网络计算的芯片没有只支持“非深度”神经网络的。关于DNPU可以参考“从ISSCC Deep Learning处理器论文到人脸识别产品”。
Eyeriss。MIT的神经网络项目,针对CNN的进行高能效的计算加速设计。
Thinker。清华微电子所设计的一款可重构多模态神经计算芯片,可以平衡CNN和RNN在计算和带宽之间的资源冲突。
Neural/Neuromorphic Processing Unit。神经/神经形态处理器。这和上面的神经网络处理器还有所不同。而且,一般也不以“处理器”的名字出现,更多的时候被称为“神经形态芯片(Neuromorphic Chip)”或者是“类脑芯片(Brain-Inspired Chip)”。这类AI芯片不是用CNN、DNN等网络形式来做计算,而是以更类似于脑神经组成结构的SNN(Spiking Neural Network)的形式来进行计算。随便列几个,都不是“xPU”的命名方式。
Qualcomm的Zeroth。高通几年前将Zeroth定义为一款NPU,配合以软件,可以方便的实现SNN的计算。但是,NPU似乎不见了踪影,现在只剩下了同名的机器学习引擎Zeroth SDK。
IBM的TrueNorth。IBM2014年公布的TrueNorth。在一颗芯片上集成了4096个并行的core,每个core包含了256个可编程的神经元neurons,一共1百万个神经元。每个神经元有256个突触synapses,共256 Mlillion。TrueNorth使用了三星的28nm的工艺,共5.4 billion个晶体管。
BrainChip的SNAP(Spiking Neuron Adaptive Processor )。已经有了赌场的应用。
GeneralVision的CM1K、NM500 chip,以及NeuroMem IP。这家公司的CM1K芯片有1k个神经元,每个神经元对应256Byte存储。虽然无法和强大的TrueNorth相提并论,但是已有客户应用。并且,提供BrainCard,上面有FPGA,并且可以直接和Arduino以及Raspberry Pi连接。
Knowm 这家start-up在忆阻器(memristor)技术基础上做“processing in memory”的AI芯片研发。不过,与前面提到的Mythic(IPU部分)不同的是,Known做的是类脑芯片。Knowm所用的关键技术是一种称为热力学内存(kT-RAM)的memory,是根据AHaH理论(Anti-Hebbian and Hebbian)发展而来。
Koniku 成立于2014年的start-up,要利用生物神经元来做计算,"Biological neurons on a chip"。主页在倒计时,可能要有重要进展公布,期待。
OPU
Optical-Flow Processing Unit。光流处理器。有需要用专门的芯片来实现光流算法吗?不知道,但是,用ASIC IP来做加速应该是要的。
PPU
Physical Processing Unit。物理处理器。要先解释一下物理运算,就知道物理处理器是做什么的了。物理计算,就是模拟一个物体在真实世界中应该符合的物理定律。具体的说,可以使虚拟世界中的物体运动符合真实世界的物理定律,可以使游戏中的物体行为更加真实,例如布料模拟、毛发模拟、碰撞侦测、流体力学模拟等。开发物理计算引擎的公司有那么几家,使用CPU来完成物理计算,支持多种平台。但是,Ageia应该是唯一一个使用专用芯片来加速物理计算的公司。Ageia于2006年发布了PPU芯片PhysX,还发布了基于PPU的物理加速卡,同时提供SDK给游戏开发者。2008年被NVIDIA收购后,PhysX加速卡产品被逐渐取消,现在物理计算的加速功能由NVIDIA的GPU实现,PhysX SDK被NVIDIA重新打造。
