招商Fintech学习笔记 - 深度学习 - tensorflow 实现卷积层
TensorFlow 卷积层
TensorFlow 提供了 tf.nn.conv2d() 和 tf.nn.bias_add() 函数来创建你自己的卷积层。
# Output depth
k_output = 64
# Image Properties
image_width = 10
image_height = 10
color_channels = 3
# Convolution filter
filter_size_width = 5
filter_size_height = 5
# Input/Image
input = tf.placeholder(
tf.float32,
shape=[None, image_height, image_width, color_channels])
# Weight and bias
weight = tf.Variable(tf.truncated_normal(
[filter_size_height, filter_size_width, color_channels, k_output]))
bias = tf.Variable(tf.zeros(k_output))
# Apply Convolution
conv_layer = tf.nn.conv2d(input, weight, strides=[1, 2, 2, 1], padding='SAME')
# Add bias
conv_layer = tf.nn.bias_add(conv_layer, bias)
# Apply activation function
conv_layer = tf.nn.relu(conv_layer)
上述代码用了 tf.nn.conv2d() 函数来计算卷积,weights 作为滤波器,[1, 2, 2, 1] 作为 strides。TensorFlow 对每一个 input 维度使用一个单独的 stride 参数,[batch, input_height, input_width, input_channels]。我们通常把 batch 和 input_channels (strides 序列中的第一个第四个)的 stride 设为 1。
你可以专注于修改 input_height 和 input_width, batch 和 input_channels 都设置成 1。input_height 和 input_width strides 表示滤波器在input 上移动的步长。上述例子中,在 input 之后,设置了一个 5x5 ,stride 为 2 的滤波器。
tf.nn.bias_add() 函数对矩阵的最后一维加了偏置项。
最大池化
最大池化操作的好处是减小输入大小,使得神经网络能够专注于最重要的元素。最大池化只取覆盖区域中的最大值,其它的值都丢弃。
# Apply Max Pooling
conv_layer = tf.nn.max_pool(
conv_layer,
ksize=[1, 2, 2, 1], #滤波器大小
strides=[1, 2, 2, 1],#步长
padding='SAME')
tf.nn.max_pool() 函数实现最大池化时, ksize参数是滤波器大小,strides参数是步长。2x2 的滤波器配合 2x2 的步长是常用设定。
ksize 和 strides 参数也被构建为四个元素的列表,每个元素对应 input tensor 的一个维度 ([batch, height, width, channels]),对 ksize 和 strides 来说,batch 和 channel 通常都设置成 1。
- 池化层的作用
减小输出大小 和 降低过拟合
近期,池化层并不是很受青睐。部分原因是:
1、现在的数据集又大又复杂,我们更关心欠拟合问题。
2、Dropout 是一个更好的正则化方法。
3、池化导致信息损失。想想最大池化的例子,n 个数字中我们只保留最大的,把余下的 n-1 完全舍弃了。
池化机制
令H = height, W = width, D = depth
则:
输入维度是 4x4x5 (HxWxD)
滤波器大小 2x2 (HxW)
stride 的高和宽都是 2 (S)
新的高和宽的公式是:
new_height = (input_height - filter_height)/S + 1
new_width = (input_width - filter_width)/S + 1
此外,输出的深度(depth)和输入一样
卷积层
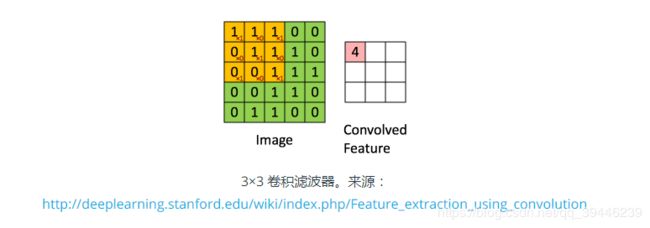
这是一个 3x3 的卷积滤波器的示例。以 stride 为 1 应用到一个范围在 0 到 1 之间的数据上。每一个 3x3 的部分与权值 [[1, 0, 1], [0, 1, 0], [1, 0, 1]] 做卷积,把偏置加上后得到右边的卷积特征。这里偏置是 0 。TensorFlow 中这是通过 tf.nn.conv2d() 和 tf.nn.bias_add() 来完成的。
def conv2d(x, W, b, strides=1):
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
W为滤波器的参数,b为bias的参数,通常对W和b作如下定义:
w1 = tf.Variable(tf.random_normal([5, 5, 1, 32])) # (height, width, input_depth, output_depth)
b1 = tf.Variable(tf.random_normal([32])) # output_depth
注意:这里对w1初始化的size是 [height, width, input_depth, output_depth] 和ksize/stride 不一样,stride是[batch, height, width, channels]
卷积后滤波器长度的计算:
new_height = (input_height - filter_height + 2 * P)/S + 1
new_width = (input_width - filter_width + 2 * P)/S + 1
其中P是padding的长度,S是步长(stride)