Python 3爬虫网易云(八)—— 对网易云歌词的爬取
今天开始正式的网易云爬虫的实战吧,今天先做一个非常简单的小例子,但是稍微有一点小弯绕。在这之前,想必大家也用爬虫爬过妹子图和百度贴吧入门爬虫了。
好,那么先打开网易云中的一首歌(这里以火狐浏览器为例)
分析网页内容,找到入口
根据以往的经验,大家可能首先会想到直接把这个网页的源码下载下来,然后再提取出其中的歌词就可以了。这种方法在我们处理百度贴吧的帖子或者百科里的段子都是十分简单方便有效的,但是当你用这种方法去爬取的时候,你会发现得到的结果不是一个有效的html文档。
import requests
url = 'http://music.163.com/#/song?id=27566765'
r = requests.get(url)
print(r.text)结果如下
<html>
<head>
<meta charset="utf-8">
<meta name="baidu-site-verification" content="cNhJHKEzsD" />
<meta property="qc:admins" content="27354635321361636375" />
<link rel="canonical" href="//music.163.com/">
<meta name="applicable-device" content="pc,mobile">
<title>网易云音乐title>
<meta name="keywords" content="网易云音乐,音乐,播放器,网易,下载,播放,DJ,免费,明星,精选,歌单,识别音乐,收藏,分享音乐,音乐互动,高音质,320K,音乐社交,官网,music.163.com" />
...... #省略中间部分
html>很容易发现当中并不包含我们想要的歌词部分,里面很多是var这种JS的关键字,对我们没有意义。
那么现在我们需要找歌词内容的入口,找抓取的链接。
我们可以先抓包,运用浏览器中F12(检查元素)来看一下它网页的请求过程,F5刷新一下,可以看到所有的请求。
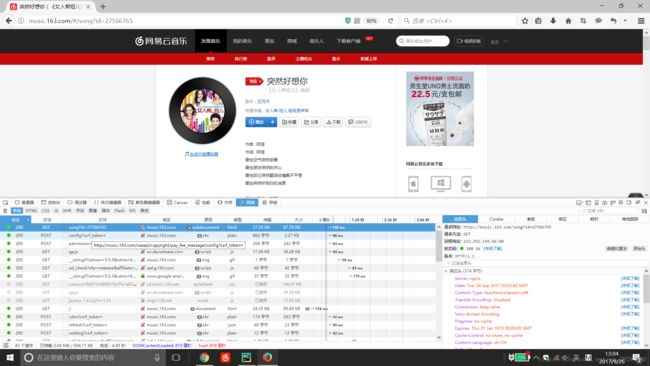
找到状态为200的请求为POST和GET的类型,
查看具体的响应,可以发现链接为http://music.163.com/song?id=27566765的响应是网页实际的源代码,这和我们刚开始爬取的链接比较你会发现这个链接少了一个#号,在网易云音乐中,不管是抓歌词,歌单,专辑都要把#去掉才能获得我们想要的内容,带#的是假链接。
然后可以找到POST请求中请求网址为http://music.163.com/weapi/song/lyric?csrf_token= 有我们需要的歌词内容。
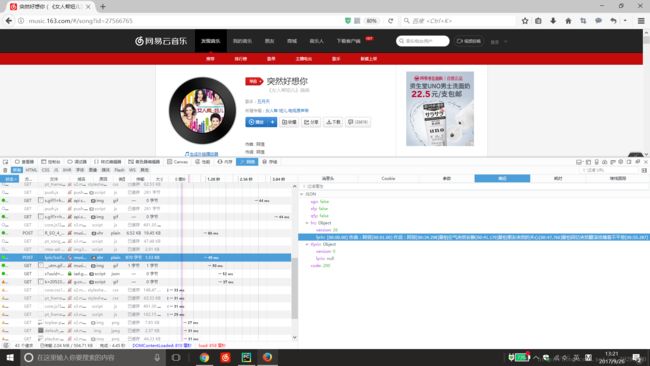
这里需要用到token验证,需要传入这两个参数:params和encSecKey
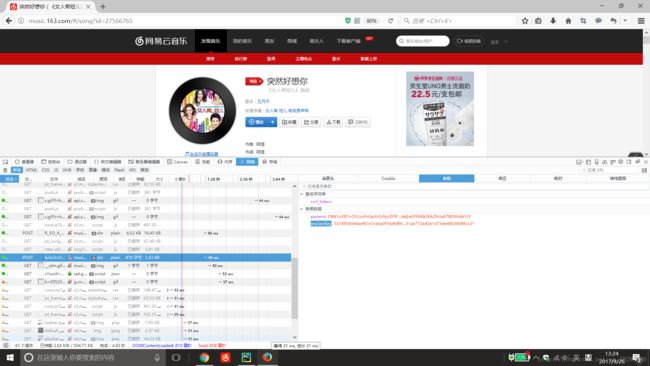
这里验证比较麻烦(以后的爬虫再进行涉及,这里先跳过),博主找到一个简单的方法可以绕过token验证。
从其他渠道获得的一个网址
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + str()+ '&lv=1&kv=1&tv=-1' #括号中填入歌曲id我们先看看传出什么东西
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + str(27566765)+ '&lv=1&kv=1&tv=-1'
r = requests.get(url)
print(r.text)结果如下
{"sgc":false,"sfy":false,"qfy":false,"lrc":{"version":26,"lyric":"[00:00.00] 作曲 : 阿信\n[00:01.00] 作词 : 阿信\n[00:34.298]最怕空气突然安静\n[00:41.170]最怕朋友突然的关心\n[00:47.760]最怕回忆突然翻滚绞痛着不平息\n[00:55.287]最怕突然听到你的消息\n[01:01.187]\n[01:01.696]想念如果会有声音\n[01:08.696]不愿那是悲伤的哭泣\n[01:15.496]事到如今终於让自已属於我自已\n[01:21.846]只剩眼泪还骗不过自己\n[01:27.760]\n[01:29.187]突然好想你你会在哪里\n[01:35.806]过的快乐或委屈\n[01:43.579]突然好想你突然锋利的回忆\n[01:50.987]突然模糊的眼睛\n[01:56.926]\n[01:57.796]我们像一首最美丽的歌曲\n[02:03.997]变成两部悲伤的电影\n[02:11.790]为什麽你带我走过最难忘的旅行\n[02:18.379]然後留下最痛的纪念品\n[02:26.400]\n[02:52.300]我们那麽甜那麽美那麽相信\n[02:57.570]那麽疯那麽热烈的曾经\n[03:01.770]为何我们还是要奔向\n[03:04.730]各自的幸福和遗憾中老去\n[03:09.360]\n[03:09.920]突然好想你你会在哪里\n[03:16.160]过的快乐或委屈\n[03:23.100]突然好想你突然锋利的回忆\n[03:29.980]突然模糊的眼睛\n[03:36.700]\n[03:37.600]最怕空气突然安静\n[03:43.940]最怕朋友突然的关心\n[03:50.000]最怕回忆突然翻滚绞痛着不平息\n[03:57.070]最怕突然听到你的消息\n[04:04.100]最怕此生已经决定自己过\n[04:10.390]没有你却又突然听到你的消息\n[04:22.200]\n"},"klyric":{"version":0},"tlyric":{"version":0,"lyric":null},"code":200}我们看到返回了一整串json格式,格式不太清晰,我们可以利用json格式化一下。
可以利用json在线格式化工具
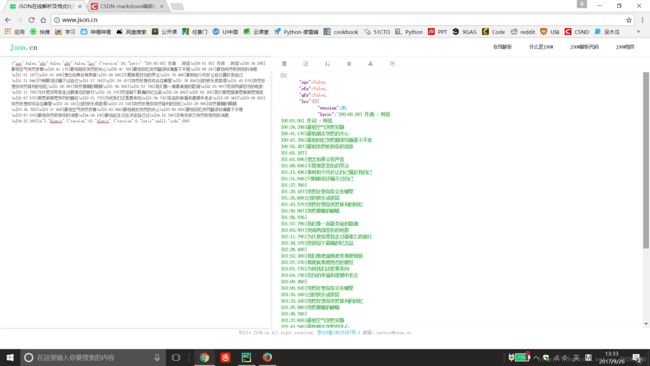
我们可以看到需要的是lrc里面的lyric里的内容
然后我们在Python中导入json模块
把内容转换为字典
关于json的操作我们前面已经介绍过了
好了,具体的代码如下
import requests
import json
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + str(27566765)+ '&lv=1&kv=1&tv=-1'
r = requests.get(url)
json_obj = r.text
j = json.loads(json_obj)
print(j['lrc']['lyric'])运行结果
[00:00.00] 作曲 : 阿信
[00:01.00] 作词 : 阿信
[00:34.298]最怕空气突然安静
[00:41.170]最怕朋友突然的关心
[00:47.760]最怕回忆突然翻滚绞痛着不平息
[00:55.287]最怕突然听到你的消息
[01:01.187]
[01:01.696]想念如果会有声音
[01:08.696]不愿那是悲伤的哭泣
[01:15.496]事到如今终於让自已属於我自已
[01:21.846]只剩眼泪还骗不过自己
[01:27.760]
[01:29.187]突然好想你你会在哪里
[01:35.806]过的快乐或委屈
[01:43.579]突然好想你突然锋利的回忆
[01:50.987]突然模糊的眼睛
[01:56.926]
[01:57.796]我们像一首最美丽的歌曲
[02:03.997]变成两部悲伤的电影
[02:11.790]为什麽你带我走过最难忘的旅行
[02:18.379]然後留下最痛的纪念品
[02:26.400]
[02:52.300]我们那麽甜那麽美那麽相信
[02:57.570]那麽疯那麽热烈的曾经
[03:01.770]为何我们还是要奔向
[03:04.730]各自的幸福和遗憾中老去
[03:09.360]
[03:09.920]突然好想你你会在哪里
[03:16.160]过的快乐或委屈
[03:23.100]突然好想你突然锋利的回忆
[03:29.980]突然模糊的眼睛
[03:36.700]
[03:37.600]最怕空气突然安静
[03:43.940]最怕朋友突然的关心
[03:50.000]最怕回忆突然翻滚绞痛着不平息
[03:57.070]最怕突然听到你的消息
[04:04.100]最怕此生已经决定自己过
[04:10.390]没有你却又突然听到你的消息
[04:22.200]这样我们就爬取好一首歌的歌词啦