QPU
Quantum Processing Unit。量子处理器。量子计算机也是近几年比较火的研究方向。作者承认在这方面所知甚少。可以关注这家成立于1999年的公司D-Wave System。DWave大概每两年可以将其QPU上的量子位个数翻倍一次。
RPU
Resistive Processing Unit。阻抗处理单元RPU。这是IBM Watson Research Center的研究人员提出的概念,真的是个处理单元,而不是处理器。RPU可以同时实现存储和计算。利用RPU阵列,IBM研究人员可以实现80TOPS/s/W的性能。
Ray-tracing Processing Unit。光线追踪处理器。Ray tracing是计算机图形学中的一种渲染算法,RPU是为加速其中的数据计算而开发的加速器。现在这些计算都是GPU的事情了。
SPU
Streaming Processing Unit。流处理器。流处理器的概念比较早了,是用于处理视频数据流的单元,一开始出现在显卡芯片的结构里。可以说,GPU就是一种流处理器。甚至,还曾经存在过一家名字为“Streaming Processor Inc”的公司,2004年创立,2009年,随着创始人兼董事长被挖去NVIDIA当首席科学家,SPI关闭。
Speech-Recognition Processing Unit。语音识别处理器,SPU或SRPU。这个缩写还没有公司拿来使用。现在的语音识别和语义理解主要是在云端实现的,比如科大讯飞。科大讯飞最近推出了一个翻译机,可以将语音传回云端,做实时翻译,内部硬件没有去专门了解。和语音识别相关的芯片如下。
启英泰伦(chipintelli) 于2015年11月在成都成立。该公司的CI1006是一款集成了神经网络加速硬件来做语音识别的芯片,可实现单芯片本地离线大词汇量识别。

MIT项目。今年年初媒体爆过MIT的一款黑科技芯片,其实就是MIT在ISSCC2017上发表的paper里的芯片,也是可以实现单芯片离线识别上k个单词。可以参考阅读“分析一下MIT的智能语音识别芯片”。
云知声(UniSound)。云知声是一家专攻智能语音识别技术的公司,成立于2012年6月,总部在北京。云知声刚刚获得3亿人民币战略投资,其中一部分将用来研发其稍早公布的AI芯片计划,命名“UniOne”。据官方透漏,UniOne将内置DNN处理单元,兼容多麦克风、多操作系统。并且,芯片将以模组的形式提供给客户,让客户直接拥有一整套云端芯的服务。
Smart Processing Unit。聪明的处理器,听起来很Q。
Space Processing Unit。空间处理器,高大上,有没有。全景摄像,全息成像,这些还都是处理我们的生活空间。当面对广阔的太阳系、银河系这些宇宙空间,是不是需要新的更强大的专用处理器呢?飞向M31仙女座星系,对抗黑暗武士,只靠x86估计是不行的。
TPU
Tensor Processing Unit。Google的张量处理器。2016年AlphaGo打败李世石,2017年AlphaGo打败柯洁,两次人工智能催化事件给芯片行业带来的冲击无疑就是TPU的出现和解密。Google在2017年5月的开发者I/O大会上正式公布了TPU2,又称Cloud TPU。相比于TPU1,TPU2既可以用于training,又可以用于inference。TPU1使用了脉动阵列的流处理结构,具体的细节可以参考如下的文章“Google TPU 揭密”。
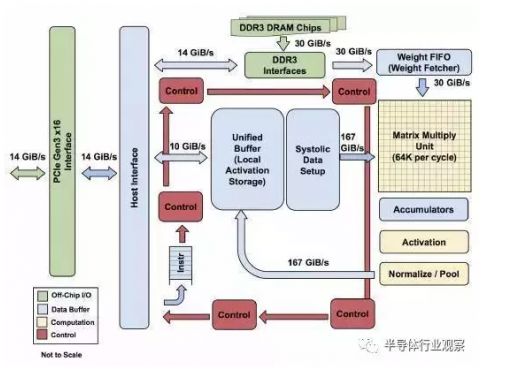
UPU
Universe Processing Unit。宇宙处理器。和Space Processing Unit相比,你更喜欢哪个?
