CentOS7 + Hadoop 3.2.0集群搭建
目录
集群规划
准备工作
Hadoop安装
主节点配置相关
从节点配置相关
启动集群
web端监控
集群规划
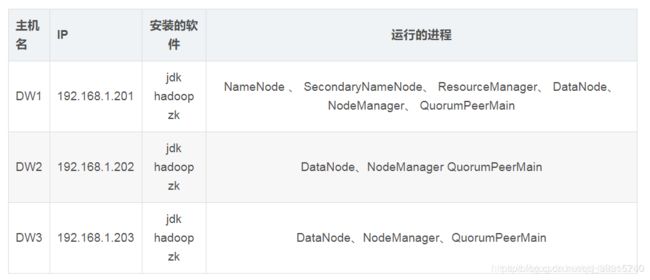
节省机器的规划
架构清晰的规划
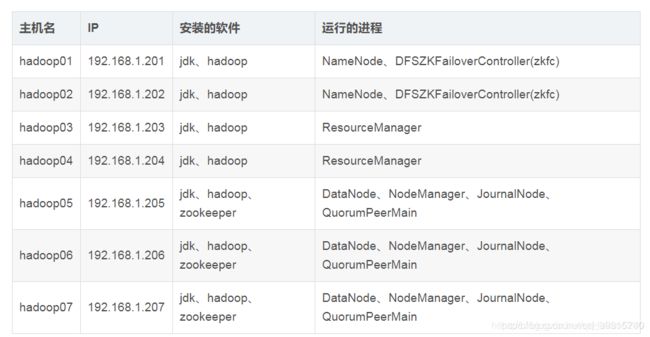
分析之后,学习阶段决定采用第一种集群规划,节省机器与资源。
因此我们在三台虚拟机的基础上,搭建一主二从的伪分布式集群。
关于虚拟机环境搭建,可以看我的另一篇博客:Windows10 / Ubuntu16.04下使用VirtualBox搭建CentOS7虚拟环境.
准备工作
关闭防火墙
[root@DW1 ~]# systemctl stop firewalld.service
[root@DW1 ~]# systemctl disable firewalld.service
[root@DW1 ~]# firewall-cmd --state
not running
关闭SELINUX
# 修改为SELINUX=disabled
[root@DW1 ~]# vi etc/selinux/config
# 重启完成设置
[root@DW1 ~]# reboot
安装JDK
详细安装过程请看我的另一篇博客:CentOS7安装JDK1.8.0
建立ip与主机名的联系
vi /etc/hosts
# 添加内容
192.168.xx.xxx DW1
192.168.xx.xxx DW2
192.168.xx.xxx DW3
#添加完成后可以以DWX代替ip地址,如:
[root@DW1 ~]# ping DW2
配置SSH
# 通过ssh工具获取公匙密匙
[root@DW1 ~]$ ssh-keygen -t rsa
# 进行ssh搭建
[root@DW1 ~]$ cd .ssh
[root@DW1 ~]$ cp id_rsa.pub authorized_keys
[root@DW1 ~]$ ssh-copy-id dw2
[root@DW1 ~]$ ssh-copy-id dw3
# 这时dw2和dw3已可以对dw1免密码登录
[root@DW1 ~]$ ssh dw2
[root@DW1 ~]$ ssh dw3
#对DW2,DW3也进行相同地操作,保证3台设备可以免密互联
Hadoop安装
在/usr/local/创建下创建hadoop目录
[root@DW1 ~]# cd /usr/local
[root@DW1 ~]# mkdir hadoop
[root@DW1 ~]# cd hadoop
下载安装包并解压
[root@DW1 hadoop]# wget http://apache.claz.org/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
[root@DW1 hadoop]# tar -xzvf hadoop-3.2.0.tar.gz
设置环境变量
[root@DW1 ~]# vi /etc/profile
# 添加以下内容
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.0
exprot PATH=$PATH:$HADOOP_HOME/bin
[root@DW1 ~]# source /etc/profile
安装检验
[root@DW1 hadoop]# hadoop version
Hadoop 3.2.0
Source code repository https://github.com/apache/hadoop.git -r e97acb3bd8f3befd27418996fa5d4b50bf2e17bf
Compiled by sunilg on 2019-01-08T06:08Z
Compiled with protoc 2.5.0
From source with checksum d3f0795ed0d9dc378e2c785d3668f39
This command was run using /usr/local/hadoop/hadoop-3.2.0/share/hadoop/common/hadoop-common-3.2.0.jar
主节点配置相关
core-site.xml
[root@DW1 hadoop-3.2.0]$ cd etc/hadoop
[root@DW1 hadoop]# vi core-site.xml
#在最后添加以下内容
fs.default.name
hdfs://DW1:9000
hdfs-site.xml
DW1为主节点,DW2、3为从节点,因此设置两个副本:
[root@DW1 hadoop]# vi hdfs-site.xml
#在最后添加以下内容
dfs.name.dir
/usr/local/data/namenode
dfs.data.dir
/usr/local/data/datanode
dfs.tmp.dir
/usr/local/data/tmp
dfs.replication
2
mapred-site.xml
mapreduce.framework.name
yarn
yarn-site.xml
yarn.resourcemanager.hostname
DW1
yarn.nodemanager.aux-services
mapreduce_shuffle
works(slaves)
注意hadoop 3.0以后没有slaves文件了,均以works代替。
[root@DW1 hadoop-3.2.0]$ vi slaves
# 添加从节点DW2,DW3(删除默认的localhost)
DW2
DW3
hadoop-env.sh脚本
# 添加JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64
yarn-env.sh脚本
# 添加JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64
从节点相关配置
创建data文件夹
# 在三个节点的/usr/local/路径下创建data文件夹
[root@DW1 local]# mkdir data
将DW1的hadoop分发到DW2,DW3
这样相当于我们对DW2,DW3也一并做了上面的配置,而不用逐个节点进行配置。
当然,不要忘记DW2,DW3的环境变量也要做相应的配置。
[root@DW1 local]# scp -r hadoop DW2:/usr/local
[root@DW1 local]# scp -r hadoop DW3:/usr/local
对DW2,DW3进行验证
#进行检验v
[root@DW2 local]# hadoop version
[root@DW3 local]# hadoop version
启动集群
节点初始化
# 在DW1上进行节点初始化
[root@DW1 ~]# hdfs namenode -format
启动
# 在主节点DW1上启动集群
[root@DW1 ~]# start-dfs.sh
结果遇到以下问题:
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [DW1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
在/usr/local/hadoop/hadoop-3.2.0/sbin下, 将start-dfs.sh和stop-dfs.sh两个文件顶部添加以下参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh和stop-yarn.sh的顶部添加以下参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
完成后再次启动集群:
[root@DW1 ~]# start-dfs.sh
# 主节点
[root@DW1 ~]# jps
15289 NameNode
15593 SecondaryNameNode
15711 Jps
# 从节点
[root@DW2 ~]# jps
8410 DataNode
8507 Jps
web端监控
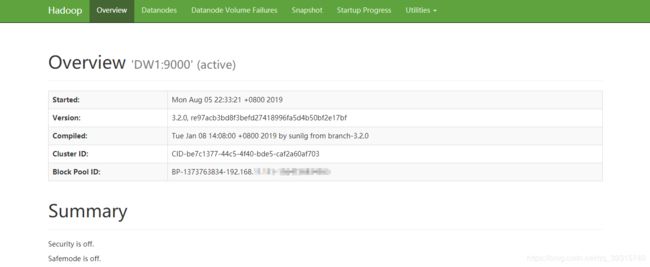
开启集群后,我们可以在浏览器输入192.168.XX.XXX:9870监控Hadoop。
注意不是50070,Hadoop3.x版本将端口从原来的50070改为9870.
如果浏览器无法打开:
- 确认防火墙已关闭;
- 确认SELINUX已关闭;
- 修改hdfs-site.xml文件。
前两项我们前面已经介绍过了,重点看看最后一项:
[root@DW1 hadoop-3.2.0]# cd $HADOOP_HOME/etc/hadoop
[root@DW1 hadoop]# vi hdfs-site.xml
# 添加以下内容
dfs.http.address
DW1:9870
然后再重启集群,再次访问192.168.XX.XXX:9870地址,如果提示:

更换浏览器,用Google等浏览器打开即可: