指令实现方式
逻辑运算与算数运算指令
在实验四的基础上,修改ALU_decoder模块,使ALU_decoder解析32位的指令数据,输出指令的类型(8位 alu_control):
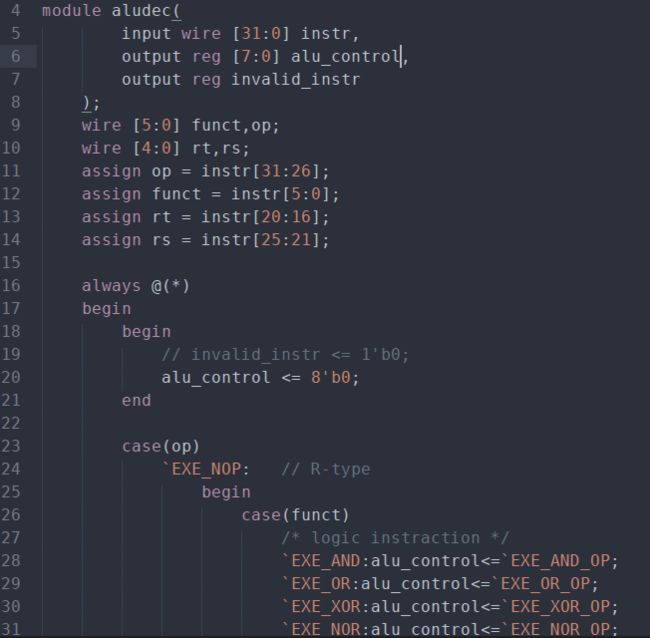
alu_control在controller模块中在执行阶段输出到数据通路中,并传给ALU,ALU根据指令类型对输入的两个操作数进行相应的运算。

对于乘法和除法的实现,将在之后讲述。
移位运算指令
移位指令在执行阶段需要知道移位的位数,对于sllv,srlv和srav指令,移位的位数保存在rs中,即ALU的第一个操作数,所以对于这3条指令可以直接在ALU里进行判断并进行运算:

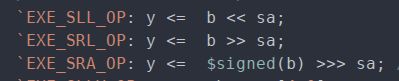
对于sll,srl和sra指令,移位量保存在指令的6到10位,因此,需要在数据通路中添加新的路线将此字段传入ALU中:
ALU则根据此字段(在这里是sa信号)进行移位操作。
数据移动指令
数据移动指令实现了寄存器堆到HILO寄存器之间的数据传送。HILO寄存器模块的代码如下:
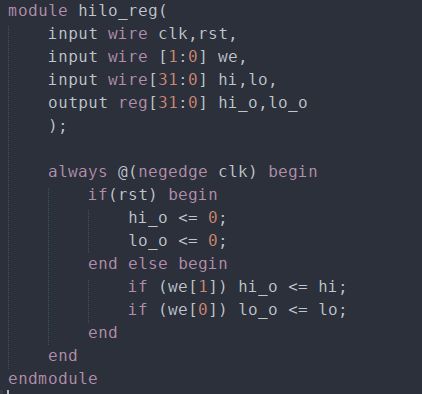
该模块可储存2个32位的值,命名为Hi和Lo寄存器,并且可以根据写使能信号"we"控制分别写两个寄存器。
同时对数据通路进行修改:
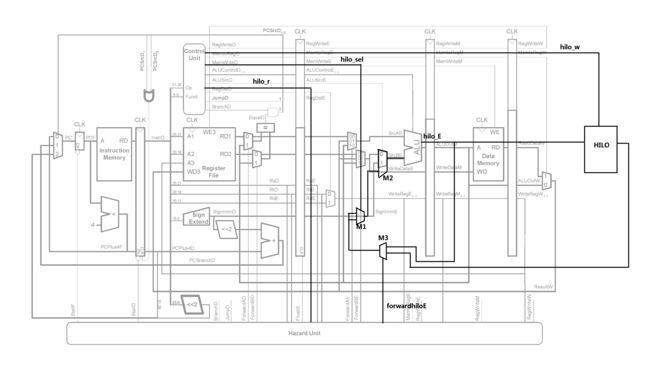
如图控制器模块新增3个信号:hilo_w[1:0],hilo_r,hilo_sel。hilo_w表示当前指令对应的hilo写使能信号,hilo_r表示当前指令是否要读取hilo的值,hilo_sel表示当前指令要对hilo寄存器中的哪一个进行读操作。
ALU新增64位输出hilo_E,用来传送写入hilo寄存器的数据,数据将在回写阶段写入hilo寄存器(如果要写入的话)。
对于mthi和mtlo指令,要将寄存器堆里的数据写入hilo中,执行这些指令时,控制器模块根据指令要写入的位置设置hilo_w信号,即若mthi指令hilo_w信号置2b'10,若mtlo指令hilo_w信号置2b'01;在执行阶段时要写入的数据为ALU的第一个操作数,于是将ALU的hilo_E输出相应位赋值:

对于mfhi和mflo指令,要读取hilo的值到寄存器堆中,于是将hilo寄存器模块的输出连接到执行阶段,通过多路选择器M2输入到ALU的第二个操作数端口,通过多路选择器M1选择输入hilo中的Hi还是Lo。
ALU里只是简单的把输入的第二个操作数作为结果返回了出去:
ALU输出的值在回写阶段最终写回寄存器堆,所以对于mfhi和mflo指令,控制器回写阶段的RegWriteW控制信号也要置为有效。
数据传送指令的数据冒险
当前一条指令要写入HILO而当前指令要读取HILO的值的时候,就会发生数据冒险。解决的方式是在访存阶段进行数据前推:当访存阶段的指令要写入hilo,执行阶段的指令要读取hilo,并且写入的地址和读取的地址一致时,把访存阶段要写回的数据前推到执行阶段。
数据通路图中的多路选择器M3就是选择是否使用前推的数据的。
乘法指令的实现
有了hilo寄存器后,就可以实现乘法指令了。
ALU在执行乘法时,会将结果输出到hilo数据线上:
控制器模块在回写阶段输出的hilo_w信号为2b'11,这样,乘法运算的结果就可以写回到hilo寄存器里了。
除法运算指令
由于除法指令无法在一个时钟周期内完成,所以执行阶段在执行除法指令的时候,流水线要进行暂停。
除法运算模块的接口如下
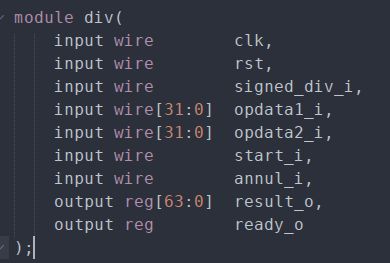
signed_div_i输入信号表示是否执行有符号除法,将输入start_i置为1即可开始除法运算,当输出ready_o为1时,表示除法运算完成,此时输出信号result_o就为计算所得的结果。
我们在ALU里对除法模块进行了实例化:
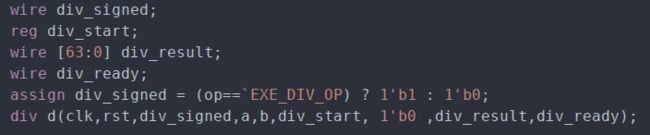
当执行阶段进行除法运算时,ALU判断除法是否得出结果,若除法运算结束,则重置除法开始信号(div_start)和除法暂停信号(div_stall),否则当前则处于除法刚开始或除法正在进行中,这时需要设置除法开始信号和除法暂停信号。
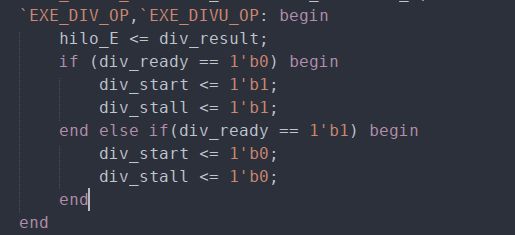
在hazard模块里要根据是否在进行除法运算来置位相应的流水线暂停信号:

div_stallE信号为ALU传入hazard模块的表示正在进行除法运算的信号,当此信号有效时,取指,译码,执行和访存阶段全都要暂停。
分支跳转指令
实验四已经实现了beq和无条件跳转j指令,在此基础上,本综合设计所要实现的分支跳转指令要解决的问题有3个:
- 对于分支指令,如何判断跳转条件满足。
- 对于跳转的目的地址的值位于寄存器内的指令(jr,jalr),如何将寄存器的值写入PC。
- 对于链接类指令(jalr,jal,bltzal,bgezal),如何将延迟槽之后指令的地址(PC+8)写入寄存器。
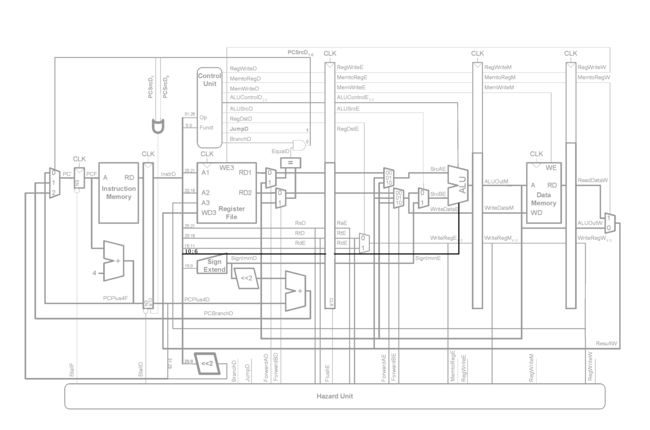
数据通路的修改如下:
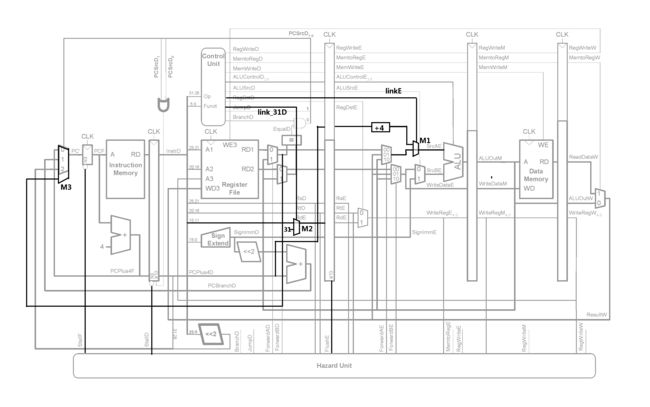
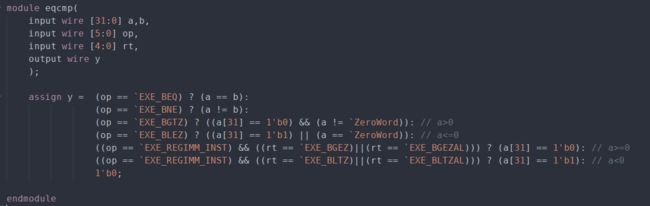
对于问题1,可以在实验四的分支满足判断模块(eqcmp)的基础上进行修改,增加对新的分支指令的判断并计算是否满足分支条件。
对于问题2,由于要写入的PC的寄存器的地址为指令的rs字段,于是将寄存器堆的数据输出RD1端口通过多路选择器M3连到PC的数据输入端,当执行jr或jalr指令时,则选择多路选择器选中此数据。注意到这样可能会引发数据冒险,因为读取的寄存器的值可能是“脏的”。
对于译码阶段为jr或jalr指令并且执行阶段为写寄存器类的指令,要进行流水线暂停:

对于译码阶段为jr或jalr指令并且访存阶段为写寄存器类的指令,由于实验4已经解决了此种情况读寄存器堆时的数据冒险,所以输入PC多路选择器的始终是最新的寄存器数据。
对于问题3,我们采取的做法是,若当前为链接类指令,则在译码阶段将PC+8传送到下一阶段,在执行阶段通过多路选择器M1输入ALU的第一个操作数端口,ALU对其原样输出到下一阶段,最终在回写阶段将数据写回寄存器堆。
由于要写回的寄存器的地址为31号寄存器($ra),所以在译码阶段还要通过一个多路选择器M2将目的地址31送入目的寄存器地址数据线。
访存指令
实现访存指令需要理清RAM读取和写入数据的规则。
因为内存是按字节寻址,但其数据线宽度为4个字节,即为1个字。字在内存里是有对齐要求的,字的起始地址为4的整数倍。
于是在读取内存时,读出来的是传入地址所在字的整个字的数据。向RAM写入数据时,可以根据写入地址和写使能信号实现对RAM任意字节的写入。
数据通路的修改如下:
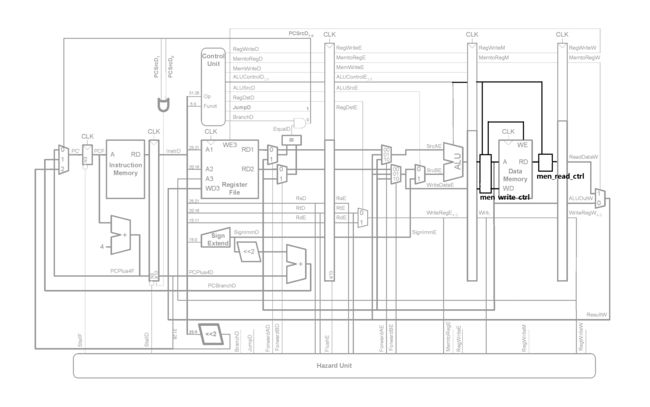
在访存阶段写入数据存储器前对数据进行处理,在读取到数据后也对读取到的数据进行处理。
数据存储器访问地址处理模块的部分代码如下,
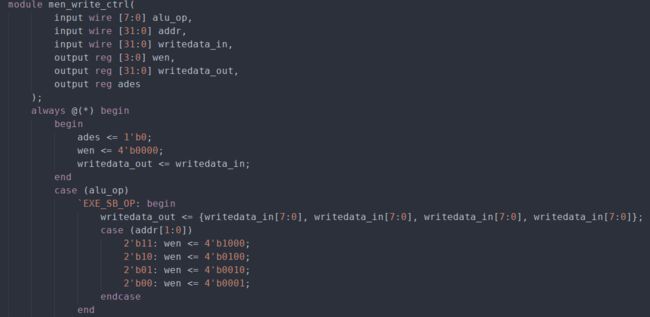
该模块根据写地址和访存指令的类型来确定写数据和数据存储器写使能信号。
数据存储器输出数据处理模块的部分代码如下:
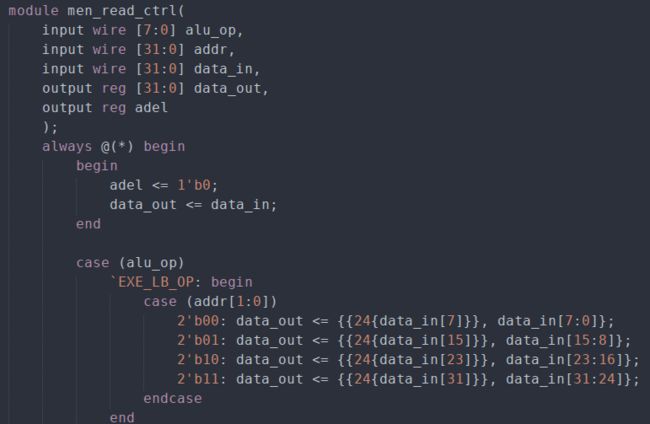
该模块根据读地址和访存指令的类型来对读到的数据进行处理。
异常相关指令
实现异相关指令的数据通路为:
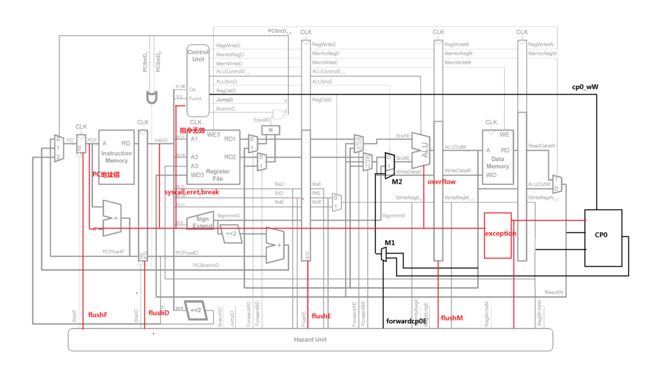
在MIPS的异常处理中,有一组用来保存处理器状态的寄存器,叫做CP0。本次综合设计只涉及其中与异常处理相关的寄存器(EPC,bad_addr,status,cause),在具体讲述异常处理的实现之前,先来说一下寄存器堆与CP0之间数据传送指令(mtc0,mfc0)的实现,数据通路图中黑线表示CP0的实现。
mtc0和mfc0的实现
这两条指令的实现和HILO寄存器数据传送指令相似,实现mtc0和mfc0指令涉及的CP0模块的端口如下:
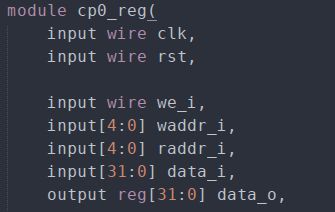
信号raddr_i、data_o表示要读取的寄存器号和读出来的值,信号waddr_i、data_i表示要写入的寄存器号和写入的数据,输入we_i为写使能信号。
对于mtc0指令,要将寄存器堆里的数据写入到CP0的某个寄存器中。
控制器模块在回写阶段新增cp0_wW信号,表示是否要写CP0。在译码阶段把要写入的数据和地址一步步传到回写阶段,传入CP0的data_i和waddr_i端口里,同时cp0_wW置1,这样数据就可以写到CP0中去了。
由于要在译码阶段开始读数据,在回写阶段才写入CP0,则有可能面临读到“脏数据”的情况,但仔细思考后发现此种冒险已经在之前解决R型指令的数据冲突的时候解决了,因此总可以保证写入CP0的值为最新数据。
对于mfc0指令,要将CP0的数据写入到寄存器堆中。实现方式与mfhi和mflo指令类似。在执行阶段,将CP0的读取地址连接到CP0的读地址输入端,将CP0寄存器的输出通过多路选择器M2输入到ALU的第二个操作数端口,ALU对传入的数据原样输出,当执行到回写阶段时,读到的数据就可以写入寄存器堆了。
和mfhi和mflo指令一样,mfc0指令也存在数据冒险。当前一条指令要写入CP0而当前指令要读取CP0的时候,就会发生数据冒险。解决的方式是在访存阶段进行数据前推:当访存阶段的指令要写CP0,执行阶段的指令要读CP0,并且写入的地址和读取的地址一致时,就把访存阶段要写回的数据前推到执行阶段。
异常处理的实现
数据通路图中红线表示异常处理通路。
本次综合设计共实现了8种异常。分别是PC地址出错、syscall、break、eret、指令无效异常、算数溢出、读数据存储器地址异常和写数据存储器地址异常。对于这些异常处理流程基本一致,首先是在访存阶段之前收集各类异常,与异常一起往后传递的是表示当前指令是否为延迟槽的信号、指令的PC,指令出错的地址(如果有的话),在访存阶段对收集到的异常进行统一处理,判断是否出现异常,若出现异常则根据优先级确定异常类型,清空流水线并把异常信息写入CP0,同时还要设置新的PC。
下图为数据通路中各阶段对异常的收集

访存阶段对异常的判断是在exception模块里实现的:

当异常出现时对流水线进行清空的信号是hazard模块输出的:
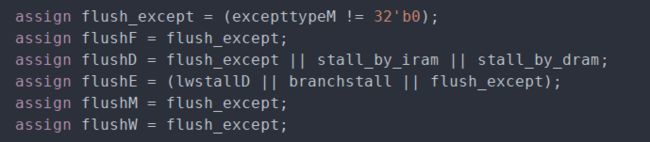
同时对不同的异常输出相应的PC跳转地址
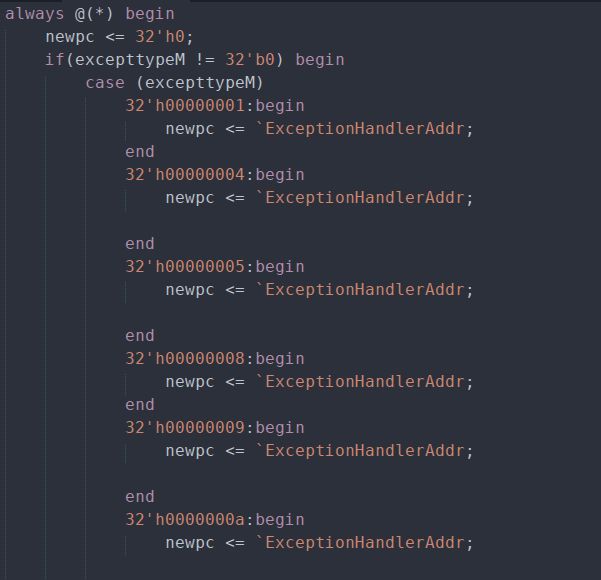
在这里也将eret指令看做异常,其异常处理地址为EPC。
优化的实现
我们针对流水线断流问题进行了优化。流水线断流集中于分支指令与访存延迟问题上。
前述分支指令实现仅将访存阶段的数据前推到了译码阶段,而当译码阶段读取寄存器的数据还处在执行阶段时,就要暂停译码阶段之前的流水线。
可以将执行阶段的数据前推回译码阶段从而消除这种情况的流水线暂停。
在前述实现中,当访存指令(例如 lw)后面紧跟如寄存器类型的指令时,若发生数据冒险,就要在后一条指令处于执行阶段时暂停执行阶段之前的流水线。
对于这种情况的优化是不暂停流水线,而是直接将访存阶段读出来的数据前推回执行阶段。
优化减少了流水线断流的概率,使得本实现的平均CPI减少。
测试结果
-
仿真结果截图
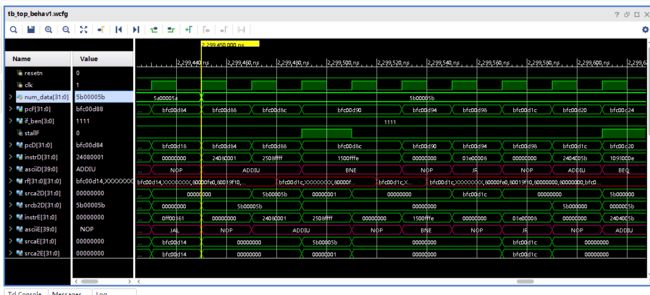 image.png
image.png
我们实现了完整的57条指令,并通过了全部的测试文件。
-
仿真代码调试心得
