参考https://www.cnblogs.com/keerya/p/8040071.html
1、什么是puppet
puppet是一个IT基础设施自动化管理工具,它能够帮助系统管理员管理基础设施的整个生命周期: 供应(provisioning)、配置(configuration)、联动(orchestration)及报告(reporting)。
基于puppet ,可实现自动化重复任务、快速部署关键性应用以及在本地或云端完成主动管理变更和快速扩展架构规模等。
遵循GPL 协议(2.7.0-), 基于ruby语言开发。
2、puppet的工作机制
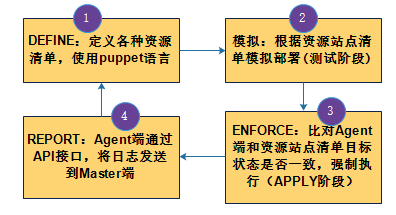
puppet 通过声明性、基于模型的方法进行IT自动化管理。
定义:通过puppet 的声明性配置语言定义基础设置配置的目标状态;
模拟:强制应用改变的配置之前先进行模拟性应用;
强制:自动、强制部署达成目标状态,纠正任何偏离的配置;
报告:报告当下状态及目标状态的不同,以及达成目标状态所进行的任何强制性改变;
master/agent的工作原理

在puppet中的一些术语
资源:是puppet的核心,通过资源申报,定义在资源清单中。相当于ansible中的模块,只是抽象的更加彻底。
类:一组资源清单。
模块:包含多个类。相当于ansible中的角色。
站点清单:以主机为核心,应用哪些模块。
yum install facter puppet puppet-server
资源定义:向资源类型的属性赋值来实现,可称为资源类型实例化;定义了资源实例的文件即清单,manifest;
定义资源的语法:
type {'title':
attribute1 => value1,
atrribute2 => value2,
……
}
注意:type必须使用小写字符;title是一个字符串,在同一类型中必须惟一;puppet资源清单的后缀通常是pp
示例:
vim first.pp
group{'nginx':
ensure => present
name => 'nginx',
system => true,
}
puppet apply --verbose --noop --debug first.pp
资源属性中的三个特殊属性:
- Namevar, 可简称为name;
- ensure:资源的目标状态;
- Provider:指明资源的管理接口;
关系元参数:before/require
A before B: B依赖于A,定义在A资源中;
{
...
before => Type['B'],
...
}
B require A: B依赖于A,定义在B资源中;
{
...
require => Type['A'],
...
}
另一种形式:
A -> B A依赖于B
A ~> B A执行完通知B
关系元参数:notify/subscribe
notify
A notify B:B依赖于A,且A发生改变后会通知B;
{
...
notify => Type['B'],
...
}
subscribe
B subscribe A:B依赖于A,且B监控A资源的变化产生的事件;
{
...
subscribe => Type['A'],
...
}
核心资源类型:
user:
name:用户名;
uid: UID;
gid:基本组ID;
groups:附加组,不能包含基本组;
comment:注释;
expiry:过期时间 ;
home:家目录;
shell:默认shell类型;
system:是否为系统用户 ;
ensure:present/absent;
password:加密后的密码串;
group:
name:组名;
gid:GID;
system:是否为系统组,true OR false;
ensure:目标状态,present/absent;
members:成员用户;
package:
ensure:installed, present, latest, absent
name:包名;
source:程序包来源,仅对不会自动下载相关程序包的provider有用,例如rpm或dpkg;
service
ensure:Whether a service should be running. Valid values are `stopped` (also called `false`), `running` (also called `true`).
enable:Whether a service should be enabled to start at boot. Valid values are `true`, `false`, `manual`.
name:不写默认
path:The search path for finding init scripts. Multiple values should be separated by colons or provided as an array. 脚本的搜索路径,默认为/etc/init.d/;
hasrestart:是否能重启
hasstatus:是否有状态
start:手动定义启动命令;
stop:
status:
restart: 通常用于定义reload操作;
file:
ensure:
file:类型为普通文件,其内容由content属性生成或复制由source属性指向的文件路径来创建;
link:类型为符号链接文件,必须由target属性指明其链接的目标文件;
directory:类型为目录,可通过source指向的路径复制生成,recurse属性指明是否递归复制;
present:
absent:
path:文件路径;
source:源文件;
content:文件内容;
target:符号链接的目标文件;
owner:属主
group:属组
mode:权限;
atime/ctime/mtime:时间戳;
示例1:
package{'redis':
ensure => present,
}
file{'/etc/redis.conf':
ensure => file,
source => '/root/manifest/redis.conf',
owner => 'redis',
group => 'redis',
mode => '0644',
}
service{'redis':
ensure => true,
enable => true,
require => Package['redis'],
subscribe => File
}
#依赖关系可以用
Package['redis'] -> File['redis.conf'] -> Service['redis']
exec:
command(namevar):要运行的命令;
cwd:The directory from which to run the command.