VPU
Vision Processing Unit。视觉处理器VPU也有希望成为通用名词。作为现今最火热的AI应用领域,计算机视觉的发展的确能给用户带来前所未有的体验。为了处理计算机视觉应用中遇到的超大计算量,多家公司正在为此设计专门的VPU。
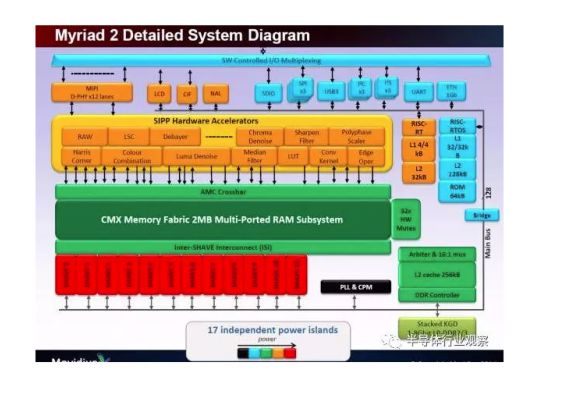
Movidius(已被Intel收购)。Movidius成立于2006年,总部位于硅谷的San Mateo,创始人是两个爱尔兰人,所以在爱尔兰有分部。Movidius早期做的是将旧电影转为3D电影的业务,后期开始研发应用于3D渲染的芯片,并开始应用于计算机视觉应用领域(这说明:1,芯片行业才是高技术含量、高门槛、高价值的行业;2,初创公司要随着发展调整自己的战略)。Movidius开发的Myriad系列VPU专门为计算机视觉进行优化,可以用于 3D 扫描建模、室内导航、360°全景视频等更前沿的计算机视觉用途。例如,2014年,谷歌的Project Tango项目用 Myriad 1帮助打造室内三维地图;2016年,大疆的“精灵4”和“御”都采用了Movidius 的 Myriad 2芯片。采用TSMC 28nm工艺的Myriad2中集成了12个向量处理器SHAVE (Streaming Hybrid Architecture Vector Engine)。按照Movidius的说法,SHAVE是一种混合型流处理器,集成了GPU、 DSP和RISC的优点,支持8/16/32 bit定点和16/32 bit浮点计算,而且硬件上支持稀疏数据结构。此外,Myriad2中有两个RISC核以及video硬件加速器。据称,Myriad2可以同时处理多个视频流。
Inuitive 一家以色列公司,提供3D图像和视觉处理方案,用于AR/VR、无人机等应用场景。Inuitive的下一代视觉处理器NU4000采用28nm工艺,选择使用CEVA的XM4 DSP,并集成了深度学习处理器(自己开发?或者购买IP?)和深度处理引擎等硬件加速器。

DeepVision 一家总部位于Palo Alto的start-up,为嵌入式设备设计和开发低功耗VPU,以支持深度学习、CNN以及传统的视觉算法,同时提供实时处理软件。
Visual Processing Unit。这里是visual,不是vision。ATI一开始称自家显卡上的芯片为VPU,后来见贤思齐,都改叫GPU了。
Video Processing Unit。视频处理器。处理动态视频而不是图像,例如进行实时编解码。
Vector Processing Unit。向量处理器。标量处理器、向量处理器、张量处理器,这是以处理器处理的数据类型进行的划分。现在的CPU已经不再是单纯的标量处理器,很多CPU都集成了向量指令,最典型的就是SIMD。向量处理器在超级计算机和高性能计算中,扮演着重要角色。基于向量处理器研发AI领域的专用芯片,也是很多公司的选项。例如,前面刚提到Movidius的Myriad2中,就包含了12个向量处理器。
Vision DSP。针对AI中的计算机视觉应用,各家DSP公司都发布了DSP的Vision系列IP。简单罗列如下。
CEVA的XM4,最新的XM6 DSP。除了可以连接支持自家的硬件加速器HWA(CEVA Deep Neural Network Hardware Accelerator ),也可以支持第三方开发的HWA。前面提到的Inuitive使用了XM4。可以参考“处理器IP厂商的机器学习方案 - CEVA”。
Tensilica(2013年被Cadence以3.8亿美元收购)的P5、P6,以及最新的C5 DSP。一个最大的特色就是可以用TIE语言来定制指令。前面微软的HPU中使用他家的DSP。可以参考“神经网络DSP核的一桌麻将终于凑齐了”。