在实现完指令后进行仿真时,常常需要快速定位处于某个阶段的某条指令,这时候如果根据PC的值进行推算是相当麻烦且容易出错的,因为数据通路里的PC只是对应当前取址阶段的指令。比如想定位PC为a的指令的执行阶段,如果先找到PC等于a的时刻,再去往后推2个阶段,这样就认为当前时刻是所找指令的执行阶段是不恰当的,因为a指令从取址到执行阶段中间可能经历了流水线暂停,这样一来所花费的时间就大于2个周期。
于是我们在长期代码调试中总结了一套快速定位指令某个阶段的方法:
设计一个解析MIPS指令的模块,将32位二进制指令转化成ascii可读的格式,模块部分代码如下(完整代码见附件instdec.v):
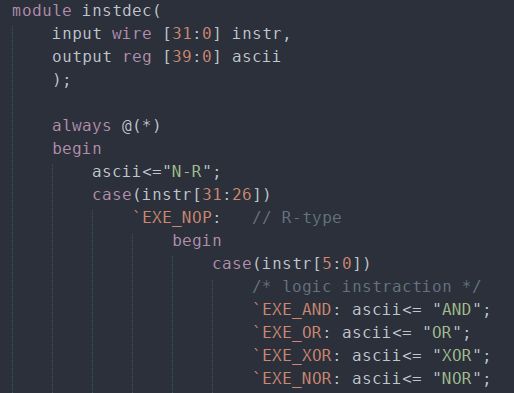 image.png
image.png
在数据通路中,将指令也逐级往后传,传递过程中注意flush和stall信号与同一阶段其他flop模块的对应。
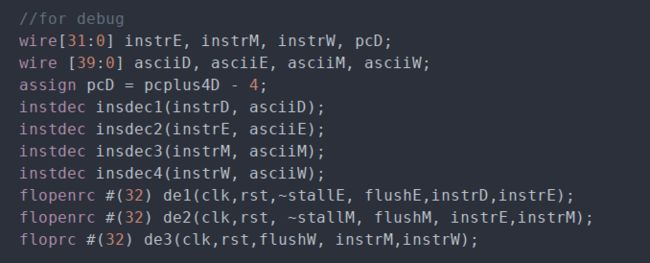 image.png
image.png
最后在仿真文件里添加MIPS指令解析模块的输出信号,并设置显示格式为ascii,最后的显示效果如下图:
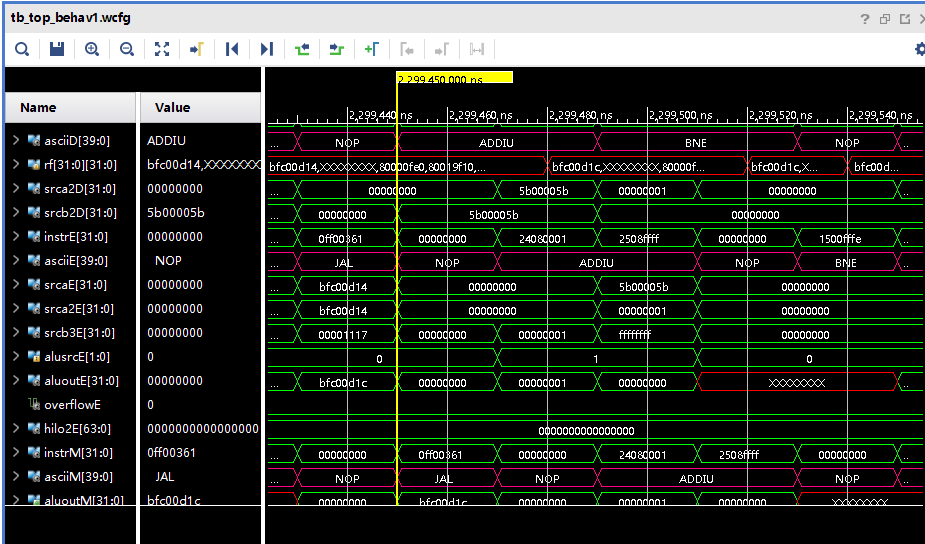 image.png
image.png
可以看到,当前时刻译码阶段正在执行addiu指令、执行阶段为空指令、访存阶段为jal指令。
通过此种方法可大大节省调试中定位代码所花费的时间。
结论
本次硬件综合设计,我们共实现了全部57条指令,并且连接了总线,通过了全部的功能测试。
我们针对流水线断流问题进行了优化。消除了2种情况下的流水线断流问题。
我们在本综合设计的代码调试中总结出一套快速定位指令某个阶段的方法。
最后,通过此综合设计,我们在CPU层面上更加深入的理解了计算机系统,这是我们理解整个计算机体系结构的基础,对于我们以后工程开发中的性能优化也有指导意义。
参考文献
自己动手写CPU 雷思磊 2014 电子工业出版社
MIPS Converter https://www.eg.bucknell.edu/~csci320/mips_web/ (在线解析十六进制MIPS指令)