《DEEP LEARNING IN VIDEO MULTI-OBJECT TRACKING: ASURVEY》
文章目录
- 1 简介
- 2 MOT:算法、指标和数据集
- 2.1 介绍MOT算法
- 2.2 指标
- 传统指标
- CLEAR MOT指标
- ID scores
- 2.3 基准数据集
- MOTChallenge
- MOT15
- MOT16/17
- MOT19
- KITTI
- 其他数据集
- 3 MOT中的深度学习
- 3.1 检测步骤的深度学习
- 3.1.1 Faster R-CNN
- 3.1.2 SSD
- 3.1.3 其他检测器
- 3.1.4 CNN在检测步骤中的其他用途
- 3.2 深度学习在提取特征和运动预测的应用
- 3.2.1 自编码器:第一个在MOT问题中使用的深度学习方法
- 3.2.2 CNN用于视觉特征提取
- 3.2.3 孪生网络
- 3.2.4 更加复杂的视觉特征提取方法
- 3.2.5 CNN用于运动预测:相关滤波
- 3.2.6 其他方法
- 3.3 深度学习用于相似度计算
- 3.3.1 RNN和LSTM
- 3.3.2 Siamese LSTM
- 3.3.3 Bidirectional LSTM
- 3.3.4 在多假设跟踪框架中使用LSTM
- 3.3.5 其他循环网络
- 3.3.6 CNN用于相似度计算
- 3.3.7 Siamese CNNs
- 3.4 深度学习用于关联/跟踪步骤
- 3.4.1 循环神经网络
- 3.4.2 深度多层感知机
- 3.4.3 深度强化学习agents
- 3.5 深度学习在MOT问题中的其他应用
- 4 分析和比较
- 4.1 环境和组织
- 4.2 讨论结果
- 一般观察结果
- 在MOT四个步骤中的最好方法
- 其他顶级表现算法的趋势
- 5 结论和未来的方向
- 参考文献
一篇基于深度学习的视频多目标跟踪综述
1 简介
回顾往期多目标跟踪的综述文章:
- [11]提出了第一个全面的多目标跟踪综述,尤其是行人跟踪。他们给出了MOT问题的一个统一范式,并描述了MOT系统中的关键步骤使用的主要技术。他们提出了将深度学习算法作为未来的研究方向之一,因为当时很少的算法有用到深度学习
- [12]提出了一个行人多目标跟踪的综述,但是他们关注的是RGB-D图像(深度图像),而我们所关注的是2D的RGB图像,没有额外附加输入。此外,这篇综述并没有涉及基于深度学习的算法。
- [13]提出了一个单/多传感器跟踪任务的范式——多维分配问题(MDAP)。他们同样提到了少数使用深度学习来解决跟踪问题的算法,但这不是他们的重点,他们也没有对这些算法进行比较实验。
- [14]对MOT15和MOT16的多目标跟踪算法进行了分析,提供了关于MOT挑战结果的的趋势和统计数据的摘要。他们发现,2015年之后,MOT算法已经从试图为关联问题找到更好的优化算法转变为专注于改进相似度模型,并且他们预测更多的方法将通过深度学习来解决这个问题。然而,这篇综述没有重点讨论深入学习,也没有涵盖近几年提出的MOT算法。
在本文中,基于上述局限,我们的综述的贡献主要有:
- 我们提出了第一个使用深度学习进行多目标跟踪的综述,侧重于从单个摄像头视频中提取2D图像数据。包括那些近期发布的没有被过去综述所提到的算法。在MOT中使用深度学习方法实际上是最近才出现的,在过去的三年中已经发布了许多方法。
- 我们确定了MOT算法中的四个常见步骤,并描述了这些步骤中使用的不同深度学习模型和方法,包括使用它们算法的环境。每个被分析的工作中所使用的技术,连同可用源代码的链接,也被汇总到一个表中,以供将来的研究快速参考。
- 我们收集了最常用的MOT数据集的实验结果,对它们进行了数值比较,并确定了最佳算法的主要趋势和未来可能的研究方向。
调查按照这种方式开展。在第2节中,我们首先描述了MOT算法的一般结构以及最常用的度量和数据集。第3节探讨了MOT算法四个步骤中的各种基于深度学习的模型和算法。第4节对所提出的算法进行了数值比较,确定了当前方法的常见趋势和模式,以及一些局限性和未来可能的研究方向。最后,第5节对前几节的研究结果给出了一些最后的评论。
2 MOT:算法、指标和数据集
在本节中,对有关MOT问题进行了一般描述。第2.1节对MOT算法的主要特点和常用步骤进行了定义和描述,第2.2节讨论了通常用于评估模型性能的指标,第2.3节介绍了几个基准数据集。
2.1 介绍MOT算法
MOT算法中使用的标准方法是基于检测的跟踪:从视频帧中提取一组detections(识别图像中目标的边界框),用于指导跟踪过程,通常通过将它们关联在一起以对相同的目标分配同一个ID。因此,许多MOT算法将任务定义为分配问题。现代检测框架[4,17,18,5,6]确保了良好的检测质量,并且大多数MOT方法(我们也将看到的一些例外)都致力于改善关联性;实际上,许多MOT数据集提供了一套标准的检测集,可供算法使用(即因此跳过检测阶段),以便专门比较它们在关联算法质量上的性能,因为检测器性能会严重影响跟踪结果。
MOT算法也可以分为批处理(offline)和在线(online)方法。当offline方法试图确定某一帧中的对象ID时,允许其跟踪算法使用未来信息(即来自未来帧的信息),他们经常利用全局信息,从而提高跟踪质量。相反,online跟踪算法只能使用现在和过去的信息来预测当前帧。在某些情况下,这是一项要求,如自动驾驶和机器人导航。与offline方法相比,online方法的性能往往更差,因为它们无法使用将来的信息修复过去的错误。需要注意的是,虽然需要以online方式运行实时算法,但并非所有在线方法都必须实时运行;事实上,通常情况下,除了极少数例外,online算法在实时环境中的使用速度仍然太慢,特别是在以下情况下:尤其是在开发深度学习算法时,这种算法通常需要大量的计算。
尽管文献中提出了各种各样的方法,但绝大多数MOT算法都共享以下部分或全部步骤(如图2所示):
- 检测阶段:一个对象检测算法分析每个输入帧,使用边界框(在MOT上下文中也称为“detections”)来识别属于目标类的对象。
- 特征提取/运动预测阶段:一个或多个特征提取算法分析检测和/或轨迹,以提取外观、运动和/或交互特征。或者,运动预测器预测每个被跟踪目标的下一个位置;
- 计算相似度阶段:特征和运动预测用于计算detections和/或轨迹对之间的相似性/距离分数;
- 关联阶段:相似度/距离度量用于将属于同一目标的detections和轨迹关联起来,方法是将相同的ID分配给标识相同目标的detections。
 图 2。MOT算法的通常工作流程:(1)给定视频的原始帧,(2)运行目标检测器以获取对象的边界框。(3)然后,对于每个被检测到的物体,计算出不同的特征,通常是视觉和运动特征。(4)然后,关联计算步骤计算属于同一目标的两个对象的概率,(5)最后关联步骤为每个对象分配一个数字ID。
图 2。MOT算法的通常工作流程:(1)给定视频的原始帧,(2)运行目标检测器以获取对象的边界框。(3)然后,对于每个被检测到的物体,计算出不同的特征,通常是视觉和运动特征。(4)然后,关联计算步骤计算属于同一目标的两个对象的概率,(5)最后关联步骤为每个对象分配一个数字ID。
虽然这些阶段可以按此处显示的顺序依次执行(对于online方法,通常每帧执行一次,对于offline方法,整个个视频执行一次),有许多算法将这些步骤合并在一起,或者将它们相互交织,或者甚至使用不同的技术多次执行它们(例如,在分两个阶段工作的算法中)。此外,有些方法不直接将detections关联在一起,而是使用它们来优化轨迹预测,并管理新轨迹的初始化和终止;然而,即使在这种情况下,我们仍可以确定许多已呈现的步骤,正如我们将看到的那样。
2.2 指标
为了提供一个可以公平测试和比较算法的通用实验方案,事实上已经建立了一组度量标准,并且几乎在每项工作中都使用它们。最相关的是由Wu和Nevatia[19]、所谓的CLEAR MOT指标[20]和最近的ID指标[21]定义的指标。这些指标旨在反映测试模型的整体性能,并指出每种指标可能存在的缺点。因此,这些指标定义如下:
传统指标
由Wu和Nevatia[19]定义的这些指标突出了MOT算法可以产生的不同类型的错误。为了显示这些问题,需要计算以下值:
- 大部分跟踪(MT):至少80%帧中正确命中真实轨迹。
- 碎片(Fragm):覆盖真实轨迹最多80%的轨迹假设。也就是说一个真实的轨迹可以被一个以上的碎片覆盖。
- 大部分丢失(ML):少于20%的帧中正确命中真实轨迹。
- 虚假轨迹:预测的轨迹和真实的目标不匹配
- 身份转换:目标被正确跟踪但目标的关联ID被错误更改的次数。
CLEAR MOT指标
CLEAR MOT提出了MOTA(多目标跟踪准度)和MOTP(多目标跟踪精度)。它们是组成它们的其他简单指标的汇总。我们将首先解释简单的度量标准,并构建复杂的度量标准。关于如何将真实轨迹(Ground truth)与跟踪器假设相匹配的详细描述,可在[20]中找到。我们专注于单个相机进行二维跟踪时,最常用的确定对象和预测的指标是边界框的IOU,因为它是MOT15数据集[15]演示文件中确定的指标。具体来说,基本真值和假设之间的映射建立如下:如果真实目标 o i o_i oi和假设目标 h j h_{j} hj在第 t − 1 t-1 t−1帧成功匹配,且在第 t t t帧的IOU超过0.5,那么则认为 o i o_{i} oi 和 h j h_{j} hj在当前帧匹配(即使存在另一个假设目标 h k h_k hk使得 IoU ( o i , h j ) < IoU ( o i , h k ) \operatorname{IoU}\left(o_{i}, h_{j}\right)<\operatorname{IoU}\left(o_{i}, h_{k}\right) IoU(oi,hj)<IoU(oi,hk),出于连续性考虑仍然选择前者)。在之前的帧匹配完成后,剩余的对象将尝试与剩余的假设匹配,仍然使用IOU=0.5的阈值。其中,在假设中不存在而在事实上存在目标称之为漏检(FN),在假设中存在而在事实上不存在的目标称之为误检(FP)。每次一个真实跟踪轨迹被中断,随后恢复被算作一个碎片,而每次跟踪期间被跟踪目标与真实值相比ID被错误地更改时,被算作一次身份转换。然后,计算出的简单指标如下:
- FP:整个视频中的误检数
- FN:整个视频中的漏检数
- Fragm:总的碎片数
- IDSW:总的身份交换次数
MOTA得分的定义如下:
M O T A = 1 − ( F N + F P + I D S W ) G T ∈ ( − ∞ , 1 ] M O T A=1-\frac{(F N+F P+I D S W)}{G T} \quad \in(-\infty, 1] MOTA=1−GT(FN+FP+IDSW)∈(−∞,1]
其中 G T GT GT是真实的边界框的数量
MOTP的计算方法如下:
M O T P = ∑ t , i d t , i ∑ t c t M O T P=\frac{\sum_{t, i} d_{t, i}}{\sum_{t} c_{t}} MOTP=∑tct∑t,idt,i
其中 c t c_{t} ct是第 t t t帧匹配的数量, d t , i d_{t, i} dt,i是真实目标和假设目标 i i i的覆盖率。这一指标更多关注的是detections的质量。
ID scores
MOTA评分的主要问题是,它考虑了追踪器做出错误决定的次数,如ID切换,但在某些情况下(如机场安保),人们可能更感兴趣的是一个能让跟踪对象被最长时间跟踪到的追踪器。正因为如此,在[21]中定义了一个新的可选指标,它补充CLEAR MOT指标给出的信息。该映射不是逐帧匹配地面真值和检测结果,而是全局执行的,被分配给真实轨迹的假设轨迹是一个拥有最多正确匹配的数量的轨迹。为了解决这一问题,构造了二分图,并以该问题的最小代价解为问题解。
对于二分图,其节点集合的定义如下:第一个节点集合 V T V_{T} VT包含每条真实轨迹的常规节点和每条假设轨迹的误检节点,第二个节点集 V C V_{C} VC包含每条假设轨迹的的常规节点和每条真实轨迹的漏检节点。关联完成之后,就会有四种可能的配对情况:
V T V_{T} VT中的常规节点和 V C V_{C} VC中的常规节点关联,IDTP(ID True Positive),该数值代表了整个视频中正确关联的数量
V T V_{T} VT中的误检节点和 V C V_{C} VC中的常规节点关联,IDFP(ID False Positive)
V T V_{T} VT中的常规节点和 V C V_{C} VC中的漏检节点关联,IDFN(ID False Negative)
V T V_{T} VT中的误检节点和 V C V_{C} VC中的漏检节点关联,IDTN(ID True Negative)
据此,我们可以计算出另外三个指标:
- 识别精度: I D P = I D T P I D T P + I D F P I D P=\frac{I D T P}{I D T P+I D F P} IDP=IDTP+IDFPIDTP
- 识别召回率: I D R = I D T P I D T P + I D F N I D R=\frac{I D T P}{I D T P+I D F N} IDR=IDTP+IDFNIDTP
- 识别F1: I D F I = 2 1 1 D P + 1 I D R = 2 I D T P 2 I D T P + I D F P + I D F N I D F I=\frac{2}{\frac{1}{1 D P}+\frac{1}{I D R}}=\frac{2 I D T P}{2 I D T P+I D F P+I D F N} IDFI=1DP1+IDR12=2IDTP+IDFP+IDFN2IDTP
通常,几乎每项工作中报告的指标都是CLEAR MOT指标,跟踪轨迹(MT),丢失轨迹(ML)和IDF1,因为这些指标是MOTCHAllenge排行榜中显示的指标(有关详细信息,请参见第2.3节)。
2.3 基准数据集
在本节中,我们将描述最重要的数据集,主要关注MotChallenge数据集,最后描述Kitti和其他不常用的Mot数据集。
MOTChallenge
MotChallenge是多目标跟踪最常用的基准。它提供了一些大型的行人跟踪数据集,这些数据集目前是公开的。对于每个数据集,提供了分别训练的Ground Truth,以及分别训练和分别测试的detections。MotChallenge数据集经常提供检测(通常称为公共detections,而不是由算法作者使用自己的检测器获取的私有detections)的原因是检测质量对跟踪的最终性能有很大影响。但算法的检测部分通常独立于跟踪部分,通常使用现有的模型;提供每个模型都可以使用的公共detections,使得跟踪算法的比较更容易。对测试数据集的算法的评估是通过将结果提交给测试服务器来完成的。MotChallenge网站包含每个数据集的排行榜,在单独的页面中显示使用公开提供detections和使用私人detections的模型。MOTA是MOT挑战的主要评估分数,但显示了许多其他指标,包括第2.2节中显示的所有指标。正如我们将看到的,由于大多数使用深度学习的MOT算法都集中在行人身上,因此MOTCHAllenge数据集是最广泛使用的,因为它们是目前最全面的,为训练深度模型提供了更多的数据。
MOT15
第一个MOTchallenge数据集是2D MOT 2015[15](通常称为MOT15)。它包含一系列22个视频(11个用于训练,11个用于测试),它从旧的数据集中收集,具有各种特征(固定和移动摄像头、不同的环境和照明条件等),以便模型需要更好地概括,以获得良好的结果。它共有11283帧,分辨率各不相同,1221个不同ID,101345个边界框。所提供的检测是使用ACF检测器获得的[24]。
MOT16/17
数据集的新版本于2016年发布,称为MOT16[16]。视频也更具挑战性,因为它们具有更高的行人密度。该设备共包含14个视频(7个用于培训,7个用于测试),通过使用DPM v5[25,26]获得公共检测结果,与其他模型相比,他们发现在数据集上检测行人时获得了更好的性能。这次数据集包括11235帧,共1342个标识和292733个框。MOT17数据集4包含与MOT16相同的视频,但具有更精确的Ground Truth,并且每个视频有三组检测:一组来自更快的R-CNN[4],一组来自DPM,一组来自SDP[27]。然后,追踪器必须证明是多功能和足够强大的,以使用不同质量的detections获得良好的性能。
MOT19
最近才发布的一个新版本的CVPR 2019跟踪挑战数据集,其中包含8个视频(4个用于培训,4个用于测试),行人密度极高,在最拥挤的视频中,平均每帧可达245名行人。数据集包含13410帧,共6869条轨迹和2259143个边界框,比以前的数据集多得多。虽然仅在有限的时间内允许提交此数据集,但此数据将作为2019年下半年MOT19发布的基础[28]。
KITTI
虽然MotChallenge数据集中于行人跟踪,但Kitti跟踪基准[29,30]允许跟踪人和车辆。该数据集是通过在一个城市里驾驶一辆汽车收集的,并于2012年发布。它由21个训练视频和29个测试视频组成,共约19000帧(32分钟)。它包括使用DPM和Regionlets[31]探测器获得的检测,以及立体声和激光信息;但是,正如本次调查中所解释的,我们只关注使用二维图像的模型。使用CLEAR MOT指标、MT、ML、IDSW和Framg来评估这些方法。可以只为行人或汽车提交结果,并且两个级别的两个不同的排行榜保持不变。
其他数据集
除了前面描述的数据集之外,还有一些较旧的数据集,现在使用频率较低。在这些数据中,我们可以找到UA-DETRAC跟踪基准[32],该基准关注的是交通摄像头跟踪的车辆,以及TUD[33]和PETS2009[34]数据集,这两个数据集都关于行人的。他们的许多视频现在都是MotChallenge数据集的一部分。
3 MOT中的深度学习
由于本文的重点是在MOT任务中深度学习的使用,因此我们将本节分为五个小节。前四小节中的每一小节都对四个MOT阶段中的每一个阶段如何利用深度学习进行了回顾。第3.4小节除了介绍在关联过程中使用深度学习之外,还将包括在整个跟踪管理过程中使用深度学习(例如,跟踪的初始化/终止),因为它与关联步骤严格相连。第3.5小节将最终描述MOT中不符合四步方案的深度学习的用途。
我们在附录A中包含了一个汇总表,其中显示了本次调查中每篇论文的四个步骤中使用的主要技术。
3.1 检测步骤的深度学习
虽然许多工作已被用作其算法的输入,但数据集提供了由各种检测器生成的检测(例如,MOT15[15]的ACF[24]或MOT16[16]的DPM[25]),但也有集成自定义检测步骤的算法,这通常有助于通过提高检测质量来提高整体跟踪性能。
正如我们将看到的,使用自定义检测的大多数算法使用更快的R-CNN及其变体(第3.1.1节)或SSD(第3.1.2节),但使用不同模型的方法也存在(第3.1.3节)。尽管绝大多数算法使用深度学习模型提取矩形边界框,但一些工作中在检测步骤中使用了不同的深度网络:这些是第3.1.4节的重点。
3.1.1 Faster R-CNN
3.1.2 SSD
3.1.3 其他检测器
3.1.4 CNN在检测步骤中的其他用途
3.2 深度学习在提取特征和运动预测的应用
特征提取阶段是应用深度学习模型的首选阶段,因为它们具有很强的表示能力,能够很好地提取有意义的高级特征。该领域最典型的方法是使用CNN提取视觉特征,如第3.2.2节所述。与经典的CNN模型相反,另一个想法是训练他们作为孪生CNN,使用对比损失函数,以便找到最能区分不同目标的一组特征,这些方法在第3.2.3节中进行了解释。此外,一些作者探讨了CNN在基于相关滤波器的算法中预测物体运动的能力,这些在第3.2.5节中进行了解释。最后,还采用了其他类型的深度学习模型,通常包括在更复杂的系统中,将深度特征与经典特征相结合。第3.2.4节(特别是针对视觉功能)和第3.2.6节对其进行了解释(针对不适合其他类别的方法)。
3.2.1 自编码器:第一个在MOT问题中使用的深度学习方法
据我们所知,Wang等人提出了在MOT中使用深度学习的第一种方法[81],他们提出了一个自动编码器网络,该网络由两层组成,用于优化从自然场景中提取的视觉特征[82]。提取步骤完成后,利用支持向量机进行关联计算,将关联任务定义为最小生成树问题。结果表明,特征细化大大提高了模型的性能。然而,测试算法的数据集并不是常用的,结果也很难与其他方法相比较。
3.2.2 CNN用于视觉特征提取
最广泛使用的特征提取方法是卷积神经网络。这些模型的首次应用可以在[83]中找到。在这里,Kim等人将视觉特征与经典的多假设跟踪算法合并,使用一个经过预训练的CNN,从detections中提取4096个视觉特征,然后使用PCA将其减少到256个。.修改后的MOT15成绩提高了3%以上。.Yu 等人[38]使用了inception[2]的修改版本,对定制重识别数据集进行了预训练,该数据集是通过结合经典的个人识别数据集(PRW[84],market-1501[85],VIPeR[86],CUHK03[87])构建的。将视觉特征与空间特征相结合,利用卡尔曼滤波,并计算出亲和矩阵。
使用CNN进行特征提取的其他例子可以在[88]中找到,在[89]中一个自定义CNN被用于提取多假设跟踪框架中的外观特征,其追踪器使用了基于预训练区域的CNN[90];在[91]中,CNN从鱼头中提取视觉特征,然后结合卡尔曼滤波器进行运动预测。
第3.1.1节中介绍的SORT算法[35]后来进行了改进,具有深层次的特性,这个新版本被称为Deepsort[41]。这个模型包含了一个自定义残差CNN提取的视觉信息[92],CNN提供了一个输出128维度特征的归一化向量,并将这些向量之间的余弦距离添加到SORT中使用的相似度分数中。实验表明,这种改进克服了SORT算法的主要缺点,即ID Switch数量较多。
Mahmoudi等人[42]还结合CNN提取的视觉特征以及动态和位置特征,通过匈牙利算法解决了关联问题。在[93]中,一个在imagenet上预训练的resnet-50[3]被用作视觉特征提取程序。关于CNN如何用来区分行人的广泛解释可以在[94]中找到,在他们的模型中,Bae等人将CNN的输出与形状和运动模型相结合,计算出每对检测的聚集亲和力得分,然后用匈牙利算法求解关联问题。同样,Ullah等人[95]应用了一个现成的inception版本[2]进行特征提取。Fang等人[96]选择inception的隐藏层输出作为视觉特征,一个隐藏的卷积层的一个开始CNN的输出[97]。Fu等人[98]使用Deeport特征抽取器,并使用判别相关滤波器测量特征的相关性,然后,将匹配分数与时空关系分数相结合,并将最终分数用作高斯混合概率假设密度滤波器[99]中的概率得分。[100]中的作者在ILSVRC CLS_LOC[101]数据集上使用了一个微调的Inception,用于行人识别。在[70]中,作者重用了CNN探测器提取的视觉特征,并使用Reverse Nearest Neighbor技术进行关联[102]。Sheng等人[103]使用Inception的卷积部分提取外观特征,使用它们之间的余弦距离计算成对detection之间的相似度分数,并将该信息与运动预测合并,以计算作为图问题中边成本的总体相似度。Chen等人[104]利用resnet的卷积部分构建自定义模型,在卷积顶部堆叠一个lstm单元,以便同时计算相似性得分和边界框回归。
在[53]中,模型学会了区分快速移动的细胞和缓慢移动的细胞。在计算分类后,由于慢细胞几乎静止不动,因此它们只使用运动特征关联,而快速细胞则同时使用由基于VGG-16的Faster R-CNN提取的运动特征和视觉特征关联,特别针对细胞分类任务进行了微调。此外,该模型还包括一个跟踪优化步骤,通过结合可能被错误中断的轨迹来减少FN和FP。
Ran等人[52]提出了一种结合经典CNN的视觉特征提取和alphapose CNN的姿势估计,然后将这两个网络的输出与tracklet信息历史一起输入LSTM模型,以计算相似性,如第3.3.1节所述。
CNN在特征提取中的有趣应用可以在[51]中找到。作者使用了一个名为DeepCut[105]的姿势检测器,这是对Faster R-CNN的改进;它的输出包括预测14个身体部位存在的分数图。这些照片与被探测到的行人的剪短图像结合在一起,并被送入CNN。第3.3.6节对算法进行了更详细的解释。
3.2.3 孪生网络
 图4:孪生网络架构示例。对于特征提取,网络被训练为孪生网络,但在推理时,输出概率被丢弃,最后一个完全连接层被用作单个候选对象的特征向量。当网络用于关联计算时,整个结构在推理过程中保留。
图4:孪生网络架构示例。对于特征提取,网络被训练为孪生网络,但在推理时,输出概率被丢弃,最后一个完全连接层被用作单个候选对象的特征向量。当网络用于关联计算时,整个结构在推理过程中保留。
另一个反复出现的想法是用损失函数训练CNN,该函数将来自不同图像的信息结合起来,以便学习最能区分不同对象的一组特征。这些网络通常称为孪生网络(结构如图4所示)。 Kim等人[106]提出了一个孪生网络[107],该网络使用对比损失函数进行训练。该网络采用两幅图像,即IOU得分和面积比作为输入,并产生对比损失作为输出。训练网络后,去除了计算对比度损失的层,最后一层作为输入图像的特征向量,通过结合特征向量之间的欧式距离、IOU得分和边界框之间的面积比,计算相似性得分,关联步骤使用自定义贪婪算法求解。Wang等人[108]还提出了一个孪生网络,它取了两个图像块,并计算了它们之间的相似性得分,通过比较网络提取的两幅图像的视觉特征,包括时间约束信息,计算出测试时的得分,作为相似度得分的距离是一个带有权重矩阵的马氏距离,也由模型学习。
Zhang等人[109]提出了一个称为symtriplet loss的损失函数。根据他们的解释,在训练阶段,使用三个具有共享权重的CNN,损失函数将从属于同一对象(正对)的两个图像和从不同对象(负对)的一个图像中提取的信息结合起来。当正对特征向量之间的距离较小时,symtriplet loss减小,当负对特征接近时,symtriplet loss增大。优化该函数会使同一对象的特征向量之间距离更近,同时不同的对象之间的特征向量之间的距离更远。测试跟踪算法的数据集由电视剧和YouTube音乐视频的片段组成。由于视频包含不同的镜头,所以问题分为两个阶段。首先,对同一张照片中的帧进行数据关联。在这种情况下,相似度得分是特征向量与detection、时间和运动信息之间的欧式距离的组合。然后,通过对外观特征使用层次聚集聚类算法,将跨境头的轨迹碎片碎片岁皮啊岁皮碎片岁素是连接起来。
Leal等人[110]提出了一个孪生网络,它接收两个叠加图像作为输入,并输出两个图像属于同一个人的概率。他们用这个输出训练网络,使其学会最有代表性的特征来区分目标。然后,去除输出层,并将最后一个隐藏层提取的特征与上下文信息一起作为 Gradient Boosting模型的输入,以获得detections之间的相似度分数。然后,使用线性规划[111]求解关联步骤。
Son等人[112]提出了一种新的CNN架构,称为Quad CNN。这个模型接收四个图像块作为输入,其中前三个补丁来自同一个目标,但按时间顺序递增,最后一个补丁来自另一个目标。使用自定义丢失对网络进行训练,结合检测之间的时间距离信息、提取的视觉特征和边界框位置。在测试阶段,网络进行了两次检测,并利用所学的嵌入技术预测了两个detections属于同一个人的概率。
在[55]中,提出了一个基于Mask R-CNN[17]的孪生网络。在Mask R-CNN为每次检测制作了mask后,将三个例子输入浅孪生网络,两个来自同一对象(正对)和一个来自另一对象(负对),再次使用triplet loss进行训练。在训练阶段之后,移除输出层,从最后一个隐藏层中提取128维度矢量,然后使用余弦距离计算外观相似度。这种相似性进一步与运动一致性相结合,运动一致性包括基于物体预测位置的分数(假设为线性运动)和空间位置(更复杂的运动模型)。然后通过计算相似性的三维张量的幂次迭代来解决关联问题。
Maksai等人[113]直接使用了Reid Triplet CNN在[114]中提出的128维特征向量,并将其与其他基于外观的特征相结合(作为无外观版本算法的替代方案)。这些特征由双向LSTM进一步处理。在[115]中,采用了类似的方法,即所谓的空间注意力网络(SAN),SAN是一个孪生网络,它使用了一个预训练的Resnet-50作为基础模型。该网络被截断,因此只使用卷积层。然后,从模型的最后一个卷积层中提取一个空间注意力图:它表示边界框中不同部分的重要性的度量,以便从提取的特征中排除背景和其他目标。这些特征实际上被这张图加权,充当了一个mask。然后将两个detections中的mask特征合并到一个完全连接的层中,计算它们之间的相似性。在训练过程中,网络还被设置为输出分类分数,因为作者观察到,联合优化分类和相似性计算任务可以使后者获得更好的性能。相似性信息被进一步输入到双向LSTM中,如前一个示例所示。这两个问题将在第3.3节中进一步讨论。Ma等人[116]还训练了孪生网络,以便从他们模型中被跟踪的行人中提取视觉特征,这在第3.4.1节中有详细说明。
在[117]中,周等人提出了一个视觉位移CNN,它学会了根据物体的先前位置预测物体的下一个位置,以及物体对场景中其他物体的影响。CNN随后被用来预测下一帧中物体的位置,通过输入它们过去的轨迹。网络还能够从预测位置和实际检测中提取视觉信息,以便计算相似度得分,如第3.3.6节所述。
Chen等人[118]提出了一种两步算法,该算法利用三重损失训练的Inception进行特征提取。在第一步中,该模型使用一个R-FCN,利用现有tracklets中的信息来预测可能的detections候选对象。然后,将这些detections与实际detections相结合,执行NMS,然后利用定制的Inception模型,从检测中提取视觉特征,用层次关联算法解决关联问题。当他们的论文发表时,该算法在MOT16数据集中的online方法中排名第一。
Lee等人[119]最近探索了一种有趣的方法,将金字塔和孪生网络结合在一起。他们的模型称为特征金字塔孪生网络,采用了主干网络(他们使用SqueezeNet[120]和GoogLeNet[2]研究了性能,但主干网络可以改变),该模型使用相同的参数从两个不同的图像中提取视觉特征。然后,从网络中提取一些隐藏的特征图,并将其赋给特征金字塔孪生网络。然后,该网络采用上采样和合并策略为金字塔的每个阶段创建一个特征向量。较深的层与较浅的层合并,以丰富较简单的特征和较复杂的特征。随后,按照第3.3.7节的说明,进行相似度评分计算。
