Variational Autoencoder(变分自编码 VAE)
使用通用自编码器的时候,首先将输入encoder压缩为一个小的 form,然后将其decoder转换成输出的一个估计。如果目标是简单的重现输入效果很好,但是若想生成新的对象就不太可行了,因为其实我们根本不知道这个网络所生成的编码具体是什么。虽然我们可以通过结果去对比不同的对象,但是要理解它内部的工作方式几乎是不可能的,甚至有时候可能连输入应该是什么样子的都不知道。
解决方法是用相反的方法使用变分自编码器(Variational Autoencoder,VAE),即不去关注隐含向量所服从的分布,只需要告诉网络我们想让这个分布转换为什么样子就行了。VAE对隐层的输出增加了长约束,而在对隐层的采样过程也能起到和一般 dropout 效果类似的正则化作用。而至于它的名字变分推理(Variational Inference,VI)的思想是使用一个简单化的模型代替原始复杂的模型,而且希望简单模型能尽可能的靠近原来那个复杂的模型,从而可以减少计算量。即最大化与数据点x相关联的变分下界来训练,即寻找一个容易处理的分布 q(z),使得 q(z) 与目标分布p(z|x) 尽量接近以便用q(z) 来代替 p(z|x),分布之间的 ‘接近’ 度量采用 Kullback–Leibler divergence(KL 散度)。
作为一个生成式模型的代表,需要对P(X|z)建模,即输入隐变量z,输出是已知观察变量X的概率。和判别模型类似,通过最大化后验概率来优化建模,即:
p ( z ∣ X ) = p ( X ∣ z ) p ( z ) p ( X ) = p ( X ∣ z ) p ( z ) ∫ z p ( X ∣ z ) p ( z ) d z p(z|X)=\frac {p(X|z)p(z)}{ p(X)}=\frac {p(X|z)p(z)}{\int_z p(X|z)p(z)dz} p(z∣X)=p(X)p(X∣z)p(z)=∫zp(X∣z)p(z)dzp(X∣z)p(z)
但是在复杂模型和大规模数据面前,这个公式难以求解,于是利用变分的方法尝试找到一个q(z)函数来代替p(z|X)。那么要使两者尽可能的接近,即用衡量两者分布的相似度KL散度可以有:
K L ( q ( z ) ∣ ∣ p ( z ∣ X ) ) = ∫ q ( z ) l o g q ( z ) p ( z ∣ X ) d z = ∫ q ( z ) [ l o g q ( z ) − l o g p ( z ∣ X ) ] d z KL(q(z)||p(z|X))=\int q(z)log \frac{q(z)}{p(z|X)} dz=\int q(z)[logq(z)-logp(z|X)] dz KL(q(z)∣∣p(z∣X))=∫q(z)logp(z∣X)q(z)dz=∫q(z)[logq(z)−logp(z∣X)]dz
在根据贝叶斯公式进行变换有:
= ∫ q ( z ) [ l o g q ( z ) − l o g p ( X ∣ z ) p ( z ) p ( X ) ] d z =\int q(z)[logq(z)-log \frac{p(X|z)p(z)}{p(X)}] dz =∫q(z)[logq(z)−logp(X)p(X∣z)p(z)]dz
= ∫ q ( z ) [ l o g q ( z ) − l o g p ( X ∣ z ) − l o g p ( z ) ] d z + l o g p ( X ) =\int q(z)[logq(z)-logp(X|z)-logp(z)]dz+logp(X) =∫q(z)[logq(z)−logp(X∣z)−logp(z)]dz+logp(X)
X于要求解的z无关,恒等交换下可以得到:
l o g p ( X ) − K L ( q ( z ) ∣ ∣ p ( z ∣ X ) ) = ∫ q ( z ) l o g p ( X ∣ z ) d z − K L ( q ( z ) ∣ ∣ p ( z ) ) logp(X)-KL(q(z)||p(z|X))=\int q(z)logp(X|z)dz-KL(q(z)||p(z)) logp(X)−KL(q(z)∣∣p(z∣X))=∫q(z)logp(X∣z)dz−KL(q(z)∣∣p(z))
等式左边关于可观察的X的分布p(X)不容易求,但是X是固定已知,P(X)是固定值实际上不需要考虑,那么如果想要-KL(q(z)||p(z|X))越小,即更接近的话,就要等式右边的值越大。而右边是q(z)的期望减去一个KL散度,于是优化目标就变成了:
- 将第一项log似然期望最大化
- 将第二项的KL散度最小化
换个角度理解,其实
- 第一项可以视为潜变量z的近似后验下可见和隐藏变量的联合对数似然性(正如EM一样,不同的是这里使用近似而不是精确后验)。
- 第二项则可视为近似后验的熵。当 q 被选择为高斯分布,其中噪声被添加到预测平均值时,最大化该熵项促进增加该噪声的标准偏差。
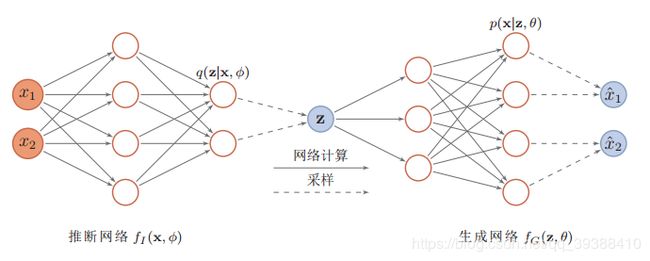
回顾一下自编码器,Encoder模型实际实际上可以完成从观测数据到隐含数据的转变,那么就可以完全认为它学习到了相应的分布,KL散度的模型就建立好了。那么通过Encoder计算出的观察变量X所对应的隐变量z(即由X得到z,将通过网络来学习),直接建模,即输入z输出X,如果输出图像相近就可以认为似然函数也得到了最大化,这也就是Decoder的部分。
故整体来说,为了从模型生成样本,VAE将会首先从编码分布 p m o d e l ( z ) p_{model}(z) pmodel(z) 中采样 z,然后使样本通过可微生成器神经网络 g(z)。最后,从分布 p m o d e l ( x ; g ( z ) ) = p m o d e l ( x ∣ z ) p_{model}(x; g(z)) = p_{model}(x | z) pmodel(x;g(z))=pmodel(x∣z) 中采样 x。而在训练期间,近似推断网络(编码器)q(z | x) 用于获得 z, p m o d e l ( x ∣ z ) p_{model}(x | z) pmodel(x∣z) 则被视为解码器网络。
用一个简单的github代码实现来理解:
这段代码目的是生成和MNIST中不一样的手写数字图像,而首先要做的先对MNIST中的数据进行编码,然后定义一个正态分布便于解码时得出我们期望生成的结果,即在解码时从该分布中随机采样得到“伪造”的图像。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data')#28*28的单色道图像数据
tf.reset_default_graph()
batch_size = 64
X_in = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28], name='X')
Y = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28], name='Y')
Y_flat = tf.reshape(Y, shape=[-1, 28 * 28])#用于计算损失函数
keep_prob = tf.placeholder(dtype=tf.float32, shape=(), name='keep_prob')#dropout比率
dec_in_channels = 1
n_latent = 8 #隐变量的维度设置
reshaped_dim = [-1, 7, 7, dec_in_channels]
inputs_decoder = 49 * dec_in_channels // 2
def lrelu(x, alpha=0.3):#自定义Leaky ReLU函数使效果更好
return tf.maximum(x, tf.multiply(x, alpha))
#编码
def encoder(X_in, keep_prob):
activation = lrelu
with tf.variable_scope("encoder", reuse=None):
X = tf.reshape(X_in, shape=[-1, 28, 28, 1])
x = tf.layers.conv2d(X, filters=64, kernel_size=4, strides=2, padding='same', activation=activation)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d(x, filters=64, kernel_size=4, strides=2, padding='same', activation=activation)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d(x, filters=64, kernel_size=4, strides=1, padding='same', activation=activation)
x = tf.nn.dropout(x, keep_prob)
x = tf.contrib.layers.flatten(x)
#q(z|X),需要通过一批次的X来随机的生成z(z的条件分布也需要不断学习)
mn = tf.layers.dense(x, units=n_latent) #利用计算means
sd = 0.5 * tf.layers.dense(x, units=n_latent) #利用计算standard
epsilon = tf.random_normal(tf.stack([tf.shape(x)[0], n_latent])) #从正态分布中采样
z = mn + tf.multiply(epsilon, tf.exp(sd))
return z, mn, sd
#解码
def decoder(sampled_z, keep_prob):
with tf.variable_scope("decoder", reuse=None):
x = tf.layers.dense(sampled_z, units=inputs_decoder, activation=lrelu)
x = tf.layers.dense(x, units=inputs_decoder * 2 + 1, activation=lrelu)
x = tf.reshape(x, reshaped_dim)