creates:文件路径,仅此路径表示的文件不存在时,command方才执行;
user/group:运行命令的用户身份;
path:在这个路径中搜索命令
onlyif:此属性指定一个命令,此命令正常(退出码为0)运行时,当前command才会运行;
unless:此属性指定一个命令,此命令非正常(退出码为非0)运行时,当前command才会运行;
refresh:重新执行当前command的替代命令;
refreshonly:仅接收到订阅的资源的通知时方才运行;
cron:
command:要执行的任务;
ensure:使用absent来删除任务
hour:
minute:
monthday:
month:
weekday:
user:以哪个用户的身份运行命令
target:添加为哪个用户的任务
name:cron job的名称;
notify:
message:信息内容
name:信息名称;
示例2:
package{'tomcat':
ensure => present,
}
exec{'adduser':
command => 'useradd -r tomcat',
path => '/bin:/sbin:/usr/bin:/usr/sbin',
unless => 'id abc',
refreshonly => true,
subscribe => Package['tomcat']
}
cron{'synctime':
ensure => absent,
command => '/usr/sbin/ntpdate 192.168.31.100 &> /dev/null',
name => 'synctime from ntp',
minute => '*/3', #3分钟运行一次
}
puppet 变量:
数据类型:
字符型:引号可有可无;但单引号为强引用,双引号为弱引用;
数值型:默认均识别为字符串,仅在数值上下文才以数值对待;
数组:[]中以逗号分隔元素列表;
布尔型值:true, false;
hash:{}中以逗号分隔k/v数据列表; 键为字符型,值为任意puppet支持的类型;{ 'mon' => 'Monday', 'tue' => 'Tuesday', };
undef:未定义 ;
正则表达式:
(?:)
(?-:)
OPTIONS:
i:忽略字符大小写;
m:把.当换行符;
x:忽略中的空白字符
(?i-mx:PATTERN)
变量类型:
facts:
由facter提供;top scope;
内建变量:
master端变量
agent端变量
parser变量
用户自定义变量:
变量有作用域,称为Scope;
top scope: $::var_name
node scope
class scope
流程控制语句:
if语句
if语句:
if CONDITION {
...
} else {
...
}
CONDITION的给定方式:
(1) 变量
(2) 比较表达式
(3) 有返回值的函数
示例1
if $osfamily =~ /(?i-mx:debian)/ {
$webserver = 'apache2'
} else {
$webserver = 'httpd'
}
package{"$webserver":
ensure => installed,
before => [ File['httpd.conf'], Service['httpd'] ],
}
file{'httpd.conf':
path => '/etc/httpd/conf/httpd.conf',
source => '/root/manifests/httpd.conf',
ensure => file,
}
service{'httpd':
ensure => running,
enable => true,
restart => 'systemctl restart httpd.service',
subscribe => File['httpd.conf'],
}
case语句:
case CONTROL_EXPRESSION {
case1: { ... }
case2: { ... }
case3: { ... }
...
default: { ... }
}
CONTROL_EXPRESSION:
(1) 变量
(2) 表达式
(3) 有返回值的函数
各case的给定方式:
(1) 直接字串;
(2) 变量
(3) 有返回值的函数
(4) 正则表达式模式;
(5) default
#匹配到了就执行对应的语句
示例2:
case $osfamily {
"RedHat": { $webserver='httpd' }
/(?i-mx:debian)/: { $webserver='apache2' }
default: { $webserver='httpd' }
}
package{"$webserver":
ensure => installed,
before => [ File['httpd.conf'], Service['httpd'] ],
}
file{'httpd.conf':
path => '/etc/httpd/conf/httpd.conf',
source => '/root/manifests/httpd.conf',
ensure => file,
}
service{'httpd':
ensure => running,
enable => true,
restart => 'systemctl restart httpd.service',
subscribe => File['httpd.conf'],
}
selector语句:
CONTROL_VARIABLE ? {
case1 => value1,
case2 => value2,
...
default => valueN,
}
注意:不能使用列表格式;但可以是其它的selecor;
示例3:
$webserver = $osfamily ? {
"Redhat" => 'httpd',
/(?i-mx:debian)/ => 'apache2',
default => 'httpd',
}
package{"$webserver":
ensure => installed,
before => [ File['httpd.conf'], Service['httpd'] ],
}
file{'httpd.conf':
path => '/etc/httpd/conf/httpd.conf',
source => '/root/manifests/httpd.conf',
ensure => file,
}
service{'httpd':
ensure => running,
enable => true,
restart => 'systemctl restart httpd.service',
subscribe => File['httpd.conf'],
}
类(class)
puppet中命名的代码模块,常用于定义一组通用目标的资源,可在puppet全局调用;如果是server/agent模式则可在整个集群中调用
类可以被继承,也可以包含子类;
语法格式:
class NAME {
...puppet code...
}
class NAME(parameter1, parameter2) {
...puppet code...
}
示例:
class dbserver($pkgname) {
package{"$pkgname":
ensure => latest,
}
service{"$pkgname":
ensure => running,
enable => true,
}
}
if $operatingsystem == "CentOS" {
$dbpkg = $operatingsystemmajrelease ? {
7 => 'mariadb-server',
default => 'mysql-server',
}
}
class{'dbserver':
pkgname => 'mariadb-server',
}
类继承的方式:
class SUB_CLASS_NAME inherits PARENT_CLASS_NAME {
...puppet code...