3.2.4 更加复杂的视觉特征提取方法
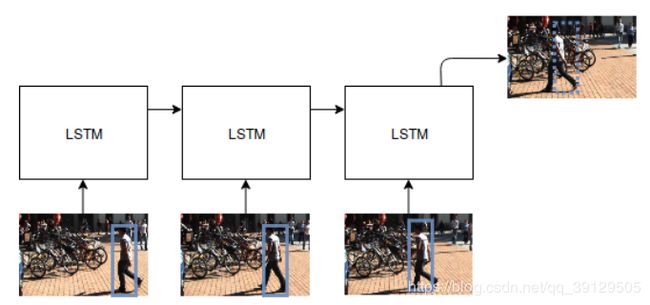 图5:LSTM用于运动预测的典型用法。将一组边界框送入网络,生成的输出是下一帧中的预测边界框。
图5:LSTM用于运动预测的典型用法。将一组边界框送入网络,生成的输出是下一帧中的预测边界框。
还有更复杂的方法。Lu等人[59]将SSD在检测步骤中预测的类作为特征,并将其与每个detections的ROI池提取的图像描述符结合起来,然后将提取的特征作为LSTM网络的输入,学习计算detections的关联特征。这些特征使用它们之间的余弦距离进行相似度计算。
在[121]中,使用较浅的Inception来学习跟踪对象的特征字典。为了学习字典,算法在视频的前100帧随机选择对象。该模型提取了网络前七层的特征图。然后利用正交匹配追踪(OPM)[122]对从对象中提取的特征进行降维,并将学习到的表示作为字典。在测试阶段,计算了场景中每个被测对象的OPM表示,并与字典进行了比较,以构建成本矩阵,结合卡尔曼滤波器提取的视觉和运动信息,最后,使用匈牙利算法进行关联。
LSTM有时用于运动预测,以便从数据中学习更复杂的非线性运动模型。在图5中,显示了使用LSTM进行运动预测的典型方案。Sadeghian等人[123]提出了一个使用三个不同的RNN来计算各种类型特征的模型,而不仅仅是运动特征的模型,并给出了一个使用循环网络的例子。第一个RNN用于提取外观特征。这个RNN的输入是由一个VGG[1]提取的一个视觉特征向量,经过专门的预训练用于行人的重识别。第二个RNN是训练用来预测每个被跟踪物体运动模型的LSTM。在这种情况下,LSTM的输出是每个对象的速度矢量。最后一个RNN被训练来学习场景中不同对象之间的交互,因为一些对象的位置可能会受到周围项目行为的影响。然后,相似性计算由另一个LSTM执行,将其他RNN的信息作为输入。
在[124]中,提出了堆叠CNN的模型。模型的第一部分包括一个经过预训练的共享CNN,它提取了场景中每个对象的共同特征。然后,应用一个ROI池,提取每个候选对象的ROI特征。之后,对每个被跟踪的候选人,一个新的CNN被实例化并在线训练。这些CNN提取了候选对象的可见性图和空间注意力图。最后,在提取出细化特征后,计算出每个新对象属于已跟踪对象的概率,并利用贪婪算法进行关联步骤。
Sharma等人[67]设计了一组成本函数来计算车辆检测之间的相似性。假设摄像头处于移动状态,这些成本将CNN提取的外观特征与3D形状和位置特征相结合。如果将前一帧上边界框的估计3D投影与新帧上的2D边界框进行比较,则是一个3D-2D成本,如果前一边界框的3D投影与当前边界框的三维投影重叠,则是一个3D-3D成本,对提取的视觉特征的欧几里得距离进行了计算,并对形状和姿态成本进行了粗略的计算和比较。请注意,虽然已推断出3D投影,但输入的仍然是二维图像。在计算了每一个成本之后,两个后续帧中检测之间的最终成对成本是前一个成本的线性组合。最后用匈牙利算法解决了关联问题。
Kim等人[66]利用Yolov2 CNN目标检测器提取的信息构建一个随机蕨分类器[125]。该算法分两步工作。在第一步,训练一个所谓的teacher-RF,以区分行人和非行人。对teacher-RF训练后,对每个被跟踪对象建立随机蕨分类器。这些分类器被称为student-RF,它们比teacher-RF小,专门用来区分被跟踪物体和场景中其他物体。为了降低整个模型的计算复杂度,对每一个对象都进行了一个小的随机蕨分类器的决策,使其能够实时工作。
在[126]中,通过使用隐马尔可夫模型[127]首先估计对象在随后帧中的位置,减少了模型必须计算的关联计算的数量。然后,使用预先训练的CNN执行特征提取。在提取视觉特征后,只进行可行对之间的相似度计算,即马尔可夫预测的距离足够近的detections被视为同一对象。通过视觉特征之间的交互信息函数得到相似度得分。当计算相似度得分时,采用动态规划算法来关联检测。
3.2.5 CNN用于运动预测:相关滤波
Wang等人[128]研究了相关滤波器[129]的使用,其输出是跟踪对象的响应图,即对下一帧中物体新位置的估计。这种相似度进一步与光流相似度结合,使用Lucas Kanade算法[130]计算,用Kalman滤波器计算的运动相似度和尺度相似度,用涉及边界框高度和宽度的比率表示。两次检测之间的相似度计算为之前得分的线性组合。还有一个错误detections移除的步骤,根据前面步骤中计算的响应图,使用SVM分类器以及缺失检测处理器。如果错误地丢失了一个对象,然后重新识别,那么该步骤可以修复错误并重新关联断开的tracklet。
在[61]中,相关滤波器也被用来预测对象在后一帧中的位置。该滤波器接收CNN提取的外观特征作为输入(之前使用PCA进行了简化)并生成了下一帧中目标预测位置的响应图作为输出。预测位置随后被用来计算相似度评分,结合预测和detections之间的IOU,以及反应图的APCE评分(Average Peak-to-Correlation Energ[63])。在构建了成本矩阵后,计算出帧间每对detections的得分,并用匈牙利算法求解了分配问题。
3.2.6 其他方法
Rosello等人[131]探索了一种完全不同的方法,使用强化学习框架训练一组帮助特征提取步骤的agents。该算法仅基于运动特征,不使用任何视觉信息。使用卡尔曼滤波器学习运动模型,该滤波器的行为由一个agent管理,每个跟踪对象使用一个agent。该agent学会了在一组动作之间决定卡尔曼滤波器应该采取什么动作,包括忽略预测、忽略新的度量、使用两个信息片段、启动或停止一条轨道。作者声称,他们的算法即使在非视觉场景下也能解决跟踪任务,而传统算法的性能受到视觉特征的深刻影响。然而,其MOT15的实验结果并不可靠,无法与其他模型进行比较,因为该模型是在训练集上测试的。
另一种仅依赖运动特征的算法是[132]中提出的算法。Babaee等人介绍了一个LSTM,它利用先前帧中的位置和速度信息,学会预测场景中每个对象的边界框的新位置和大小。利用预测边界框和实际detections之间的IOU,计算出一个相似性度量,并使用一个自定义贪婪算法将轨迹关联起来。将该方法应用于其他算法的跟踪结果,以解决遮挡问题,并证明该方法能有效地减少ID switch的数量。
3.3 深度学习用于相似度计算
虽然许多工作通过对CNN提取的特征使用某种距离测量来计算tracklet和detections(或tracklet和其他tracklet)之间的相似度,但也有一些算法使用深度学习模型直接输出相关性分数,而不必指定显式的特征之间的距离度量。本节重点介绍此类工作。
我们将首先描述使用递归神经网络的算法,从标准LSTMS(第3.3.1节)开始,然后描述孪生LSTMS(第3.3.2节)和双向LSTMS(第3.3.3节)的使用。第3.3.4节介绍了在多假设跟踪(MHT)框架中使用LSTM计算相似度。最后,在第3.3.5节中介绍了一些使用不同类型的递归网络进行关联计算的工作。
3.3.1 RNN和LSTM
第一个使用深度网络直接计算相似度的工作是[133],Milan 等提出了一种online MOT端到端学习方法。以一个基于RNN的循环神经网络模型作为主跟踪器,模拟了贝叶斯滤波算法,该算法由三部分组成:第一个是运动预测部分,它学习了一个运动模型,该模型将过去帧中的目标状态(即旧的边界框位置和大小)作为输入,并在不考虑检测的情况下预测下一帧中的目标状态。第二个部分使用新帧中的检测和关联向量(包含目标与所有detections的关联可能性)来细化状态预测。第三个部分负责管理轨迹的的初始化和终止,使用先前收集的信息来预测新的一帧中track存在的概率。使用基于LSTM的网络计算关联向量,该网络使用目标的预测状态和新的帧中检测状态之间的欧氏距离作为输入特征(除了隐藏状态和单元状态之外,与任何标准LSTM一样)。利用100K20帧长的综合生成序列分别对网络进行训练。虽然该算法优于其他技术,如卡尔曼滤波器和匈牙利算法的结合,但MOT15测试集的结果并没有达到最高精度。然而,该算法比其他算法运行得更快(165fps),并且没有使用任何外观特征,为将来的改进留下了空间。
在后来使用KSTM的其他工作中,有[123]使用具有全连接层的LSTM来融合其他3个LSTM提取的特征(如第3.2.4节所述),并输出一个相似度分数。总体算法与[134]中提出的基于马尔可夫决策过程(MDP)的框架相似:利用单目标跟踪器(SOT)独立跟踪目标,当目标被遮挡时,停止SOT,建立以LSTM计算的关联度作为边成本的二分图,并借助匈牙利算法解决关联问题。作者表明,使用所有3个特征提取器和LSTM的组合,而不是使用普通的全连接层,可以在MOT15验证集上持续获得更好的性能。该算法在发布时在MOT15和MOT16测试集上都达到了最先进的MOTA分数,证实了该方法的有效性。
另一种使用多个LSTM的方法是[52],Ran等人提出了一种基于姿态的三流网络,该网络通过结合其他3个LSTMS计算的相似度输出来计算相似度:一个用于外观相似度,使用CNN特征和使用alphapose[135]提取的姿势信息,一个用于运动相似度,使用姿势关节速度,另一个用于交互相似度(使用交互网格)。然后使用自定义跟踪算法来关联detections。与其他最先进的MOT算法相比,在他们的专有排球数据集上该方法更适合运动员追踪。
3.3.2 Siamese LSTM
Liang等人[136]还使用多个LSTM来建模各种功能,但它们以不同的方式进行。由于使用CNN提取外观特征的计算成本很高,因此他们进行了所谓的预关联步骤,该步骤使用SVM来预测轨迹和detections之间的关联概率。SVM把位置和速度相似性得分作为输入,使用两个LSTM进行位置和速度预测。然后,预关联步骤包括放弃具有低SVM相似度分数的detections。在此步骤之后,通过将VGG-16特征作为一个孪生LSTM的输入来执行实际的关联步骤,该LSTM预测了tracklet和检测之间的相似度分数。关联方式采用贪婪算法,将最高分数的检测结果关联到tracklet。在MOT17数据集进行了测试之后,测试结果与最高性能算法一致。
Wan等人[43]在他们的算法中也使用了孪生LSTM,它也由两个步骤组成。在第一步中,利用匈牙利算法建立了短的可靠的轨迹,并利用detections与预测目标位置之间的IOU(用卡尔曼滤波器或 Lucas-Kanad光流法获得)计算出相似性。第二步也使用匈牙利算法连接tracklets,但这次的相似度是使用孪生LSTM框架计算的,该框架使用了CNN提取的外观特征的运动特征(如[137]中所示),并在CUHK03 数据集上进行了预训练。
3.3.3 Bidirectional LSTM
Zhu等人提出了LSTM在相似度计算阶段的不同用法[115]。他们使用所谓的时间注意网络(TAN)来计算注意系数,以衡量空间注意网络(SAN)提取的特征(见第3.2.3节),从而降低观测的噪声,为此,采用了双向LSTM。整个网络(称为双匹配注意网络)被用来从遮挡中恢复跟踪目标,使用一个改进版本的高效卷积算子跟踪器(ECO)[56],训练利用难例挖掘,以及未能检测到的目标。该算法根据各种指标(MOTA、IDF1、ID switch)获得了与MOT16和MOT17上的online最先进方法相当的结果。
Yoon等人[138]还使用双向LSTM在一些编码非外观特征(仅边界框坐标和detections置信度)的全连接层上计算相似度,使用匈牙利算法解决关联问题。他们在斯坦福无人机数据集(SDD)[139]上对该网络进行了培训,并在SDD和MOT15上对其进行了评估。他们与不使用视觉信息的顶级算法取得了类似的结果,但性能仍然比基于外观的方法差。
3.3.4 在多假设跟踪框架中使用LSTM
在多假设跟踪(MHT)方法中,首先为每个候选目标建立一个潜在的跟踪假设树,然后计算每个跟踪的可能性,并选择具有最高可能性的跟踪组合作为解决方案。各种深度学习算法也被用来增强基于MHT的方法。
Kim等人[93]提出使用所谓的双线性LSTM作为MHT-DAM[83]算法的gating步骤,即使用LSTM计算的相似度分数来决定是否修剪假设树的某个分支。LSTM单元有一个修改过的前向传递(灵感来自于在[83]中提出的在线递归最小二乘估计),并将过去帧中tracklet的外观特征作为输入,用Resnet-50 提取。LSTM单元的输出是一个表示tracklet历史外观的特征矩阵,然后将该矩阵去乘以一个需要与tracklet进行比较的detections的外观特征向量。最上面的FV层最终计算出tracklet和检测之间的相似度得分。作者声称,这种改进的LSTM能够存储比经典LSTM更长期的外观模型。他们还建议添加一个经典的运动建模LSTM来计算历史运动特征(使用标准化边界框坐标和大小),然后在进行FC层和最终输出关联分数的SoftMax之前将这些特征与外观特征结合。首先对两个LSTM分别进行训练,然后进行联合微调。训练数据也经过增强,包括位置误差和漏检,以更接近真实数据。他们使用MOT15、MOT17、ETH、KITTI和其他次要数据集进行训练,并在MOT16和MOT17上评估模型。他们表明,他们的模型对检测质量很敏感,因为他们在使用public的Faster R-CNN和SDP检测时提高了MHTDAM的MOTA评分,而在使用public的DPM检测中表现较差。不管怎样,他们似乎得到了更高的IDF1分数(即使使用的不同的public detections),他们的总体结果反映,因为他们得到了所有基于MHT的算法方法中最高的IDF1。然而跟踪质量(MOTA和IDF1)仍然低于其他最先进的算法。
Maksai等人最近提出了RNN的类似用途[113],他还使用LSTM计算了MHT算法的一个变体中的tracklet分数,该算法迭代地增长和删减tracklet,然后尝试选择最大化其分数的tracklet集合。他们的目标是解决在训练循环网络进行多目标跟踪时经常出现的两个问题:损失评估不匹配,即通过优化与推理时使用的评估指标(例如分类得分 vs MOTA);暴露偏差,即模型在训练过程中未暴露错误时出现的偏差。为了解决第一个问题,他们引入了一种新的tracklets评分方法(使用RNN),该方法是IDF1指标的直接代理,不使用ground truth;然后可以训练网络来优化此类指标。第二个问题是通过在网络的训练集中添加当前网络计算的轨迹,以及在训练过程中的难例挖掘和随机轨迹合并来解决的;这样,训练集的分布应该更类似于推理时输入数据的分布。所使用的网络是一个双向LSTM,位于作为各种功能输入的嵌入层之上。作者提出了一个只使用几何特征的算法版本和一个使用基于外观特征的算法版本,效果更好。进行了大量的消融研究,并测试了各种替代方法。最后一种算法在考虑IDF1时,能够在各种MOT数据集(MOT15、MOT17、Dukemtmc[21])上达到最高性能,尽管它的MOTA评分并不高。
在MHT家族中使用RNN的其他方法,还有[104],Chen等人在Batch MHT跟踪策略中,使用所谓的递归度量网络(RMNET)计算tracklet假设和detections之间的外观相似性(以及基于运动的相似性)。RMNET是一个LSTM,它将所考虑的detection序列作为外观特征输入,用Resnet 提取,并将相似性得分与边界框回归参数一起输出。在gating和成形假设中采用了双阈值方法,并采用re-find奖励来鼓励从遮挡中恢复目标。通过将问题转化为二元线性规划问题来选择假设,并用lpSolve进行求解。最后利用卡尔曼滤波对轨道进行平滑处理。对MOT15、PETS209[34]、TUD[140]和KITTI进行评估,在IDF1指标上获得了更好的结果,与MOTA相比,行人重识别的权重更大
3.3.5 其他循环网络
Fang等人[96]在其用于行人跟踪的循环自回归网络(RAN)框架内使用了门循环单元(GRUS)[141]。GRU用于估计自回归模型的参数,一个用于运动,另一个用于每个被跟踪目标的外观,该模型根据轨迹的过去运动/外观特征计算观察给定检测运动/外观的概率。这两个概率,可以很容易地看作是一种相似性度量,然后相乘得到最终的关联概率,按照[134]中的算法,用于解决轨迹和检测之间关联的二部匹配问题。RAN训练步骤被定义为最大似然估计问题。
Kieritz等人[60]使用一个循环2层隐藏多层感知器(MLP)来计算检测和tracklet之间的外观相似度分数。然后将这种相似度作为另一个MLP的输入,加上跟踪和检测置信度分数,以预测总体相似度分数(称为“关联度量”)。匈牙利算法最终利用这一得分进行关联。该方法在UA-DETRAC数据集[32]上达到了最高性能,但与其他使用private 检测的算法相比,其在MOT16上的表现并不理想。
3.3.6 CNN用于相似度计算
其他算法用CNN代替计算某种相似性得分。Tang等人[51]测试了使用4个不同的CNN来计算一个图中节点之间的相似度得分,关联任务被定义为一个最小成本提升的多分割问题[142]:它可以看作是一个图聚类问题,其中每个输出聚类代表一个跟踪对象。边成本解释了两个detections之间的相似性,这种相似性是行人重识别的置信度、深度匹配和时空关联的结合。为了计算行人重识别相似度,测试了各种体系结构(在对从MOT15、MOT16、CUHK03、Market-1501数据集中提取的2511个身份数据集进行训练之后),但性能最好的是StackNetPose,它包含使用DeepCut身体部位检测器[105]提取的身体部位信息(见第3.2.2节)。两幅图像的14个身体部位的分数图与两幅图像本身叠加在一起,产生20个通道的输入。网络遵循VGG-16体系结构,在两个输入标识之间输出一个相似度分数。与孪生CNN不同的是,这两幅图像能够在网络的早期阶段进行“通信”。结果表明,StackNetPose网络在行人重识别任务中有较好的表现,可以用来计算REID的相似度。结合相似度得分通过将一个权重向量(通过逻辑回归学习,并依赖于两次detections之间的时间间隔)与一个包含REID相似度的14维向量相乘计算得出,基于DeepMatching的相似度[143],一个时空相似度分数,两个detections置信度的最小值和二次项与前面提到的所有项的成对组合。作者表明,将所有这些特性结合起来产生了更好的结果,并且在将问题框架化为最低成本解决的多目标问题方面进行了改进(使用[144]中提出的算法进行启发式求解),他们在发布时成功地在MOT16数据集上获得了最先进的结果(以MOTA分数衡量)。
另一种使用CNN的方法在[145]中提出,Chen等人使用粒子滤波器[146]来预测目标运动,使用改进的Faster R-CNN网络来加权每个粒子的权重。这种模型被训练来预测边界框包含一个物体的概率,但是它也被增加了一个特定于目标的分支,该分支从CNN的较低层作为输入特征,并将它们与目标历史特征合并,以预测两个物体的概率。与前面的方法不同的是,这里计算的是采样粒子和跟踪目标之间的相似度,而不是计算目标和detections之间的相似度。未与跟踪对象重叠的检测被用来初始化新的跟踪或检索丢失的对象。尽管它是一种online跟踪算法,但在发布时,无论是使用public detections还是使用private detections,它都能够在MOT15上达到最高性能(从[147]获得)。
Zhou等人[117]使用一个视觉相似性CNN,类似于第3.2.3节中介绍的基于Resnet-101的视觉位移CNN,该CNN输出检测和由深度连续条件随机场预测的tracklet之间的相似性分数。该视觉相似度得分与使用IOU的空间相似度相结合,然后将得分最高的检测与每个tracklet相关联;如果发生冲突,则采用匈牙利算法。该方法在MOTA分数方面达到了与MOT15和MOT16上最先进的online MOT算法相当的结果。
3.3.7 Siamese CNNs
Siam0ese CNN也是相似度计算中常用的方法。Siamese CNN的一个例子如图4所示。这里介绍的方法决定直接使用Siamese CNN的输出作为相似度,而不是使用从网络倒数第二层提取的特征向量之间的经典距离,如第3.2.3节中介绍的算法。例如,Ma等人[148]在两步算法中,使用一个来计算轨迹之间的相似关系。他们选择应用层次相关聚类,解决了连续提出的两个多分割问题:局部数据关联和全局数据关联。在局部数据关联步骤中,通过使用[149]中提出的鲁棒相似性度量将时间上相关的detections关联在一起,该度量使用DeepMatching和检测置信度来计算detections之间的相似度分数。在这一步中,只关联detections之间的边被插入到图中,从而用[144]中提出的启发式算法解决了多分割问题。在全局数据关联步骤中,需要将被长期遮挡分割的局部轨迹连接在一起,然后构建一个与所有轨迹完全连接的图。Siamese CNN被用来计算关系图中作为边成本的相关性,该结构是基于GoogleNet[2]的,并在Imagenet上进行了预训练,然后在Market-1501 REID数据集上对网络进行训练,然后在MOT15和MOT16训练序列上进行微调。除了验证层外,在两个图像之间输出一个相似性得分,只有在训练过程中才将两个分类层添加到网络中,以对每个训练图像的身份进行分类,从而提高了计算相似性得分的网络性能。这种所谓的“通用”REID网络也可以无监督的方式在每个测试序列上进行微调,而不使用任何Ground Truth,以使网络适应每个特定序列的照明条件、分辨率、相机角度等。这是通过抽样正负detections对,通过查看在局部数据关联步骤中构建的tracklets来完成的。该算法的有效性通过在MOT16上获得的结果得到了证明,在该论文发表时取得了最佳表现,该算法的MOTA得分为49.3。
如第3.2.3节所述,Lee等人[119]使用特征金字塔孪生网络提取外观特征,在MOT问题中使用这种网络时,将运动特征向量连接到外观特征上,然后在顶部添加3个完全连接的层,以预测轨迹和detections之间的相似度分数;对网络进行端到端的训练。然后,检测以迭代方式关联,从相似度得分最高的对开始,当得分低于阈值时停止。该方法在发布时在MOT17数据集的online算法中获得了最高的性能结果。
3.4 深度学习用于关联/跟踪步骤
一些工作,虽然不如pipeline中的其他步骤那么多,但使用了深度学习模型来改进经典算法(如匈牙利算法)执行的关联过程,或管理track状态(例如,通过决定启动或终止跟踪)。我们将在本节中介绍它们,包括RNN的使用(第3.4.1节)、深层多层感知器(第3.4.2节)和深层强化学习agents(第3.4.3节)。
3.4.1 循环神经网络
Milan等人提出了一个使用深度学习来管理track状态的算法的第一个例子。在[133]中,已经在第3.3.1节中描述过,它使用RNN预测每帧中存在轨道的概率,从而帮助决定何时启动或终止轨道。
Ma等人[116]使用双向GRU RNN来决定在何处拆分轨迹。该算法分为三个主要阶段:轨迹生成步骤,其中包括一个去除多余检测的NMS步骤,然后将具有外观和运动相似性的匈牙利算法结合起来形成高置信轨迹; 然后,执行tracklet切割步骤:由于tracklet可能包含由于遮挡导致的ID Switch错误,因此此步骤旨在在ID Switch发生的点拆分tracklet,以便获得包含相同身份的两个单独的tracklet; 最后,使用定制的关联算法,利用Siamese 双向GRU提取的特征,采用tracklet重连步骤。然后用多项式曲线拟合来填充新形成的轨迹中的间隙。切割步骤是用双向GRU RNN执行的,该RNN使用由一个Wide Residual网络CNN提取的特征[92]。GRU为每个帧输出一对特征向量(GRU的每个方向一个); 然后计算这些特征向量对之间的距离,得到距离向量。如果分数高于阈值,则该向量中的最高值指示了拆分tracklet的位置。reconnection GRU也是类似,但它在GRU顶部有一个额外的FC层和一个临时池层,以提取代表整个tracklet的特征向量;然后使用两个tracklet功能之间的距离来决定要重新连接的tracklet。该算法得到的结果与MOT16数据集的最先进的方法相当。
3.4.2 深度多层感知机
尽管不是一个很常见的方法,深层多层感知器(MLP)也被用来指导跟踪过程。例如,Kieritz等人[60]使用一个具有两个隐藏层的MLP计算跟踪置信度得分,将上一步的跟踪得分和上次相关检测的各种信息(如关联得分和检测置信度)作为输入。这个置信度分数被用来管理跟踪的终止:他们实际上决定通过时间来保持固定数量的目标,用新的跟踪替换置信度分数最低的旧的跟踪。其余算法已在第3.3.5节中进行了解释。
3.4.3 深度强化学习agents
一些研究使用了深层强化学习(RL)agents来在跟踪过程中做出决策。Rosello等人[131]如第3.2.6节所述,使用多个深RL代理来管理各种跟踪目标,决定何时启动和停止跟踪,并影响卡尔曼滤波器的运行。该代理使用具有3个隐藏层的MLP进行建模。
Ren等人[150]还使用协作环境中的多个Deep RL agents来管理关联任务。该算法主要由预测网络和决策网络两部分组成。预测网络是一个CNN,学习预测目标在新帧中的运动,观察目标和新图像,并使用最近的tracklet轨迹。决策网络是一个由多个agents(每个跟踪目标一个)和环境组成的协作系统。每个代理根据自己、邻居和环境的信息做出决定;代理与环境之间的交互作用是通过最大化共享效用功能来利用的:因此,代理之间没有独立运行。每个代理/对象都由轨迹、其外观特征(使用MDNET[151]提取)和当前位置表示。环境由新框架中的detections表示。检测网络以每个目标在新帧中的预测位置(由预测网络输出)、最近的目标和最近的检测为输入,并根据检测可靠性和目标遮挡状态等各种因素,在各种行为中选择一种:使用预测和检测更新轨迹及其外观特征,忽略detection,仅使用预测更新轨迹,检测被跟踪目标的遮挡,删除轨迹。在MDNET的特征提取部分之上,使用3个FC层对agents进行建模。各种对照实验表明,用预测和检测网络代替线性运动模型和匈牙利算法的有效性,该方法在MOT15和MOT16数据集上取得了很好的效果,在online方法中达到了最先进的性能。尽管有相当多的ID Switch。
3.5 深度学习在MOT问题中的其他应用
在本节中,我们将介绍深度学习模型的其他有趣用法,这些方法不完全适合多目标跟踪算法的四个常见步骤之一。因此,此类工程并未包括在表7中,而是汇总在表1中。
| 论文编号 | 检测 | 描述 | 模式 | 源和数据 |
|---|---|---|---|---|
| [152] | N/A | 他们在现有的各种MOT算法中集成了一个边界框回归步骤。回归是通过使用CNN功能的深层强化学习来完成的。 | N/A | |
| [153] | Public | 使用2个CNN、颜色直方图和一个KLT运动检测器的集合计算马尔可夫链蒙特卡罗采样的相似性;使用位置采样形成短轨迹。采用变点检测算法对轨迹进行合并和删除。 | Online | |
| [154] | CNN | 多重伯努利滤波器与一个新的交互可能性,使用CNN计算。 | Online | |
| [155] | Public | 行人的检测通过使用CNN获得的头部检测进行改进[156]。利用Frank Wolfe算法的一个改进版本,利用空间和时间成本来解决关联的相关聚类问题。 | Batch | |
| [157] | Public | 修正了MDNET CNN的目标特定分支,用高斯抽样法计算目标和候选对象之间的相似度关系。结合外观和运动功能,减少ID Switch。 | Online | |
| [158] | Public | CNN提取应用程序功能,LSTM提取运动功能。LSTM是BF网络的一部分,它执行贝叶斯滤波,并使用匈牙利算法的输出进行跟踪细化。 | Online | |
| [159] | Public | PafNet和PartNet CNNs用于区分目标和背景以及目标之间的差异。采用KCF SOT跟踪器,SVM+匈牙利算法进行误差恢复。经深度学习训练过的CNN用于模型更新。 | Online |
一个例子是[152],其中Jiang等人在使用许多MOT算法后,使用Deep RL agent执行边界框回归。该方法实际上完全独立于所采用的跟踪算法,可以作为后验算法提高模型的精度。一个VGG-16 CNN被用来从边界框所包围的区域中提取外观特征,然后将这些特征连接到一个表示代理最后10次操作历史的向量。最后,使用由3个完全连接的层组成的Q-Net[160]预测13个可能动作中的一个,包括边界框的运动和缩放以及终止动作,以表示回归完成。在各种最先进的MOT算法上使用这种边界框回归技术,MOT15数据集上的MOTA绝对值提高了2到7个点,在公共检测方法中达到最高分数。作者还表明,如用Faster R-CNN模型计算边界盒回归,他们的回归方法比传统方法有更好的结果。
Lee等人[153]提出了一种多类多目标跟踪器,该跟踪器使用一组探测器(包括CNN模型,如VGG-16和Resnet)来计算每个目标在下一帧中特定位置的可能性。利用马尔可夫链蒙特卡罗抽样方法,从受上述相似性影响的分布中预测每个目标的下一个位置,并结合对轨道出生和死亡概率的估计,建立了短轨道段。最后,采用变点检测[161]算法检测代表航迹段的平稳时间序列的突变;这样做是为了检测轨迹漂移,消除不稳定轨迹段,并将这些轨迹段组合在一起。该算法的结果与使用Private检测的最先进的MOT方法相当。
Hoak等人[154]提出了一个5层CNN网络,在Caltech行人检测数据集[162]上进行训练,以计算目标在图像中特定位置的可能性。他们使用多重伯努利滤波器(使用[163]中的粒子滤波算法实现),并为每个粒子计算一个新的交互可能性(ILH),以便根据它们与属于其他目标的粒子之间的距离对其进行加权;这样做是为了防止从属于不同对象的区域采样的算法。该算法在VSPETS 2003 INMOVE soccer数据集和AFL数据集[164]上取得了良好的效果。
Henschel等人[155]除了常规的身体检测外,还使用了用CNN[156]提取的头部检测来执行行人跟踪。头部的存在/不存在及其相对于边界框的位置有助于确定边界框是真是假。将关联问题建模为图上的关联聚类问题,并用Frank Wolfe算法[165]的修改版本解决;关联成本计算为空间和时间成本的组合:空间成本为距离和时间成本。在检测到的和预测的头部位置之间;时间成本是使用两帧之间像素之间的对应关系计算的,使用DeepMatching获得[79]。该算法在MOT17上达到最高MOTA分数,在MOT16上达到第二最佳分数。
