强化学习入门——使用DQN训练CartPole
作为刚入门强化学习的小白,最近几天在写一些基础的代码,使用DQN训练CartPole问题。
DQN是2013年DeepMind提出来的使用Q-learning与神经网络相结合的方法,其实和Q-learning的思想相同,只不过是计算的时候使用神经网络计算Q值。Q-learning简要说一下,就是使用函数逼近的方法,在选择动作时使用epsilon-greedy的方法,在更新Q函数的时候使用Qmax。
这份代码参考了:
https://blog.csdn.net/xinbolai1993/article/details/78280732 博主讲的很详细,感谢~
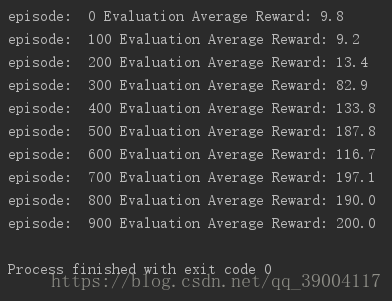
再插一句,初始化参数和调参也是一个技术活,会影响到更新的速度,我一开始b初始化为0.01,参数更新步长为0.001,结果得2000个episode才能训练完(Average Reward=200),但是我把b初始化为0.1,更新步长为0.005,平均600个episode就能训练好。
全部代码如下:
import tensorflow as tf
import numpy as np
from collections import deque
import random
import gym
EPISODE = 10000
class DeepQNetwork:
learning_rate = 0.001
gamma = 0.9
action_list = None
# 执行步数
step_index = 0
# epsilon的范围
initial_epsilon = 0.5
final_epsilon = 0.01
explore = 10000
# 经验回放存储
memory_size = 10000
BATCH = 32
# 神经网络
state_input = None
Q_val = None
y_input = None
optimizer = None
cost = 0
session = tf.Session()
cost_history = []
def __init__(self, env):
self.replay_memory_store = deque()
self.state_dim = env.observation_space.shape[0]
self.action_dim = env.action_space.n
self.action_list = np.identity(self.action_dim)
self.epsilon = self.initial_epsilon # epsilon_greedy-policy
self.create_network()
self.create_training_method()
self.session = tf.InteractiveSession()
self.session.run(tf.global_variables_initializer())
def print_loss(self):
import matplotlib.pyplot as plt
print(len(self.cost_history))
plt.plot(np.arange(len(self.cost_history)), self.cost_history)
plt.ylabel('Cost')
plt.xlabel('step')
plt.show()
def create_network(self):
self.state_input = tf.placeholder(shape=[None, self.state_dim], dtype=tf.float32)
# 第一层
neuro_layer_1 = 20
w1 = tf.Variable(tf.random_normal([self.state_dim, neuro_layer_1]))
b1 = tf.Variable(tf.zeros([neuro_layer_1]) + 0.1)
l1 = tf.nn.relu(tf.matmul(self.state_input, w1) + b1)
# 第二层
w2 = tf.Variable(tf.random_normal([neuro_layer_1, self.action_dim]))
b2 = tf.Variable(tf.zeros([self.action_dim]) + 0.1)
# 输出层
self.Q_val = tf.matmul(l1, w2) + b2
def egreedy_action(self, state):
self.epsilon -= (0.5 - 0.01) / 10000
Q_val_output = self.session.run(self.Q_val, feed_dict={self.state_input: [state]})[0]
if random.random() <= self.epsilon:
return random.randint(0, self.action_dim - 1) # 左闭右闭区间,np.random.randint为左闭右开区间
else:
return np.argmax(Q_val_output)
def max_action(self, state):
Q_val_output = self.session.run(self.Q_val, feed_dict={self.state_input: [state]})[0]
action = np.argmax(Q_val_output)
return action
def create_training_method(self):
self.action_input = tf.placeholder(shape=[None, self.action_dim], dtype=tf.float32)
self.y_input = tf.placeholder(shape=[None], dtype=tf.float32) # ???是[None]吗?
Q_action = tf.reduce_sum(tf.multiply(self.Q_val, self.action_input), reduction_indices=1)
self.loss = tf.reduce_mean(tf.square(self.y_input - Q_action))
self.optimizer = tf.train.AdamOptimizer(0.0005).minimize(self.loss)
def perceive(self, state, action, reward, next_state, done):
cur_action = self.action_list[action:action + 1]
self.replay_memory_store.append((state, cur_action[0], reward, next_state, done))
if len(self.replay_memory_store) > self.memory_size:
self.replay_memory_store.popleft()
if len(self.replay_memory_store) > self.BATCH:
self.train_Q_network()
def train_Q_network(self):
self.step_index += 1
# obtain random mini-batch from replay memory
mini_batch = random.sample(self.replay_memory_store, self.BATCH)
state_batch = [data[0] for data in mini_batch]
action_batch = [data[1] for data in mini_batch]
reward_batch = [data[2] for data in mini_batch]
next_state_batch = [data[3] for data in mini_batch]
# calculate y
y_batch = []
Q_val_batch = self.session.run(self.Q_val, feed_dict={self.state_input: next_state_batch}) # 预估下一个状态的Q值
for i in range(0, self.BATCH):
done = mini_batch[i][4]
if done:
y_batch.append(reward_batch[i])
else:
y_batch.append(reward_batch[i] + self.gamma * np.max(Q_val_batch[i])) # 选择最优的Q函数进行更新
_, self.cost = self.session.run([self.optimizer, self.loss], feed_dict={
self.y_input: y_batch,
self.state_input: state_batch,
self.action_input: action_batch
})
TEST = 10
STEP = 300
def main():
env = gym.make('CartPole-v0')
agent = DeepQNetwork(env)
for i in range(EPISODE):
# if i % 50 == 0:
# env.render()
# print(i)
state = env.reset()
for step in range(STEP):
# env.render()
action = agent.egreedy_action(state)
next_state, reward, done, _ = env.step(action)
agent.perceive(state, action, reward, next_state, done)
state = next_state
if done:
break
if i % 100 == 0:
total_reward = 0
for _ in range(TEST):
state = env.reset()
for _ in range(STEP):
env.render()
action = agent.max_action(state) # direct action for test
state, reward, done, _ = env.step(action)
total_reward += reward
if done:
break
ave_reward = total_reward / TEST
print('episode: ', i, 'Evaluation Average Reward:', ave_reward)
if ave_reward >= 200:
break
# agent.print_loss()
if __name__ == '__main__':
main()
训练结果如下: