知识图谱用于推荐系统问题(MKR,KTUP)
前一篇文章介绍了知识图谱用于推荐系统问题(CKE,RippleNet),这一篇博文目整理对KG和RC融合的更加深入的两篇文章MKR,KTUP。MKR利用一个Cross单元使两者融合,KTUP则是相互补全相互增强的思路。
Multi-task Learning for KG enhanced Recommendation (MKR)
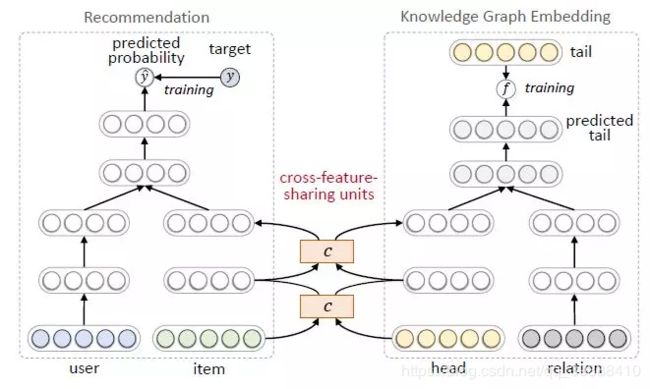
交替学习文章以更好的融合KG和RC。模型图如下:
- 左边是推荐任务。用户和物品的特征表示作为输入,预测点击率y
- 右边是知识图谱任务。三元组的头结点h和关系r表示作为输入,预测的尾节点t
- 两者的交互由一个cross-feature-sharing units完成
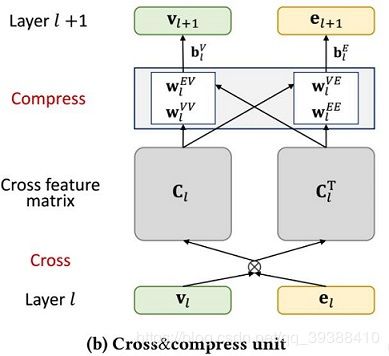
cross-feature-sharing units:由于物品向量和实体向量实际上是对同一个对象的两种描述,他们之间的信息交叉共享可以让两者都获得来自对方的额外信息,从而弥补了自身的信息稀疏性的不足。
计算细节如下。先cross,让v和e外积得到Cl的cross feature:
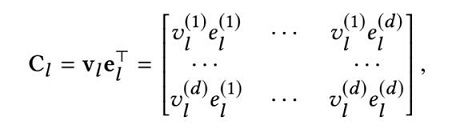
然后基于词再分别计算下一层的v和e,由权重w控制混合的程度:

最后的损失函数由两部分组成。
Unifying Knowledge Graph Learning and Recommendation:Towards a Better Understanding of User Preferences
统一知识图谱和推荐系统,出自何向南团队在WWW 2019的论文。
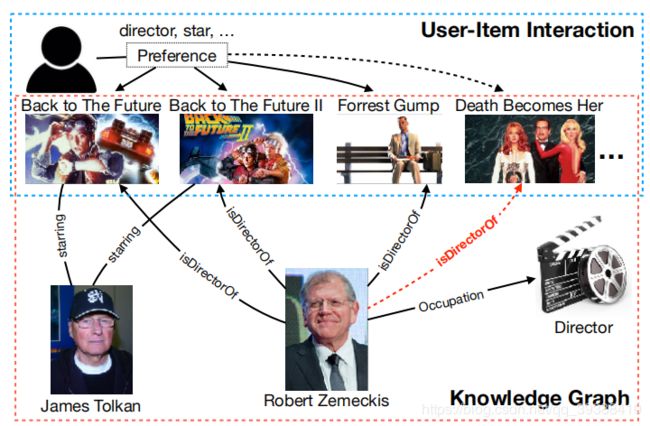
知识在提供有关物品的丰富信息方面显示出巨大的潜力,将知识图谱(KG)引入推荐系统去加强用户-物品的交互,有望提高推荐的准确性和可解释性。而这篇论文的主要动机是KG往往有可能是不完整的。如上图所示,Robert Zemeckis和Death Becomes Her之间的红色虚线可能就是缺失的关系。那么假设某用户喜欢Back to The Future和Forrest Gump,我们可以通过相关的实体和关系来理解用户对导演的偏好。但是在关系缺少的条件下,虽然已经准确地捕捉到了用户对电影的偏好,但我们仍然可能无法向用户推荐Death Becomes Her这部电影。
所以在使用KG做推荐时,考虑其不完整的性质是至关重要的,更有趣的是,作者提出KG的补全是否能反过来受益于用户-物品的交互。也就是说如果有一些喜欢这部电影的用户也喜欢Robert Zemeckis导演的其他电影,我们可以预测Robert Zemeckis是Death Becomes Her的导演,即用交互来补全KG。
- 所以一方面利用KG可以帮助更好的理解用户偏好
- 另一方面,用户-物品的交互可以补全KG,增强KG中缺少的事实
最终使两个部分都得到加强。
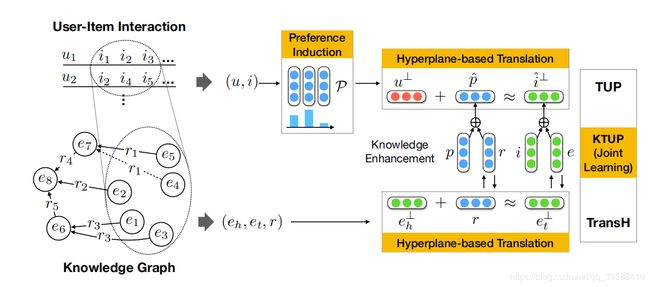
算法模型图主要如上,首先利用KG帮助理解用户-物品的行为以得到偏好,然后基于超平面,完成增强项目和偏好与实体和关系的嵌入来共同学习两项任务,其中KG直接增强用户-物品交互,而反向传播微调补全KG。接下来是对它每个部分的细致理解。
KG Embedding
KG Embedding目的是将实体和关系映射到低维连续的向量空间,从而简化KG的相关计算。主要有如下图所示的两种嵌入方法:
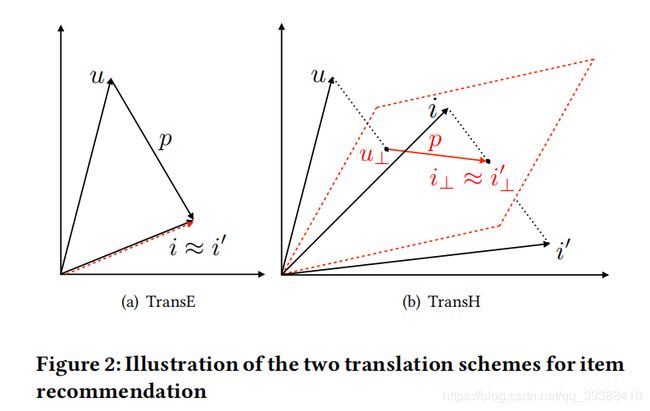
- TransE:对于KG中的三元组(h,r,t),尾部实体t的嵌入向量应该接近头实体h的嵌入向量加上一个取决于关系r的向量,简单来说就是 h+r≈t。在理解用户偏好过程中,相应的也就会有用户和物品之间的“关系”应该是用户喜欢该物品,即用户的偏好,于是就有上图的(a)结果,u+p≈i。
TransE简单有效,但是它并不能处理1-N,N-1, N-N的问题。比如,一个导演指导了多部电影,根据头节点h(导演),关系r(指导),尾节点t(电影)进行模型训练,那么这些电影向量的距离是很近的,而事实上他们是完全不同的实体。同理,只要物品嵌入i、i’是相似的,那么不管用户u的偏好p是什么,都会得到一样的结果。
- TransH:所以TransH把关系r表示成两个向量,这样对于不同的关系r节点有不同的表示。即把h和t 投影到一个超平面,得到投影向量h⊥和r⊥,然后关系作为在这两个投影向量之间的平移。对于每一种关系都要训练出一个超平面和与之对应的关系r。公式如下: u ⊥ = u − w p T u W p u^{⊥}=u-w_p^TuW_p u⊥=u−wpTuWp i ⊥ = i − w p T i w p i^{⊥}=i-w_p^Tiw_p i⊥=i−wpTiwp
用户-物品的交互和KG嵌入是相似的,所以同样的应该通过偏好进行超平面投影,在超平面上相似的物品会被用户喜欢,这才是正确的结论。所以首先分别对用户-物品和KG的实体都进行嵌入,KG的嵌入损失:
L k = ∑ ( e h , e t , r ) ∈ K G ∑ ( e h ′ , e t ′ , r ′ ) ∈ K G − [ f ( e h , e t , r ) + γ − f ( e h ′ , e t ′ , r ′ ) ] + L_k=\sum_{(e_h,e_t,r)\in KG} \sum_{(e'_h,e'_t,r')\in KG^-} [f(e_h,e_t,r)+\gamma-f(e'_h,e'_t,r')]_+ Lk=(eh,et,r)∈KG∑(eh′,et′,r′)∈KG−∑[f(eh,et,r)+γ−f(eh′,et′,r′)]+
接下来是如何结合这两者使其相互加强的过程。
KTUP
KG的存在可以补充物品i之间的连通性,而且作为对用户项对建模的约束。另一方面,对用户对项目偏好的理解应揭示其与某些关系类型和实体相关的共性,这些关系类型和实体可能在给定的KG中丢失。
首先是KG增强用户-物品的交互。主要是通过将实体的关系r加入到用户偏好p中,实体本身加入到物品i中一起参与交互,这可以提供给用户偏好和实体更好的解释。然后按照推荐算法的思路,就可以得到推荐物品给用户的损失函数L_p:
L p = ∑ ( u , i ) ∈ Y ∑ ( u , i ′ ) ∈ Y ′ − l o g σ [ g ( u , i ′ ; p ′ ) − g ( u , i ; p ) ] L_p=\sum_{(u,i)\in Y} \sum_{(u,i')\in Y'} -log \sigma[g(u,i';p')-g(u,i;p)] Lp=(u,i)∈Y∑(u,i′)∈Y′∑−logσ[g(u,i′;p′)−g(u,i;p)]
这里会对物品进行负采样,使真正交互过的正例概率更好的大于负例的概率。用户-物品的交互增强KG。对于实体,增强之后的物品i嵌入包含了与用户项交互互补的实体之间的关系知识,并改进了推荐。同时,嵌入实体的增强是通过反向传播,通过用户和项目的附加连接进行微调。
def forward(self, ratings, triples, is_rec=True):
if is_rec and ratings is not None:#推荐的部分
u_ids, i_ids = ratings
e_ids = self.paddingItems(i_ids.data, self.ent_total-1)
e_var = to_gpu(V(torch.LongTensor(e_ids)))
#得到user,item和e的嵌入向量
u_e = self.user_embeddings(u_ids)
i_e = self.item_embeddings(i_ids)
e_e = self.ent_embeddings(e_var)
ie_e = i_e + e_e
#由用户-物品的交互,得到用户偏好
_, r_e, norm = self.getPreferences(u_e, ie_e, use_st_gumbel=self.use_st_gumbel)
#将user和item用TansH进行投影
proj_u_e = projection_transH_pytorch(u_e, norm)
proj_i_e = projection_transH_pytorch(ie_e, norm)
if self.L1_flag:#L1正则
score = torch.sum(torch.abs(proj_u_e + r_e - proj_i_e), 1)
else:#否则使用L2正则
score = torch.sum((proj_u_e + r_e - proj_i_e) ** 2, 1)
elif not is_rec and triples is not None:#KG的部分
h, t, r = triples #得到实体三元组和他们的嵌入特征
h_e = self.ent_embeddings(h)
t_e = self.ent_embeddings(t)
r_e = self.rel_embeddings(r)
norm_e = self.norm_embeddings(r)
#用TransH进行投影
proj_h_e = projection_transH_pytorch(h_e, norm_e)
proj_t_e = projection_transH_pytorch(t_e, norm_e)
if self.L1_flag:#L1
score = torch.sum(torch.abs(proj_h_e + r_e - proj_t_e), 1)
else:#L2
score = torch.sum((proj_h_e + r_e - proj_t_e) ** 2, 1)
else:
raise NotImplementedError
return score
code:https://github.com/TaoMiner/joint-kg-recommender