Gan等人[157]在其在线行人跟踪框架中使用了修改过的MDNET[151]。除了所有目标共有的3个共享卷积层外,每个目标还具有3个特定的fc层,这些层在线更新以捕获目标的外观变化。一组候选框(包括与目标最后一个边界框相交的检测)和一组使用线性运动模型估计参数的高斯分布采样框(作为网络的输入),这些候选框输出每个候选框的置信度得分。得分最高的候选人被认为是最佳估计目标位置。为了减少ID Switch错误的数量,算法尝试使用对之间的另一个相似性度量来查找与估计框最相似的过去的轨迹; 使用外观和运动提示以及tracklet置信度评分和碰撞因子计算这种相似度。检测还用于初始化新的轨迹,并在发生遮挡时修复运动预测错误。
Xiang等人[158]用MetricNet跟踪行人。该模型将一个相似性模型与轨迹估计相统一,并用贝叶斯滤波器进行滤波。一个外观模型,由一个VGG-16 CNN制成,接受过各种数据集的人员重新识别、提取特征和执行边界框回归训练;运动模型由两部分组成:一个基于LSTM的特征抽取器,作为轨迹过去坐标的输入,以及一个所谓的BF网络在顶部,由不同的FC层组成,结合LSTM提取的特征和检测盒(由匈牙利算法选择)来执行贝叶斯滤波步骤并输出目标的新位置。使用三重损失对MetricNet进行培训,类似于前面章节中介绍的其他模型。该算法在MOT16和MOT15上分别获得了最佳和次优结果。
最后,Chu等人[159]在算法中使用了三种不同的CNN。第一个被称为Pafnet[166],用于区分跟踪对象的背景。第二个被称为Partnet[167],用于区分不同的目标。第三个CNN由一个卷积层和一个FC层组成,用来决定是否刷新跟踪模型。整个算法的工作原理如下:对于前一帧中的每个跟踪目标,在当前帧中使用PafNet和PartNet计算出两个得分图。然后,使用内核相关滤波器跟踪器[168]预测对象的新位置。此外,在一定数量的帧之后,执行了一个所谓的检测验证步骤:通过解决一个图多分割问题,将检测器输出的检测(在他们的实验中,他们选择使用随数据集提供的公共检测)分配给跟踪目标。与特定帧数的检测没有关联的目标被终止。然后,第三个CNN被用来检查相关的检测盒是否比预测的更好。如果是这样,则更新KCF模型参数以反映对象特征的变化。这样的CNN使用PafNet提取的图,并通过强化学习进行训练。然后,利用SVM分类器和匈牙利算法,利用非关联检测从目标遮挡中恢复。最后,剩余的非关联检测被用来初始化新的目标。该算法在MOT15和MOT16两个数据集上进行了评估,第一个数据集达到了最高性能,第二个数据集达到了online方法的最高性能。
4 分析和比较
本节将对所有在其中一个MotChallenge数据集上测试其算法的作品进行比较。我们将只关注MotChallenge数据集,因为对于其他数据集,没有足够的相关论文使用深度学习来执行有意义的分析。
我们首先描述了实验分析的环境,在第4.1节第4.2节将介绍分析得出的实际结果和考虑因素。
4.1 环境和组织
为了公平比较,我们只显示整个测试集上报告的结果。一些讨论过的论文使用测试集的子集或从MOTchallenge数据集的训练分割中提取的验证数据集来报告其结果。这些结果被丢弃,因为它们与其他结果不可比。此外,报告的结果分为使用public检测的算法和使用private检测的算法,因为检测的不同质量对性能有很大影响。由于online方法处于劣势,只能访问当前和过去的信息来分配每个帧中的id,因此结果进一步分为online方法和batch(offline)方法。
对于每一种算法,我们都指出参考发表论文的年份、它们的操作模式(batch与online);MOTA、MOTP、IDF1,基本跟踪(MT)和基本丢失(ML)的度量,以百分比表示;误检(FP)、漏检(FN)、身份切换(IDS)的绝对数量)和分段(frag);以每秒帧数(Hz)表示的算法速度。对于每个指标,向上的箭头(+)表示得分越高越好,向下的箭头(+)表示相反。这里显示的指标与MOTchallenge网站上的公共排行榜上的指标相同。参考文献中给出的数值结果与MOTchallenge排行榜中的数据进行了整合。
根据前面提出的分类,显示了每个组合数据集/检测源的表。表2和表3分别显示了MOT15使用公共检测和私有检测的结果;表4和表5也显示了MOT16的结果;最后,表6显示了MOT17的结果,后者目前只发布了使用公共检测的算法。每一个表格分别online分组和batch方法,对于每一组,论文按年份排序,如果论文来自同一年,则按MOTA分数升序排序,因为这是MOTchallenge数据集中考虑的主要指标。如果一个工作在同一个数据集上呈现多个结果,使用相同的检测集和相同的操作模式,我们只显示MOTA最高的结果。每一个指标的最佳表现都在页面中突出显示,而在相同模式(batch/online)下运行的论文中的最佳表现则在页面中突出显示。值得注意的是,虽然对Hz度量的比较可能不可靠,因为性能通常只报告给算法的跟踪部分。没有检测步骤,有时也不包括深度学习模型的运行时,这通常是本次调查中提出的算法中计算最密集的部分。此外,这些算法在不同的硬件上运行。
4.2 讨论结果
一般观察结果
正如预期的那样,每个数据集上性能最好的算法都使用私有检测器,这证实了检测质量主导着跟踪器的整体性能:在MOT15上为56.5%比42.3%,在MOT16上为71.0%比49.3%。此外,在MOT16和MOT17上,offline算法略优于online算法,尽管online方法逐渐接近offline算法的性能。事实上,在MOT15上,使用深度学习的最佳报告算法以online方式运行。然而,这可能是对开发在线方法更为关注的结果,这是MOT深入学习研究社区的一个趋势。
另一件值得注意的事情是,由于MOTA分数基本上是FP、FN和ID switch的标准化总和,并且由于FN的数量通常至少比FP高一个数量级,比ID switch高两个数量级,因此有效地减少FN数量的方法是获得最佳性能的方法。事实上,根据[14]中发现的结果,我们可以观察到MOTA和FN数量之间的强相关性:MOTA和FN值通过皮尔逊相关系数−MOT15:0.95 、−MOT16:0.98 和−MOT17:0.95 。因此,虽然在减少使用公共detections的FN方面的改进有限,但最有效的方法仍然是建立和培训一个自定义检测器;FN数量减半实际上是private检测器导致更好跟踪性能的主要原因。

表2:基于深度学习和public检测的MOT算法在MOT15数据集上的实验结果。

表3:基于深度学习和private检测的MOT算法在MOT15数据集上的实验结果。
在MOT四个步骤中的最好方法
说到私人检测器,表格显示,目前性能最好的探测器是更快的R-CNN及其变种。事实上,在[38]中提出的算法使用了改进的更快的R-CNN,在MOT16的在线方法中保持了3年的排名,许多其他性能最好的MOT16算法也采用了相同的检测方法。
在特征提取方面,三个考虑的数据集上的所有顶级执行方法都使用CNN来提取外观特征,其中最常见的是GoogleNet(inception系列)。不利用外观的方法(使用深度或经典方法提取)的性能往往更差。然而,视觉特征还不够:许多最佳算法还使用其他类型的特征来计算亲和力,尤其是运动特征。事实上,像LSTM和Kalman滤波器这样的算法经常被用来预测下一帧中目标的位置,这通常有助于提高关联的质量。各种贝叶斯滤波算法,如粒子滤波和假设密度滤波,也被用于预测目标运动,[158,145,98]它们受益于使用深层模型。
虽然深度学习在检测和特征提取中起着重要的作用,但是使用深度网络学习相似函数的应用并不普遍,而且还没有被证明是一个好的MOT算法的必要条件,尽管一些研究已经充分利用了它。很少有研究工作探索使用深度学习模型来指导关联过程,这可能是未来方法的一个有趣的研究方向。

表4:基于深度学习和public检测的MOT算法在MOT16数据集上的实验结果。

基于深度学习和private检测的MOT算法在MOT16数据集上的实验结果。
其他顶级表现算法的趋势
在目前排名最高的方法中,还可以识别出一些其他的趋势。例如,在线方法中一个成功的方法是使用单目标跟踪算法,适当地修改以解决MOT任务。事实上,3个数据集上一些性能最好的在线算法使用了一个SOT跟踪器,该跟踪器采用了深度学习技术,以从遮挡中恢复或刷新目标模型[159115123]。有趣的是,据我们所知,目前还没有一种自适应的SOT算法被用于跟踪私人detections。正如我们已经观察到的,使用私人检测可以减少完全未被发现的目标的数量;由于SOT追踪器在被识别后通常不需要检测来跟踪目标,因此,FN目标的减少可能使丢失轨迹,从而提高追踪器的整体性能。因此,将SOT跟踪器应用于个体检测是进一步提高MOTCHAllenge数据集检测结果的一个很好的研究方向。offline方法还可以利用SOT跟踪器来查看过去的帧,以便在目标被检测器第一次识别之前恢复漏检。
许多方法通过将任务定义为图优化问题来执行关联,批处理方法尤其受益于此,因为它们可以对它们执行全局优化。例如,在CNN计算相似度的帮助下,最小成本提升的多分割问题在MOT16上达到了最佳性能[148,51],而在两个MOT17方法上使用了异构关联图融合和相关聚类[103,155]。
最后,我们可以注意到,边界框的精度从根本上影响了算法的最终性能,事实上,MOT15上排名最高的跟踪器[89]只需对以前最先进的输出执行边界框回归步骤,就获得了相对较高的MOTA分数。使用深度强化学习agents的算法[89]。开发一种有效的边界盒回归器,并将其应用到未来的MOT算法中,是一个尚未深入探索的有趣的研究方向。此外,offline方法也可以尝试利用未来和过去的目标外观来更准确地回归正确目标周围的边界框,而不是依靠一个单独的框架来固定这些框,这样可以使它们在发生遮挡时包围正确的目标。

基于深度学习和public检测的MOT算法在MOT17数据集上的实验结果。
5 结论和未来的方向
我们对所有采用深度学习技术的MOT算法进行了全面描述,重点介绍单摄像机视频和2D数据。描述了通用MOT的四个主要步骤:检测、特征提取、相似度计算和关联。深度学习在这四个步骤中的每一个都得到了探索。虽然大多数方法都集中在前两种方法上,但也存在一些深入学习学习相似函数的应用,但很少有方法使用深入学习来直接指导关联算法。对MOTsChallenge数据集的结果进行了数值比较,结果表明,尽管方法多种多样,但在所述方法中仍可以发现一些共性:
- detection的质量很重要:FN的数量仍然主导着MOTA分数。虽然深入学习使得使用公共检测的算法在这方面有所改进,但使用更高质量的检测仍然是减少误报的最有效方法。因此,在检测步骤中仔细使用深度学习可以显著提高跟踪算法的性能。
- CNN在特征提取中是必不可少的:外观特征的使用也是良好跟踪器的基础,而且CNN在提取这些特征方面特别有效。此外,强跟踪器倾向于将其与运动特征结合使用,这些特征可以使用LSTM、卡尔曼滤波器或其他贝叶斯滤波器进行计算。
- SOT跟踪器和全局优化工作:SOT跟踪器在深度学习的帮助下适应MOT任务,最近产生了性能良好的在线跟踪器;而offline方法则得益于全局图优化算法中深层模型的集成。
随着深入学习在现代交通运输领域的应用,许多有前途的研究方向也得到了确定。
- 将深度学习应用于不同的多目标跟踪:大多数基于深度学习的运动目标跟踪算法都侧重于行人跟踪。由于不同类型的目标构成了不同的挑战,应调查使用深网络跟踪车辆、动物或其他物体的可能改进;
- 应用深度学习指导关联步骤:利用深度学习来指导关联算法和直接执行跟踪还处于起步阶段:在这个方向上还需要更多的研究来了解深度算法在这一步中是否也有用;
- 将SOT跟踪器与专用检测结合起来:一种减少丢失轨道数量,从而减少FN的可能方法是将SOT跟踪器与专用检测结合起来,特别是在offline环境中,在这种情况下,可以恢复过去的错过的detections;
- 研究边界框回归:使用边界框回归是获得更高MOTA分数的一个有希望的步骤,但尚未对此进行详细探讨,应进一步研究改进,例如,使用过去和将来的信息来指导回归。
最后,由于所提出的算法中很少有提供了对其源代码的公开访问,我们希望鼓励未来的研究人员发布它们的代码,以便更好地展示它们的结果,并有益于整个研究社区。
参考文献
[1]Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014.
[2]Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan,Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. InProceedings of the IEEEconference on computer vision and pattern recognition, pages 1–9, 2015.
[3]Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[4]Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection withregion proposal networks. InAdvances in neural information processing systems, pages 91–99, 2015.
[5]Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander CBerg. Ssd: Single shot multibox detector. InEuropean conference on computer vision, pages 21–37. Springer,2016.
[6]Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. InProceedings of the IEEE conference oncomputer vision and pattern recognition, pages 7263–7271, 2017.
[7]Ha ̧sim Sak, Andrew Senior, and Françoise Beaufays. Long short-term memory recurrent neural networkarchitectures for large scale acoustic modeling. InFifteenth annual conference of the international speechcommunication association, 2014.
[8]Martin Sundermeyer, Ralf Schlüter, and Hermann Ney. Lstm neural networks for language modeling. InThirteenth annual conference of the international speech communication association, 2012.
[9]Yuchen Fan, Yao Qian, Feng-Long Xie, and Frank K Soong. Tts synthesis with bidirectional lstm based recurrentneural networks. InFifteenth Annual Conference of the International Speech Communication Association, 2014.
[10]Erik Marchi, Giacomo Ferroni, Florian Eyben, Leonardo Gabrielli, Stefano Squartini, and Björn Schuller.Multi-resolution linear prediction based features for audio onset detection with bidirectional lstm neural networks.In2014 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 2164–2168.IEEE, 2014.
[11]Wenhan Luo, Junliang Xing, Anton Milan, Xiaoqin Zhang, Wei Liu, Xiaowei Zhao, and Tae-Kyun Kim. Multipleobject tracking: A literature review.arXiv preprint arXiv:1409.7618, 2014.
[12]Massimo Camplani, Adeline Paiement, Majid Mirmehdi, Dima Damen, Sion Hannuna, Tilo Burghardt, and LiliTao. Multiple human tracking in rgb-depth data: a survey.IET computer vision, 11(4):265–285, 2016.
[13]Patrick Emami, Panos M Pardalos, Lily Elefteriadou, and Sanjay Ranka. Machine learning methods for solvingassignment problems in multi-target tracking.arXiv preprint arXiv:1802.06897, 2018.
[14]Laura Leal-Taixé, Anton Milan, Konrad Schindler, Daniel Cremers, Ian Reid, and Stefan Roth. Tracking thetrackers: An analysis of the state of the art in multiple object tracking.arXiv preprint arXiv:1704.02781, 2017.
[15]Laura Leal-Taixé, Anton Milan, Ian Reid, Stefan Roth, and Konrad Schindler. Motchallenge 2015: Towards abenchmark for multi-target tracking.arXiv preprint arXiv:1504.01942, 2015.
[16]Anton Milan, Laura Leal-Taixé, Ian Reid, Stefan Roth, and Konrad Schindler. Mot16: A benchmark formulti-object tracking.arXiv preprint arXiv:1603.00831, 2016.
[17]Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. InProceedings of the IEEEinternational conference on computer vision, pages 2961–2969, 2017.
[18]Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-fcn: Object detection via region-based fully convolutionalnetworks. InAdvances in neural information processing systems, pages 379–387, 2016.
[19]Bo Wu and Ram Nevatia. Tracking of multiple, partially occluded humans based on static body part detection.In2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 1,pages 951–958. IEEE, 2006.
[20]Keni Bernardin and Rainer Stiefelhagen. Evaluating multiple object tracking performance: the clear mot metrics.Journal on Image and Video Processing, 2008:1, 2008.
[21]Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Performance measures and adata set for multi-target, multi-camera tracking. InEuropean Conference on Computer Vision, pages 17–35.Springer, 2016.
[22]Rainer Stiefelhagen and John Garofolo.Multimodal Technologies for Perception of Humans: First InternationalEvaluation Workshop on Classification of Events, Activities and Relationships, CLEAR 2006, Southampton, UK,April 6-7, 2006, Revised Selected Papers, volume 4122. Springer, 2007.
[23]Rainer Stiefelhagen, Rachel Bowers, and Jonathan Fiscus.Multimodal Technologies for Perception of Humans:International Evaluation Workshops CLEAR 2007 and RT 2007, Baltimore, MD, USA, May 8-11, 2007, RevisedSelected Papers, volume 4625. Springer, 2008.
[24]Piotr Dollár, Ron Appel, Serge Belongie, and Pietro Perona. Fast feature pyramids for object detection.IEEEtransactions on pattern analysis and machine intelligence, 36(8):1532–1545, 2014.
[25]Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester, and Deva Ramanan. Object detection withdiscriminatively trained part-based models.IEEE transactions on pattern analysis and machine intelligence,32(9):1627–1645, 2009.
[26]Ross B. Girshick, Pedro F. Felzenszwalb, and David McAllester. Discriminatively trained deformable partmodels, release 5.http://people.cs.uchicago.edu/~rbg/latent-release5/, 2012.
[27]Fan Yang, Wongun Choi, and Yuanqing Lin. Exploit all the layers: Fast and accurate cnn object detector withscale dependent pooling and cascaded rejection classifiers. InProceedings of the IEEE conference on computervision and pattern recognition, pages 2129–2137, 2016.
[28]Patrick Dendorfer, Hamid Rezatofighi, Anton Milan, Javen Shi, Daniel Cremers, Ian Reid, Stefan Roth, KonradSchindler, and Laura Leal-Taixe. Cvpr19 tracking and detection challenge: How crowded can it get?, 2019.
[29]Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti visionbenchmark suite. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361.IEEE, 2012.
[30]Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013.
[31]Xiaoyu Wang, Ming Yang, Shenghuo Zhu, and Yuanqing Lin. Regionlets for generic object detection. InProceedings of the IEEE international conference on computer vision, pages 17–24, 2013.
[32]Longyin Wen, Dawei Du, Zhaowei Cai, Zhen Lei, Ming-Ching Chang, Honggang Qi, Jongwoo Lim, Ming-HsuanYang, and Siwei Lyu. Ua-detrac: A new benchmark and protocol for multi-object detection and tracking.arXivpreprint arXiv:1511.04136, 2015.
[33]Mykhaylo Andriluka, Stefan Roth, and Bernt Schiele. Monocular 3d pose estimation and tracking by detection.In2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 623–630. IEEE,2010.
[34]James Ferryman and Ali Shahrokni. Pets2009: Dataset and challenge. In2009 Twelfth IEEE InternationalWorkshop on Performance Evaluation of Tracking and Surveillance, pages 1–6. IEEE, 2009.
[35]Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468. IEEE, 2016.
[36]Rudolph Emil Kalman. A new approach to linear filtering and prediction problems.Journal of basic Engineering,82(1):35–45, 1960.
[37]Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly,2(1-2):83–97, 1955.
[38]Fengwei Yu, Wenbo Li, Quanquan Li, Yu Liu, Xiaohua Shi, and Junjie Yan. Poi: Multiple object tracking withhigh performance detection and appearance feature. InEuropean Conference on Computer Vision, pages 36–42.Springer, 2016.
[39]Sean Bell, C Lawrence Zitnick, Kavita Bala, and Ross Girshick. Inside-outside net: Detecting objects in contextwith skip pooling and recurrent neural networks. InProceedings of the IEEE conference on computer vision andpattern recognition, pages 2874–2883, 2016.
[40]Spyros Gidaris and Nikos Komodakis. Object detection via a multi-region and semantic segmentation-aware cnnmodel. InProceedings of the IEEE International Conference on Computer Vision, pages 1134–1142, 2015.
[41]Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep associationmetric. In2017 IEEE International Conference on Image Processing (ICIP), pages 3645–3649. IEEE, 2017.
[42]Nima Mahmoudi, Seyed Mohammad Ahadi, and Mohammad Rahmati. Multi-target tracking using cnn-basedfeatures: Cnnmtt.Multimedia Tools and Applications, 78(6):7077–7096, 2019.
[43]Xingyu Wan, Jinjun Wang, and Sanping Zhou. An online and flexible multi-object tracking framework usinglong short-term memory. InProceedings of the IEEE Conference on Computer Vision and Pattern RecognitionWorkshops, pages 1230–1238, 2018.