x = tf.layers.conv2d_transpose(x, filters=64, kernel_size=4, strides=2, padding='same', activation=tf.nn.relu)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d_transpose(x, filters=64, kernel_size=4, strides=1, padding='same', activation=tf.nn.relu)
x = tf.nn.dropout(x, keep_prob)
x = tf.layers.conv2d_transpose(x, filters=64, kernel_size=4, strides=1, padding='same', activation=tf.nn.relu)
#还原成28x28
x = tf.contrib.layers.flatten(x)
x = tf.layers.dense(x, units=28*28, activation=tf.nn.sigmoid)
img = tf.reshape(x, shape=[-1, 28, 28])
return img
#结合
sampled, mn, sd = encoder(X_in, keep_prob)
dec = decoder(sampled, keep_prob)
#损失函数的计算由两部分组成
unreshaped = tf.reshape(dec, [-1, 28*28])
#最大似然
img_loss = tf.reduce_sum(tf.squared_difference(unreshaped, Y_flat), 1)
#KL散度
latent_loss = -0.5 * tf.reduce_sum(1.0 + 2.0 * sd - tf.square(mn) - tf.exp(2.0 * sd), 1)
loss = tf.reduce_mean(img_loss + latent_loss)
optimizer = tf.train.AdamOptimizer(0.0005).minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(30000):#开始训练
batch = [np.reshape(b, [28, 28]) for b in mnist.train.next_batch(batch_size=batch_size)[0]]
sess.run(optimizer, feed_dict = {X_in: batch, Y: batch, keep_prob: 0.8})
if not i % 200:
ls, d, i_ls, d_ls, mu, sigm = sess.run([loss, dec, img_loss, latent_loss, mn, sd], feed_dict = {X_in: batch, Y: batch, keep_prob: 1.0})
plt.imshow(np.reshape(batch[0], [28, 28]), cmap='gray')
plt.show()
plt.imshow(d[0], cmap='gray')
plt.show()
print(i, ls, np.mean(i_ls), np.mean(d_ls))
#单独拿出来可以用于生成新的字符
randoms = [np.random.normal(0, 1, n_latent) for _ in range(10)]
imgs = sess.run(dec, feed_dict = {sampled: randoms, keep_prob: 1.0})
imgs = [np.reshape(imgs[i], [28, 28]) for i in range(len(imgs))]
for img in imgs:
plt.figure(figsize=(1,1))
plt.axis('off')
plt.imshow(img, cmap='gray')
另外它还有非常好的特性是同时训练参数编码器与生成器网络的组合迫使模型学习编码器可以捕获可预测的坐标系,这使其成为一个优秀的流形学习算法,如下图展示的是由变分自动编码器学到的低维流形的例子,可以看出它发现了两个存在于面部图像的因素:旋转角和情绪表达。

而VAE的主要缺点是从在图像上训练的变分自动编码器中采样的样本往往有些模糊,而且原因尚不清楚,其中一种可能性是因为最小化KL散度而由于模糊性是最大似然的固有效应产生的。
同样作为生成模型的,也能得到很好的“伪造”数据的就是生成对抗GAN模型了。但与GAN十分的暴力(利用判别器做一个转化模块,而且衡量生成与真实的分布差异)不同,VAE不那么的直观,只是通过约束隐变量z服从标准正态分布以及重构数据(z与标准正态的KL散度和重构)实现了映射X=G(z)
生成式与判别式
- 判别式针对条件分布建模, P ( y ∣ x ) P(y|x) P(y∣x)。学习到不同类别的最优边界,反映出不同类别之间的差异信息,无法反映出数据本身的特性。需要样本少,计算快,预测时性能较好。代表算法:回归,SVM,NN,CRF。
- 生成式根据联合分布建模, P ( x , y ) P(x,y) P(x,y)。对每一类各建模,然后贝叶斯算联合概率,不关心边界,而是反映样本数据之间的相似度,能够体现更多数据本身分布的信息。样本少时对分布计算很难,推断能力差,在一定情况下可以变成生成式。代表算法:贝叶斯,knn,混合高斯,HMM,MRF,DBM。
主要参考:
bengio deep learning