Synopsys的EV5x和EV6x系列DSP。可以参考“处理器IP厂商的机器学习方案 - Synopsys”。
Videantis的v-MP4系列。Videantis成立于1997年,总部位于德国汉诺顿。v-MP4虽然能做很多机器视觉的任务,但还是传统DSP增强设计,并没有针对神经网络做特殊设计。
WPU
Wearable Processing Unit。一家印度公司Ineda Systems在2014年大肆宣传了一下他们针对IOT市场推出的WPU概念,获得了高通和三星的注资。Ineda Systems研发的这款“Dhanush WPU”分为四个级别,可适应普通级别到高端级别的可穿戴设备的运算需求,可以让可穿戴设备的电池达到30天的持续续航、减少10x倍的能耗。但是,一切似乎在2015年戛然而止,没有了任何消息。只在主页的最下端有文字显示,Ineda将WPU申请了注册商标。有关WPU的信息只有大概结构,哦,对了,还有一个美国专利。

Wisdom Processing Unit。智慧处理器。这个WPU听起来比较高大上,拿去用,不谢。不过,有点“脑白金”的味道。
XPU
不如干脆就叫XPU,X可以表示未知,一切皆有可能,类似X Man,X File,SpaceX。
就在这篇快收尾的时候,获悉在今年的hotchip会议上,Baidu公开了其FPGA Accelerator的名字,就叫XPU。还没有具体细节可说,拭目以待吧。
YPU
Y?没想法,需要求助各位读者了。
ZPU
Zylin CPU。挪威公司Zylin的CPU的名字。为了在资源有限的FPGA上能拥有一个灵活的微处理器,Zylin开发了ZPU。ZPU是一种stack machine(堆栈结构机器),指令没有操作数,代码量很小,并有GCC工具链支持,被称为“The worlds smallest 32 bit CPU with GCC toolchain”。Zylin在2008年将ZPU在opencores上开源。有组织还将Arduino的开发环境进行了修改给ZPU用。
其他非xPU的AI芯片
寒武纪科技(Cambricon) 中科院背景的寒武纪并没有用xPU的方式命名自家的处理器。媒体的文章既有称之为深度学习处理器DPU的,也有称之为神经网络处理器NPU的。陈氏兄弟的DianNao系列芯片架构连续几年在各大顶级会议上刷了好几篇best paper,为其公司的成立奠定了技术基础。寒武纪Cambricon-X指令集是其一大特色。目前其芯片IP已扩大范围授权集成到手机、安防、可穿戴设备等终端芯片中。据流传,2016年就已拿到一亿元订单。在一些特殊领域,寒武纪的芯片将在国内具有绝对的占有率。最新报道显示,寒武纪又融了1亿美元。
Intel Intel在智能手机芯片市场的失利,让其痛定思痛,一改当年的犹豫,在AI领域的几个应用方向上接连发了狠招。什么狠招呢,就是三个字:买,买,买。在数据中心/云计算方面,167亿美金收购的Altera,4亿美金收购Nervana;在移动端的无人机、安防监控等方面,收购Movidius(未公布收购金额);在ADAS方面,153亿美金收购Mobileye。Movidius在前面VPU部分进行了介绍,这里补充一下Nervana和Mobileye(基于视觉技术做ADAS方案,不是单纯的视觉处理器,所以没写在VPU部分)。
Nervana Nervana成立于2014年,总部在SanDiego,以提供AI全栈软件平台Nervana Cloud为主要业务。和硬件扯上关系的是,Nervana Cloud除了支持CPU、GPU甚至Xeon Phi等后台硬件外,还提供有自家定制的Nervana Engine硬件架构。根据 The Next Platform的报道“Deep Learning Chip Upstart Takes GPUs to Task”,Nervana Engine 使用TSMC 28nm工艺,算力55 TOPS。报道发布不到24小时,就被Intel收购了,全部48位员工并入Intel。Intel以Nervana Engine为核心打造了Crest Family系列芯片。项目代码为“Lake Crest”的芯片是第一代Nervana Engine,“Knights Crest”为第二代。哦,对了,Nervana的CEO在创立Nervana之前,在高通负责一个神经形态计算的研究项目,就是上面提到的Zeroth。


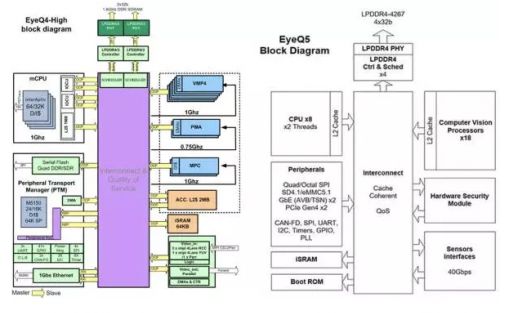
Mobileye 一家基于计算机视觉做ADAS的以色列公司,成立于1999年,总部在耶路撒冷。Mobileye为自家的ADAS系统开发了专用的芯片——EyeQ系列。2015年,Tesla宣布正在使用Mobileye的芯片(EyeQ3)和方案。但是,2016年7月,Tesla和Mobileye宣布将终止合作。随后,Mobile于2017年被Intel以$153亿收入囊中,现在是Intel的子公司。Mobileye的EyeQ4使用了28nm SOI工艺,其中用了4个MIPS的大CPU core做主控和算法调度以及一个MIPS的小CPU core做外设控制,集成了10个向量处理器(称为VMP,Vector Microcode Processor)来做数据运算(有点眼熟,回去看看Movidius部分)。Mobileye的下一代EyeQ5将使用7nm FinFET工艺,集成18个视觉处理器,并且为了达到自动驾驶的level 5增加了硬件安全模块。

比特大陆Bitmain 比特大陆设计的全定制矿机芯片性能优越,让其大赚特赚。在卖矿机芯片之余,比特大陆自己也挖挖矿。总之,芯片设计能力非凡、土豪有钱的比特大陆对标NVIDIA的高端GPU芯片,任性地用16nm的工艺开启了自家的AI芯片之路。芯片测试已有月余,据传功耗60W左右,同步在招揽产品、市场人员。最近的推文爆出了这款AI芯片的名字:“智子(Sophon)”,来自著名的《三体》,可见野心不小,相信不就即将正式发布。
华为&海思 市场期待华为的麒麟970已经很长时间了,内置AI加速器已成公开的秘密,据传用了寒武纪的IP,就等秋季发布会了。还是据传,海思的HI3559中用了自己研发的深度学习加速器。
苹果 苹果正在研发一款AI芯片,内部称为“苹果神经引擎”(Apple Neural Engine)。这个消息大家并不惊讶,大家想知道的就是,这个ANE会在哪款iphone中用上。
高通 高通除了维护其基于Zeroth的软件平台,在硬件上也动作不断。收购NXP的同时,据传高通也一直在和Yann LeCun以及Facebook的AI团队保持合作,共同开发用于实时推理的新型芯片。
还有一些诸如Leapmind、REM这样的start-up,就不一一列举。
结束语
AI芯片,百家争鸣,机遇伴随挑战,今天你争我夺,明天就可能并购。随着这些“xPU”的不断推陈出新,26个字母使用殆尽。但是,换个角度,其实也没关系,索性起个独特的名字。或者,抢先布局“processing in memory”路线,先占个“xxxRAM”或“xxxMem”名字。
最后,安利一下清华汪玉老师的实验室做的网页NN Accelerator | NICS EFC Lab,收集了各种公开的神经网络加速器的数据,并进行了可视化,如图。