[44]Takayuki Ujiie, Masayuki Hiromoto, and Takashi Sato. Interpolation-based object detection using motion vectorsfor embedded real-time tracking systems. InProceedings of the IEEE Conference on Computer Vision andPattern Recognition Workshops, pages 616–624, 2018.
[45] Qizheng He, Jianan Wu, Gang Yu, and Chi Zhang. Sot for mot.arXiv preprint arXiv:1712.01059, 2017.
[46]Minghua Li, Zhengxi Liu, Yunyu Xiong, and Zheng Li. Multi-person tracking by discriminative affinity modeland hierarchical association. In2017 3rd IEEE International Conference on Computer and Communications(ICCC), pages 1741–1745. IEEE, 2017.
[47]Wenbo Li, Ming-Ching Chang, and Siwei Lyu. Who did what at where and when: Simultaneous multi-persontracking and activity recognition.arXiv preprint arXiv:1807.01253, 2018.
[48]Felipe Jorquera, Sergio Hernández, and Diego Vergara. Probability hypothesis density filter using determinantalpoint processes for multi object tracking.Computer Vision and Image Understanding, 2019.
[49]Zhao Zhong, Zichen Yang, Weitao Feng, Wei Wu, Yangyang Hu, and Cheng-lin Liu. Decision controller forobject tracking with deep reinforcement learning.IEEE Access, 2019.
[50]Weigang Lu, Zhiping Zhou, Lijuan Zhang, and Guoqiang Zheng. Multi-target tracking by non-linear motionpatterns based on hierarchical network flows.Multimedia Systems, pages 1–12, 2019.
[51]Siyu Tang, Mykhaylo Andriluka, Bjoern Andres, and Bernt Schiele. Multiple people tracking by lifted multicutand person re-identification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 3539–3548, 2017.
[52]Nan Ran, Longteng Kong, Yunhong Wang, and Qingjie Liu. A robust multi-athlete tracking algorithm byexploiting discriminant features and long-term dependencies. InInternational Conference on MultimediaModeling, pages 411–423. Springer, 2019.
[53]Haigen Hu, Lili Zhou, Qiu Guan, Qianwei Zhou, and Shengyong Chen. An automatic tracking method formultiple cells based on multi-feature fusion.IEEE Access, 6:69782–69793, 2018.
[54]Lei Zhang, Helen Gray, Xujiong Ye, Lisa Collins, and Nigel Allinson. Automatic individual pig detection andtracking in pig farms.Sensors, 19(5):1188, 2019.
[55]Zongwei Zhou, Junliang Xing, Mengdan Zhang, and Weiming Hu. Online multi-target tracking with tensor-based high-order graph matching. In2018 24th International Conference on Pattern Recognition (ICPR), pages1809–1814. IEEE, 2018.
[56]Martin Danelljan, Goutam Bhat, Fahad Shahbaz Khan, and Michael Felsberg. Eco: efficient convolutionoperators for tracking. InProceedings of the IEEE conference on computer vision and pattern recognition, pages6638–6646, 2017.
[57]Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. Ininternational Conferenceon computer vision & Pattern Recognition (CVPR’05), volume 1, pages 886–893. IEEE Computer Society, 2005.
[58]Joost Van De Weijer, Cordelia Schmid, Jakob Verbeek, and Diane Larlus. Learning color names for real-worldapplications.IEEE Transactions on Image Processing, 18(7):1512–1523, 2009.
[59]Yongyi Lu, Cewu Lu, and Chi-Keung Tang. Online video object detection using association lstm. InProceedingsof the IEEE International Conference on Computer Vision, pages 2344–2352, 2017.
[60]Hilke Kieritz, Wolfgang Hubner, and Michael Arens. Joint detection and online multi-object tracking. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1459–1467,2018.
[61]Dawei Zhao, Hao Fu, Liang Xiao, Tao Wu, and Bin Dai. Multi-object tracking with correlation filter forautonomous vehicle.Sensors, 18(7):2004, 2018.
[62]Karl Pearson. Liii. on lines and planes of closest fit to systems of points in space.The London, Edinburgh, andDublin Philosophical Magazine and Journal of Science, 2(11):559–572, 1901.
[63]Mengmeng Wang, Yong Liu, and Zeyi Huang. Large margin object tracking with circulant feature maps. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4021–4029, 2017.
[64]Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time objectdetection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788,2016.
[65]Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement.arXiv preprint arXiv:1804.02767, 2018.
[66]Sang Jun Kim, Jae-Yeal Nam, and Byoung Chul Ko. Online tracker optimization for multi-pedestrian trackingusing a moving vehicle camera.IEEE Access, 6:48675–48687, 2018.
[67]Sarthak Sharma, Junaid Ahmed Ansari, J Krishna Murthy, and K Madhava Krishna. Beyond pixels: Leveraginggeometry and shape cues for online multi-object tracking. In2018 IEEE International Conference on Roboticsand Automation (ICRA), pages 3508–3515. IEEE, 2018.
[68]Jimmy Ren, Xiaohao Chen, Jianbo Liu, Wenxiu Sun, Jiahao Pang, Qiong Yan, Yu-Wing Tai, and Li Xu. Accuratesingle stage detector using recurrent rolling convolution. InProceedings of the IEEE Conference on ComputerVision and Pattern Recognition, pages 5420–5428, 2017.
[69]Yu Xiang, Wongun Choi, Yuanqing Lin, and Silvio Savarese. Subcategory-aware convolutional neural networksfor object proposals and detection. In2017 IEEE winter conference on applications of computer vision (WACV),pages 924–933. IEEE, 2017.
[70]Federico Pernici, Federico Bartoli, Matteo Bruni, and Alberto Del Bimbo. Memory based online learning of deeprepresentations from video streams. InProceedings of the IEEE Conference on Computer Vision and PatternRecognition, pages 2324–2334, 2018.
[71]Peiyun Hu and Deva Ramanan. Finding tiny faces. InProceedings of the IEEE conference on computer visionand pattern recognition, pages 951–959, 2017.
[72]Weidong Min, Mengdan Fan, Xiaoguang Guo, and Qing Han. A new approach to track multiple vehicles withthe combination of robust detection and two classifiers.IEEE Transactions on Intelligent Transportation Systems,19(1):174–186, 2018.
[73]Olivier Barnich and Marc Van Droogenbroeck. Vibe: A universal background subtraction algorithm for videosequences.IEEE Transactions on Image processing, 20(6):1709–1724, 2011.
[74] Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine learning, 20(3):273–297, 1995.
[75]Shaoyong Yu, Yun Wu, Wei Li, Zhijun Song, and Wenhua Zeng. A model for fine-grained vehicle classificationbased on deep learning.Neurocomputing, 257:97–103, 2017.
[76]Sebastian Bullinger, Christoph Bodensteiner, and Michael Arens. Instance flow based online multiple objecttracking. In2017 IEEE International Conference on Image Processing (ICIP), pages 785–789. IEEE, 2017.
[77] Jifeng Dai, Kaiming He, and Jian Sun. Instance-aware semantic segmentation via multi-task network cascades.InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3150–3158, 2016.
[78]Gunnar Farnebäck. Two-frame motion estimation based on polynomial expansion. InScandinavian conferenceon Image analysis, pages 363–370. Springer, 2003.
[79]Jerome Revaud, Philippe Weinzaepfel, Zaid Harchaoui, and Cordelia Schmid. Deepmatching: Hierarchicaldeformable dense matching.International Journal of Computer Vision, 120(3):300–323, 2016.
[80]Yinlin Hu, Rui Song, and Yunsong Li. Efficient coarse-to-fine patchmatch for large displacement optical flow. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5704–5712, 2016.
[81]Li Wang, Nam Trung Pham, Tian-Tsong Ng, Gang Wang, Kap Luk Chan, and Karianto Leman. Learningdeep features for multiple object tracking by using a multi-task learning strategy. In2014 IEEE InternationalConference on Image Processing (ICIP), pages 838–842. IEEE, 2014.
[82]Charles Cadieu and Bruno A Olshausen. Learning transformational invariants from natural movies. InAdvancesin neural information processing systems, pages 209–216, 2009.
[83]Chanho Kim, Fuxin Li, Arridhana Ciptadi, and James M Rehg. Multiple hypothesis tracking revisited. InProceedings of the IEEE International Conference on Computer Vision, pages 4696–4704, 2015.
[84]Liang Zheng, Hengheng Zhang, Shaoyan Sun, Manmohan Chandraker, Yi Yang, and Qi Tian. Person re-identification in the wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 1367–1376, 2017.
[85]Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qi Tian. Scalable person re-identification: A benchmark. InProceedings of the IEEE International Conference on Computer Vision,pages 1116–1124, 2015.
[86]Douglas Gray and Hai Tao. Viewpoint invariant pedestrian recognition with an ensemble of localized features.InEuropean conference on computer vision, pages 262–275. Springer, 2008.
[87]Wei Li, Rui Zhao, Tong Xiao, and Xiaogang Wang. Deepreid: Deep filter pairing neural network for personre-identification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages152–159, 2014.
[88]Jiahui Chen, Hao Sheng, Yang Zhang, and Zhang Xiong. Enhancing detection model for multiple hypothesistracking. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages18–27, 2017.
[89]Min Yang, Yuwei Wu, and Yunde Jia. A hybrid data association framework for robust online multi-objecttracking.IEEE Transactions on Image Processing, 26(12):5667–5679, 2017.
[90]Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Region-based convolutional networks foraccurate object detection and segmentation.IEEE transactions on pattern analysis and machine intelligence,38(1):142–158, 2015.
91]Shuo Hong Wang, Jing Wen Zhao, and Yan Qiu Chen. Robust tracking of fish schools using cnn for headidentification.Multimedia Tools and Applications, 76(22):23679–23697, 2017.
[92] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks.arXiv preprint arXiv:1605.07146, 2016.
[93]Chanho Kim, Fuxin Li, and James M Rehg. Multi-object tracking with neural gating using bilinear lstm. InProceedings of the European Conference on Computer Vision (ECCV), pages 200–215, 2018.
[94]Seung-Hwan Bae and Kuk-Jin Yoon. Confidence-based data association and discriminative deep appearancelearning for robust online multi-object tracking.IEEE transactions on pattern analysis and machine intelligence,40(3):595–610, 2017.
[95]Mohib Ullah and Faouzi Alaya Cheikh. Deep feature based end-to-end transportation network for multi-targettracking. In2018 25th IEEE International Conference on Image Processing (ICIP), pages 3738–3742. IEEE,2018.
[96]Kuan Fang, Yu Xiang, Xiaocheng Li, and Silvio Savarese. Recurrent autoregressive networks for online multi-object tracking. In2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 466–475.IEEE, 2018.
[97]Tong Xiao, Hongsheng Li, Wanli Ouyang, and Xiaogang Wang. Learning deep feature representations withdomain guided dropout for person re-identification. InProceedings of the IEEE conference on computer visionand pattern recognition, pages 1249–1258, 2016.
[98]Zeyu Fu, Federico Angelini, Syed Mohsen Naqvi, and Jonathon A Chambers. Gm-phd filter based onlinemultiple human tracking using deep discriminative correlation matching. In2018 IEEE International Conferenceon Acoustics, Speech and Signal Processing (ICASSP), pages 4299–4303. IEEE, 2018.
[99]B-N Vo and W-K Ma. The gaussian mixture probability hypothesis density filter.IEEE Transactions on signalprocessing, 54(11):4091–4104, 2006.
[100]Longyin Wen, Dawei Du, Shengkun Li, Xiao Bian, and Siwei Lyu. Learning non-uniform hypergraph formulti-object tracking.Thirty-Third AAAI Conference on Artificial Intelligence, 2019.
[101]Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, An-drej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015.
[102]Flip Korn and Suresh Muthukrishnan. Influence sets based on reverse nearest neighbor queries.ACM SigmodRecord, 29(2):201–212, 2000.
[103]Hao Sheng, Yang Zhang, Jiahui Chen, Zhang Xiong, and Jun Zhang. Heterogeneous association graph fusion fortarget association in multiple object tracking.IEEE Transactions on Circuits and Systems for Video Technology,2018.
[104]Longtao Chen, Xiaojiang Peng, and Mingwu Ren. Recurrent metric networks and batch multiple hypothesis formulti-object tracking.IEEE Access, 7:3093–3105, 2019.
[105]Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, Peter V Gehler, andBernt Schiele. Deepcut: Joint subset partition and labeling for multi person pose estimation. InProceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition, pages 4929–4937, 2016.
[106]Minyoung Kim, Stefano Alletto, and Luca Rigazio. Similarity mapping with enhanced siamese network for multi-object tracking. InMachine Learning for Intelligent Transportation Systems (MLITS), 2016 NIPS Workshop,2016.
[107]Jane Bromley, Isabelle Guyon, Yann LeCun, Eduard Säckinger, and Roopak Shah. Signature verification usinga" siamese" time delay neural network. InAdvances in neural information processing systems, pages 737–744,1994.
[108]Bing Wang, Li Wang, Bing Shuai, Zhen Zuo, Ting Liu, Kap Luk Chan, and Gang Wang. Joint learning ofconvolutional neural networks and temporally constrained metrics for tracklet association. InProceedings of theIEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1–8, 2016.
[109]Shun Zhang, Yihong Gong, Jia-Bin Huang, Jongwoo Lim, Jinjun Wang, Narendra Ahuja, and Ming-Hsuan Yang.Tracking persons-of-interest via adaptive discriminative features. InEuropean conference on computer vision,pages 415–433. Springer, 2016.
[110]Laura Leal-Taixé, Cristian Canton-Ferrer, and Konrad Schindler. Learning by tracking: Siamese cnn forrobust target association. InProceedings of the IEEE Conference on Computer Vision and Pattern RecognitionWorkshops, pages 33–40, 2016.