}
在子类中为父类的资源新增属性或覆盖指定的属性的值:
Type['title']
{
attribute1 = > value,
...
}
在子类中为父类的资源的某属性增加新值:
Type['title']
{
attribute1 + > value,
...
}
示例:
class nginx {
package{'nginx':
ensure => installed,
}
service{'nginx':
ensure => running,
enable => true,
restart => '/usr/sbin/nginx -s reload',
require => Package['nginx'],
}
}
class nginx::web inherits nginx {
Service['nginx'] {
subscribe => File['ngx-web.conf'],
}
file{'ngx-web.conf':
path => '/etc/nginx/conf.d/ngx-web.conf',
ensure => file,
source => '/root/manifests/ngx-web.conf',
}
}
class nginx::proxy inherits nginx {
Service['nginx'] {
subscribe => File['ngx-proxy.conf'],
}
file{'ngx-proxy.conf':
path => '/etc/nginx/conf.d/ngx-proxy.conf',
ensure => file,
source => '/root/manifests/ngx-proxy.conf',
}
#重写父类中的nginx
serveice['nginx']{
enable => false,
require +> File['ngx-proxy.conf'],
}
}
include nginx::proxy
模板(template):
模块就是一个按约定的、预定义的结构存放了多个文件或子目录的目录,目录里的这些文件或子目录必须遵循一定格式的命名规范; puppet会在配置的路径下查找所需要的模块;
puppet兼容的erb语法:
https://docs.puppet.com/puppet/latest/reference/lang_template_erb.html
erb:Embedded RuBy
<%= erb code %>
<% erb code %>
<%# erb code %>
但我们没必要去特意的学一门语言,我们只需要能在模板文件中嵌入所需的变量替换即可
示例:
class nginx {
package{'nginx':
ensure => installed,
}
service{'nginx':
ensure => running,
enable => true,
require => Package['nginx'],
}
}
class nginx::web inherits nginx {
file{'ngx-web.conf':
path => '/etc/nginx/conf.d/ngx-web.conf',
ensure => file,
require => Package['nginx'],
source => '/root/manifests/nginx/ngx-web.conf',
}
file{'nginx.conf':
path => '/etc/nginx/nginx.conf',
ensure => file,
content => template('/root/manifests/nginx.conf.erb'),
require => Package['nginx'],
}
Service['nginx'] {
subscribe => [ File['ngx-web.conf'], File['nginx.conf'] ],
}
}
include nginx::web
模块(module):
模块就是一个按约定的、预定义的结构存放了多个文件或子目录的目录,目录里的这些文件或子目录必须遵循一定格式的命名规范; puppet会在配置的路径下查找所需要的模块;模块名只能以小写字母开头,可以包含小写字母、数字和下划线;但不能使用”main"和"settings“;Puppet的模块(module)相当于Ansible的role(角色)
manifests /
init.pp:必须一个类定义,类名称必须与模块名称相同;
files /:静态文件;
lib /:插件目录,常用于存储自定义的facts以及自定义类型;
spec /:类似于tests目录,存储lib / 目录下插件的使用帮助和范例;
tests /:当前模块的使用帮助或使用范例文件;
puppet
URL:
puppet:
puppet:// / modules / MODULE_NAME / FILE_NAME
templates /:
tempate('MOD_NAME/TEMPLATE_FILE_NAME')
puppet config print modulepath
找到puppet查找模块的路径
puppet module serach nginx
搜索查找nginx相关的模块
puppet module install MODULE_NAME
下载别人开发好的模块
或者我们也可以自己手动创建一个模块
mkdir modules
#在modules目录下每一个模块都是一个目录
mkdir chrony/{manifests,files,templates,lib,spec,tests} -pv
cd chrony
#需要在主目录下创建一个init.pp里面创建一个类,类名必须与模块名相同
vim ./manifests/init.pp
class chrony {
package{'chrony':
ensure => latest,
} ->
file{'chrony.conf':
path =>'/etc/chrony.conf',
source => 'puppet:///modules/chrony/chrony.conf',
} ~>
service{'chronyd':
ensure => running,
enable => true,
}
}
cp /etc/chrony.conf ./files
cp -a chrony/ /etc/puppet/modules/
至此chrony模块就定义好了
查看本机的模块puppet module list
/etc/puppet/modules
├── chrony (???)
├── oris-nginx (v1.3.0)
├── puppetlabs-apt (v6.2.1)
├── puppetlabs-stdlib (v5.1.0)
└── puppetlabs-translate (v1.2.0)
/usr/share/puppet/modules (no modules installed)
测试刚刚定义的模块
puppet apply -v -d -e 'include chrony'
注意:
1、puppet 3.8及以后的版本中,资源清单文件的文件名要与文件听类名保持一致,例如某子类为为“base_class::child_class”,其文件名应该为child_class.pp;
2、无需在资源清单文件中使用import语句;
3、manifests目录下可存在多个清单文件,每个清单文件包含一个类,其文件名同类名;