[111] Laura Leal-Taixé, Gerard Pons-Moll, and Bodo Rosenhahn. Everybody needs somebody: Modeling social andgrouping behavior on a linear programming multiple people tracker. In2011 IEEE international conference oncomputer vision workshops (ICCV workshops), pages 120–127. IEEE, 2011.
[112]Jeany Son, Mooyeol Baek, Minsu Cho, and Bohyung Han. Multi-object tracking with quadruplet convolutionalneural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages5620–5629, 2017.
[113]Andrii Maksai and Pascal Fua. Eliminating exposure bias and loss-evaluation mismatch in multiple objecttracking.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
[114]Alexander Hermans, Lucas Beyer, and Bastian Leibe. In defense of the triplet loss for person re-identification.arXiv preprint arXiv:1703.07737, 2017.
[115]Ji Zhu, Hua Yang, Nian Liu, Minyoung Kim, Wenjun Zhang, and Ming-Hsuan Yang. Online multi-objecttracking with dual matching attention networks. InProceedings of the European Conference on Computer Vision(ECCV), pages 366–382, 2018.
[116]Cong Ma, Changshui Yang, Fan Yang, Yueqing Zhuang, Ziwei Zhang, Huizhu Jia, and Xiaodong Xie. Trajectoryfactory: Tracklet cleaving and re-connection by deep siamese bi-gru for multiple object tracking. In2018 IEEEInternational Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2018.
[117]Hui Zhou, Wanli Ouyang, Jian Cheng, Xiaogang Wang, and Hongsheng Li. Deep continuous conditional randomfields with asymmetric inter-object constraints for online multi-object tracking.IEEE Transactions on Circuitsand Systems for Video Technology, 2018.
[118]Chen Long, Ai Haizhou, Zhuang Zijie, and Shang Chong. Real-time multiple people tracking with deeplylearned candidate selection and person re-identification. InICME, 2018.
[119]Sangyun Lee and Euntai Kim. Multiple object tracking via feature pyramid siamese networks.IEEE Access,7:8181–8194, 2019.
[120]Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer.Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size.arXiv preprintarXiv:1602.07360, 2016.
[121]Mohib Ullah, Ahmed Kedir Mohammed, Faouzi Alaya Cheikh, and Zhaohui Wang. A hierarchical feature modelfor multi-target tracking. In2017 IEEE International Conference on Image Processing (ICIP), pages 2612–2616.IEEE, 2017.
[122]Stéphane G Mallat and Zhifeng Zhang. Matching pursuits with time-frequency dictionaries.IEEE Transactionson signal processing, 41(12):3397–3415, 1993.
[123]Amir Sadeghian, Alexandre Alahi, and Silvio Savarese. Tracking the untrackable: Learning to track multiplecues with long-term dependencies. InProceedings of the IEEE International Conference on Computer Vision,pages 300–311, 2017.
[124]Qi Chu, Wanli Ouyang, Hongsheng Li, Xiaogang Wang, Bin Liu, and Nenghai Yu. Online multi-object trackingusing cnn-based single object tracker with spatial-temporal attention mechanism. InProceedings of the IEEEInternational Conference on Computer Vision, pages 4836–4845, 2017.
[125]Mustafa Ozuysal, Michael Calonder, Vincent Lepetit, and Pascal Fua. Fast keypoint recognition using randomferns.IEEE transactions on pattern analysis and machine intelligence, 32(3):448–461, 2009.
[126]Mohib Ullah and Faouzi Alaya Cheikh. A directed sparse graphical model for multi-target tracking. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1816–1823,2018.
[127]Lawrence R Rabiner and Biing-Hwang Juang. An introduction to hidden markov models.ieee assp magazine,3(1):4–16, 1986.
[128]Lu Wang, Lisheng Xu, Min Young Kim, Luca Rigazico, and Ming-Hsuan Yang. Online multiple object trackingvia flow and convolutional features. In2017 IEEE International Conference on Image Processing (ICIP), pages3630–3634. IEEE, 2017.
[129]Chao Ma, Jia-Bin Huang, Xiaokang Yang, and Ming-Hsuan Yang. Hierarchical convolutional features for visualtracking. InProceedings of the IEEE international conference on computer vision, pages 3074–3082, 2015.
[130]Bruce D. Lucas and Takeo Kanade. An iterative image registration technique with an application to stereo vision.InProceedings of Imaging Understanding Workshop, pages 121–130. Vancouver, British Columbia, 1981.
[131]Pol Rosello and Mykel J Kochenderfer. Multi-agent reinforcement learning for multi-object tracking. InProceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, pages1397–1404. International Foundation for Autonomous Agents and Multiagent Systems, 2018.
[132]Maryam Babaee, Zimu Li, and Gerhard Rigoll. Occlusion handling in tracking multiple people using rnn. In2018 25th IEEE International Conference on Image Processing (ICIP), pages 2715–2719. IEEE, 2018.
[133]Anton Milan, S Hamid Rezatofighi, Anthony Dick, Ian Reid, and Konrad Schindler. Online multi-target trackingusing recurrent neural networks. InThirty-First AAAI Conference on Artificial Intelligence, 2017.
[134]Yu Xiang, Alexandre Alahi, and Silvio Savarese. Learning to track: Online multi-object tracking by decisionmaking. InProceedings of the IEEE international conference on computer vision, pages 4705–4713, 2015.
[135]Hao-Shu Fang, Shuqin Xie, Yu-Wing Tai, and Cewu Lu. Rmpe: Regional multi-person pose estimation. InProceedings of the IEEE International Conference on Computer Vision, pages 2334–2343, 2017.
[136]Yiming Liang and Yue Zhou. Lstm multiple object tracker combining multiple cues. In2018 25th IEEEInternational Conference on Image Processing (ICIP), pages 2351–2355. IEEE, 2018.
[137]Sanping Zhou, Jinjun Wang, Deyu Meng, Xiaomeng Xin, Yubing Li, Yihong Gong, and Nanning Zheng. Deepself-paced learning for person re-identification.Pattern Recognition, 76:739–751, 2018.
[138]Kwangjin Yoon, Du Yong Kim, Young-Chul Yoon, and Moongu Jeon. Data association for multi-object trackingvia deep neural networks.Sensors, 19(3):559, 2019.
[139]Alexandre Robicquet, Amir Sadeghian, Alexandre Alahi, and Silvio Savarese. Learning social etiquette: Humantrajectory understanding in crowded scenes. InEuropean conference on computer vision, pages 549–565.Springer, 2016.
[140]Mykhaylo Andriluka, Stefan Roth, and Bernt Schiele. People-tracking-by-detection and people-detection-by-tracking. In2008 IEEE Conference on computer vision and pattern recognition, pages 1–8. IEEE, 2008.
[141]Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neuralmachine translation: Encoder-decoder approaches.arXiv preprint arXiv:1409.1259, 2014.
[142]Bjoern Andres, Andrea Fuksová, and Jan-Hendrik Lange. Lifting of multicuts.CoRR, abs/1503.03791, 3, 2015.
[143]Philippe Weinzaepfel, Jerome Revaud, Zaid Harchaoui, and Cordelia Schmid. Deepflow: Large displacementoptical flow with deep matching. InProceedings of the IEEE International Conference on Computer Vision,pages 1385–1392, 2013.
[144]Margret Keuper, Evgeny Levinkov, Nicolas Bonneel, Guillaume Lavoué, Thomas Brox, and Bjorn Andres.Efficient decomposition of image and mesh graphs by lifted multicuts. InProceedings of the IEEE InternationalConference on Computer Vision, pages 1751–1759, 2015.
[145]Long Chen, Haizhou Ai, Chong Shang, Zijie Zhuang, and Bo Bai. Online multi-object tracking with convolutionalneural networks. In2017 IEEE International Conference on Image Processing (ICIP), pages 645–649. IEEE,2017.
[146]M Sanjeev Arulampalam, Simon Maskell, Neil Gordon, and Tim Clapp. A tutorial on particle filters for onlinenonlinear/non-gaussian bayesian tracking.IEEE Transactions on signal processing, 50(2):174–188, 2002.
[147]Ricardo Sanchez-Matilla, Fabio Poiesi, and Andrea Cavallaro. Online multi-target tracking with strong and weakdetections. InEuropean Conference on Computer Vision, pages 84–99. Springer, 2016.
[148]Liqian Ma, Siyu Tang, Michael J. Black, and Luc Van Gool. Customized multi-person tracker. InComputerVision – ACCV 2018. Springer International Publishing, December 2018.
[149]Siyu Tang, Bjoern Andres, Mykhaylo Andriluka, and Bernt Schiele. Multi-person tracking by multicut and deepmatching. InEuropean Conference on Computer Vision, pages 100–111. Springer, 2016.
[150]Liangliang Ren, Jiwen Lu, Zifeng Wang, Qi Tian, and Jie Zhou. Collaborative deep reinforcement learning formulti-object tracking. InProceedings of the European Conference on Computer Vision (ECCV), pages 586–602,2018.
[151]Hyeonseob Nam and Bohyung Han. Learning multi-domain convolutional neural networks for visual tracking.InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4293–4302, 2016.
[152]Yifan Jiang, Hyunhak Shin, and Hanseok Ko. Precise regression for bounding box correction for improvedtracking based on deep reinforcement learning. In2018 IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), pages 1643–1647. IEEE, 2018.
[153]Byungjae Lee, Enkhbayar Erdenee, Songguo Jin, Mi Young Nam, Young Giu Jung, and Phill Kyu Rhee. Multi-class multi-object tracking using changing point detection. InEuropean Conference on Computer Vision, pages68–83. Springer, 2016.
[154]Anthony Hoak, Henry Medeiros, and Richard Povinelli. Image-based multi-target tracking through multi-bernoulli filtering with interactive likelihoods.Sensors, 17(3):501, 2017.
[155]Roberto Henschel, Laura Leal-Taixé, Daniel Cremers, and Bodo Rosenhahn. Fusion of head and full-bodydetectors for multi-object tracking. InProceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops, pages 1428–1437, 2018.
[156]Russell Stewart, Mykhaylo Andriluka, and Andrew Y Ng. End-to-end people detection in crowded scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2325–2333, 2016.
[157]Weihao Gan, Shuo Wang, Xuejing Lei, Ming-Sui Lee, and C-C Jay Kuo. Online cnn-based multiple objecttracking with enhanced model updates and identity association.Signal Processing: Image Communication,66:95–102, 2018.
[158]Jun Xiang, Guoshuai Zhang, and Jianhua Hou. Online multi-object tracking based on feature representation andbayesian filtering within a deep learning architecture.IEEE Access, 2019.
[159]Peng Chu, Heng Fan, Chiu C Tan, and Haibin Ling. Online multi-object tracking with instance-aware trackerand dynamic model refreshment. In2019 IEEE Winter Conference on Applications of Computer Vision (WACV),pages 161–170. IEEE, 2019.
[160]Christopher John Cornish Hellaby Watkins.Learning from delayed rewards. PhD thesis, King’s College,Cambridge, 1989.
[161]Jun-ichi Takeuchi and Kenji Yamanishi. A unifying framework for detecting outliers and change points fromtime series.IEEE transactions on Knowledge and Data Engineering, 18(4):482–492, 2006.
[162]Piotr Dollar, Christian Wojek, Bernt Schiele, and Pietro Perona. Pedestrian detection: A benchmark. In2009IEEE Conference on Computer Vision and Pattern Recognition, pages 304–311. IEEE, 2009.
[163]Reza Hoseinnezhad, Ba-Ngu Vo, Ba-Tuong Vo, and David Suter. Visual tracking of numerous targets viamulti-bernoulli filtering of image data.Pattern Recognition, 45(10):3625–3635, 2012.
[164]Anton Milan, Rikke Gade, Anthony Dick, Thomas B Moeslund, and Ian Reid. Improving global multi-targettracking with local updates. InEuropean Conference on Computer Vision, pages 174–190. Springer, 2014.
[165]Marguerite Frank and Philip Wolfe. An algorithm for quadratic programming.Naval research logistics quarterly,3(1-2):95–110, 1956.
[166]Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using partaffinity fields. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages7291–7299, 2017.
[167]Liming Zhao, Xi Li, Yueting Zhuang, and Jingdong Wang. Deeply-learned part-aligned representations forperson re-identification. InProceedings of the IEEE International Conference on Computer Vision, pages3219–3228, 2017.
[168]João F Henriques, Rui Caseiro, Pedro Martins, and Jorge Batista. High-speed tracking with kernelized correlationfilters.IEEE transactions on pattern analysis and machine intelligence, 37(3):583–596, 2014.
[169]Longyin Wen, Wenbo Li, Junjie Yan, Zhen Lei, Dong Yi, and Stan Z Li. Multiple target tracking based onundirected hierarchical relation hypergraph. InProceedings of the IEEE Conference on Computer Vision andPattern Recognition, pages 1282–1289, 2014.
[170]Zhi-Ming Qian, Xi En Cheng, and Yan Qiu Chen. Automatically detect and track multiple fish swimming inshallow water with frequent occlusion.PloS one, 9(9):e106506, 2014.
[171]Hamed Pirsiavash, Deva Ramanan, and Charless C Fowlkes. Globally-optimal greedy algorithms for tracking avariable number of objects. InCVPR 2011, pages 1201–1208. IEEE, 2011.
[172]Steven Gold, Anand Rangarajan, et al. Softmax to softassign: Neural network algorithms for combinatorialoptimization.Journal of Artificial Neural Networks, 2(4):381–399, 1996.
[173]Chang Huang, Bo Wu, and Ramakant Nevatia. Robust object tracking by hierarchical association of detectionresponses. InEuropean Conference on Computer Vision, pages 788–801. Springer, 2008.
[174]Rodrigo Benenson, Markus Mathias, Radu Timofte, and Luc Van Gool. Pedestrian detection at 100 frames persecond. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 2903–2910. IEEE, 2012.