案例:通过分析与预测空气质量指数AQI学习统计分析(下)
申明:文章内容是作者自己的学习笔记,教学来源是开课吧讲师梁勇老师。
不要杠,开心学习!
讲师介绍:梁老师 《细说Java》与《Java深入解析》图书作者。一线互联网资深数据分析专家,超过十年软件开发与培训经验。精通Python与Java开发,擅长网络爬虫,数据分析与可视化,机器学习,自然语言处理等技术。曾参与阿里云大学数据分析,机器学习,自然语言处理等课程开发与认证设计,担任阿里云学院导师。
进入正文:
接着上一篇的内容,我们继续学习数据分析师用到的统计学的内容。
本篇博客包括学习:
散点图矩阵、相关系数、单样本t检验、基模型、特征选择、分箱操作以及残差图。
让我们继续开始对AQI的分析与预测吧!
AQI分析与预测(下)
- 5.4 空气质量主要受哪些因素的影响?
- 5.4.1 散点图矩阵
- 什么是散点图矩阵?
- 5.4.2 相关系数
- 5.4.2.1 协方差定义
- 5.4.2.2 相关系数定义
- 5.4.3 结果统计
- 5.5 关于空气质量的验证
- 什么是单样本 t 检验?
- 5.6 对空气质量进行检测
- 5.6.1 数据转换
- 5.6.2 基模型
- 5.6.3 特征选择
- 5.6.3.1 RFECV(递归特征消除)
- 5.7 异常的值处理
- 5.7.1 使用临界值替换
- 5.7.2 效果对比
- 5.7.3 分箱操作
- 5.8 残差图分析
- 5.8.1 异方差性
- 5.8.2 离群点
- 6、总结

5.4 空气质量主要受哪些因素的影响?
对于空气质量,我们很可能会关注这个问题,例如,我们可能会产生如下的疑问:
- 人口密度大,是否会对空气质量造成负面影响?
- 绿化率高,是否会提高空气质量?
我们可以通过画图进行查看:
5.4.1 散点图矩阵
什么是散点图矩阵?
散点图矩阵图是可用于比较多个数据集以查找模式和关系。
散点图矩阵是将任意两个变量之间的关系都以散点图的形式(一个二维平面图)绘制出来。
这里我们只选取空气质量指数AQI、人口密度PopulationDensity和绿化覆盖率GreenCoverageRate来进行绘制。
通过seaborn的pairplot来绘制散点图:
sns.pairplot(data[["AQI", "PopulationDensity", "GreenCoverageRate"]])
# sns.pairplot(data[["AQI", "PopulationDensity", "GreenCoverageRate"]], kind="reg")

图中对脚线发现不是散点图,因为横纵坐标的对脚线处是一个变量,一个变量的话就不会给我们绘制散点图了而是直方图。
通过散点图我们可以大致看出每两个变量之间的关系。但是从上面的图中我们还不是特别容易清晰的看出变量之间的关系,我们可以通过一种量化的方式来解决,那就是我们可以计算一下相关系数,相关系数就是衡量两个变量之间的相关性。
5.4.2 相关系数
5.4.2.1 协方差定义

协方差体现的是两个变量之间的分散性以及两个变量变化步调是否一致。容易得知,当协方差的两个变量相同时,协方差就是方差。
通俗的理解:
两个变量在变化过程中是同方向变化?还是反方向变化?同向或反向程度如何?

5.4.2.2 相关系数定义
相关系数,可以用来体现两个连续变量之间的相关性,最为常用的为皮尔逊相关系数。 两个变量的相关系数定义为:

公式含义:就是用X、Y的协方差除以X的标准差和Y的标准差。
统计学中常用相关系数 r 来表示两变量之间的相关关系。
相关系数 r 的取值范围为[-1,1],我们可以根据相关系数的取值来衡量两个变量的相关性:

r为正时是正相关,反映当x增加(减少)时,y随之相应增加(减少);呈正相关的两个变量之间的相关系数一定为正值,这个正值越大说明正相关的程度越高。
r为负时是负相关,反映当x增加(减少)时,y 会相反的减少(增加);呈负相关的两个变量之间的相关系数一定为负数。
我们以空气质量(AQI)与降雨量(Precipitation)为例,计算二者的相关系数。
先计算一下二者的协方差和相关系数:
x = data["AQI"]
y = data["Precipitation"]
# 计算AQI与Precipitation的协方差。
a = (x - x.mean()) * (y - y.mean())
cov = np.sum(a) / (len(a) - 1)
print("协方差:", cov)
# 计算AQI与Precipitation的相关系数。
corr = cov / np.sqrt(x.var() * y.var())
print("相关系数:", corr)
结果:
协方差: -10278.683921772239
相关系数: -0.40159811621922753
我们有最简便的求协方差和相关系数的方法:
通过
Series.cov( )方法来计算协方差;
通过Series.corr( )方法来计算相关系数;
print("协方差:", x.cov(y))
print("相关系数:", x.corr(y))
结果:
协方差: -10407.167470794398
相关系数: -0.4043784360785916
不过,DataFrame对象提供了计算相关系数的方法,我们可以直接使用。
data.corr()
将data中所有变量两两一组求出他们的相关系数。
结果:

为了能够更清晰的呈现相关数值,我们可以使用热力图来展示相关系数。
plt.figure(figsize=(15, 10))
ax = sns.heatmap(data.corr(), cmap=plt.cm.RdYlGn, annot=True, fmt=".2f")
注意: Matplotlib 3.1.1版本的bug,heatmap的首行与末行会显示不全。
可手动调整y轴的范围来进行修复。(老版本的Matplotlib不需要调整y轴范围。)
手动调整代码:
a, b = ax.get_ylim()
ax.set_ylim(a + 0.5, b - 0.5)
使用seaborn中的heatmap( )制作热力图。
cmap=plt.cm.RdYlGn 指定颜色,此处指定的是绿色到红色。
annot=True 显示数字。
fmt=".2f" 保留两位小数。
结果:
 从图中可以看到,维度Latitude 对AQI 的相关性是最大的,为0.55。是正相关,也就意味着,随着维度的增大AQI也是增大的,越往北维度越大,AQI就越大,AQI越大意味着空气质量越差,所以南方空气要比北方空气要好。
从图中可以看到,维度Latitude 对AQI 的相关性是最大的,为0.55。是正相关,也就意味着,随着维度的增大AQI也是增大的,越往北维度越大,AQI就越大,AQI越大意味着空气质量越差,所以南方空气要比北方空气要好。
5.4.3 结果统计
从结果可知,空气质量指数主要受降雨量(-0.40)与维度(0.55)影响。
- 降雨量越多,空气质量越好。
- 维度越低,空气质量越好。
此外,我们还能够发现其他一些明显的细节:

5.5 关于空气质量的验证
江湖传闻,全国所有城市的空气质量指数均值在71左右,请问,这个消息可靠吗?

城市平均空气质量指数,我们可以很容易的进行计算:
计算均值:
data["AQI"].mean()
结果:
75.3343653250774
该需求是要验证样本均值是否等于总体均值,根据场景,我们可以使用单样本 t 检验,置信度为95%。
r = stats.ttest_1samp(data["AQI"], 71)
print("t值:", r.statistic)
print("p值:", r.pvalue)
这里检验AQI空气质量的均值与71是否显著。
结果:

我们可以看到,P值大于0.05,故我们无法拒绝原假设,因此接受原假设。
什么是单样本 t 检验?
使用
ttest_1samp()函数可以进行单样本T检验,比如检验一列数据的均值与1的差异是否显著。
stats.ttest_1samp(data,1)
返回结果会返回t值和p值。

这里为什么不是选择A选项,我们要清楚,±1.96倍的标准差,是正态分布在置信度为95%下的临界值,严格来说,对 t 分布不是如此。只不过,当样本容量较大时,t 分布近似于正态分布。当样本容量比较小时,二者会有较大的差异。
我们可以获取更加准确的置信区间:
mean = data["AQI"].mean()
std = data["AQI"].std()
stats.t.interval(0.95,df=len(data)-1,loc=mean,scale=std/np.sqrt(len(data)))
结果:
![]()
由此,我们就计算出全国所有城市平均空气质量指数,95%的可能大致在71.05~80.57之间。
5.6 对空气质量进行检测
对于某城市,如果我们已知降雨量,温度,经纬度等指标,我们是否能够预测该城市的空气质量指数呢?答案是肯定的。如果我们通过对以往的数据,去建立一种模式,然后这种模式去应用于未知的数据,进而预测结果。
5.6.1 数据转换
对于模型来说,内部进行的都是数学上的运算。在进行建模之前,我们需要首先进行转换,将类别变量转换为离散变量。
data数据中是否是沿海城市这一列是类别变量,所以我们需要将其进行转换:
data["Coastal"] = data["Coastal"].map({"是": 1, "否": 0})
data["Coastal"].value_counts()
结果:内陆城市(0)有245个,沿海城市(1)有80个。

5.6.2 基模型
首先,我们不进行任何处理,建立一个模型。后续的操作,可以在此基础上进行改进。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X = data.drop(["City","AQI"], axis=1)
y = data["AQI"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lr = LinearRegression()
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
结果:

训练集0.45,测试集0.40 。
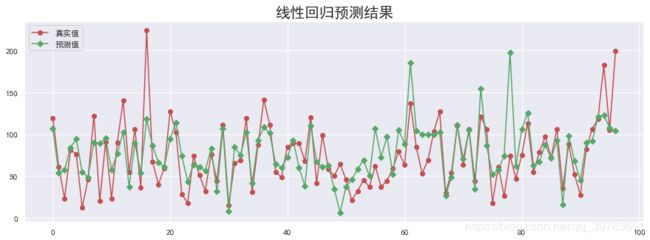
接下来绘制下预测的结果:
y_hat = lr.predict(X_test)
plt.figure(figsize=(15, 5))
plt.plot(y_test.values, "-r", label="真实值", marker="o")
plt.plot(y_hat, "-g", label="预测值", marker="D")
plt.legend(loc="upper left")
plt.title("线性回归预测结果", fontsize=20)
![]()
5.6.3 特征选择
刚才,我们使用所有可能的原始数据作为特征,建立模型,然而,特征并非越多越好,有些特征可能对模型质量并没有什么改善,我们可以进行删除,同时,也能够提高模型训练速度。
5.6.3.1 RFECV(递归特征消除)

from sklearn.feature_selection import RFECV
# estimator: 要操作的模型。
# step: 每次删除的变量数。
# cv: 使用的交叉验证折数。
# n_jobs: 并发的数量。
# scoring: 评估的方式。
rfecv = RFECV(estimator=lr, step=1, cv=5, n_jobs=-1, scoring="r2")
rfecv.fit(X_train, y_train)
# 返回经过选择之后,剩余的特征数量。
print("返回经过选择之后,剩余的特征数量",rfecv.n_features_)
# 返回经过特征选择后,使用缩减特征训练后的模型。
print("返回经过特征选择后,使用缩减特征训练后的模型",rfecv.estimator_)
# 返回每个特征的等级,数值越小,特征越重要。
print("返回每个特征的等级,数值越小,特征越重要",rfecv.ranking_)
# 返回布尔数组,用来表示特征是否被选择。
print("返回布尔数组,用来表示特征是否被选择",rfecv.support_)
# 返回对应数量特征时,模型交叉验证的评分。
print("返回对应数量特征时,模型交叉验证的评分",rfecv.grid_scores_)
结果:

结果[1 2 1 1 1 1 3 1 1 1]中,特征1就是索引为0的变量,按索引0开始排序。特征等级越小越重要,这里的2和3对应的两个变量就不是很重要了。
False表示对应的特征没有用到。
通过结果可知,我们成功删除了两个特征。我们可以绘制下,在特征选择过程中,使用交叉验证获取的R²值。
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, marker="o")
plt.xlabel("特征数量")
plt.ylabel("交叉验证$R^2$值")
结果:

然后,我们对测试集应用这种特征选择(变换),进行测试,获取测试结果。
print("剔除的变量:", X_train.columns[~rfecv.support_])
X_train_eli = rfecv.transform(X_train)
X_test_eli = rfecv.transform(X_test)
print(rfecv.estimator_.score(X_train_eli, y_train))
print(rfecv.estimator_.score(X_test_eli, y_test))
结果:

我们发现,经过特征选择后,消除了GDP与PopulationDensity两个特征,而使用剩余8个特征训练的模型,与之前未消除特征训练的模型(使用全部10个特征训练的模型),无论在训练集还是测试集的表现上,都几乎相同,这就可以证明,我们清除的这两个特征,确实对拟合目标(y值)没有什么帮助,可以去掉。
5.7 异常的值处理
如果数据中存在异常值,很有可能会影响模型的效果,因此,我们在建模之间,非常有必要对异常值进行处理。
5.7.1 使用临界值替换
我们可以依据箱线图判断群点的原则去探索异常值,然后使用临界值替换掉异常值。
我们应该使用什么数据去计算临界值呢?
答案是:训练集(X_train)
因为对于测试集来说对我们永远都是未知的效果。也就是在我们训练期间永远不能使用测试集。
# Coastal是类别变量,映射为离散变量,不会有异常值。
for col in X.columns.drop("Coastal"):
if pd.api.types.is_numeric_dtype(X_train[col]):
quartile = np.quantile(X_train[col], [0.25, 0.75])
IQR = quartile[1] - quartile[0]
lower = quartile[0] - 1.5 * IQR
upper = quartile[1] + 1.5 * IQR
X_train[col][X_train[col] < lower] = lower
X_train[col][X_train[col] > upper] = upper
X_test[col][X_test[col] < lower] = lower
X_test[col][X_test[col] > upper] = upper
5.7.2 效果对比
去除异常值后,我们使用新的训练集与测试集来评估模型的效果。
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
结果:

效果相对于之前,似乎有着轻微的改进,不过并不明显,我们可以使用RFECV在去除异常值的数据上,再次尝试。
rfecv = RFECV(estimator=lr, step=1, cv=5, n_jobs=-1, scoring="r2")
rfecv.fit(X_train, y_train)
print("返回经过选择之后,剩余的特征数量",rfecv.n_features_)
print("返回每个特征的等级,数值越小,特征越重要",rfecv.ranking_)
print("返回布尔数组,用来表示特征是否被选择",rfecv.support_)
print("返回对应数量特征时,模型交叉验证的评分",rfecv.grid_scores_)
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, marker="o")
plt.xlabel("特征数量")
plt.ylabel("交叉验证$R^2$值")
结果:


print("剔除的变量:", X_train.columns[~rfecv.support_])
# X_train_eli = rfecv.transform(X_train)
# X_test_eli = rfecv.transform(X_test)
# 为了方便后面列的筛选操作,这里我们换一种方式转换。
X_train_eli = X_train[X_train.columns[rfecv.support_]]
X_test_eli = X_test[X_test.columns[rfecv.support_]]
print(rfecv.estimator_.score(X_train_eli, y_train))
print(rfecv.estimator_.score(X_test_eli, y_test))
结果:

5.7.3 分箱操作
注意:
分箱后,我们不能将每个区间映射为离散数值,而是应当使用One-Hot编码。
from sklearn.preprocessing import KBinsDiscretizer
# KBinsDiscretizer K个分箱的离散器。用于将数值(通常是连续变量)变量进行区间离散化操作。
# n_bins:分箱(区间)的个数。
# encode:离散化编码方式。分为:onehot,onehot-dense与ordinal。
# onehot:使用独热编码,返回稀疏矩阵。
# onehot-dense:使用独热编码,返回稠密矩阵。
# ordinal:使用序数编码(0,1,2……)。
# strategy:分箱的方式。分为:uniform,quantile,kmeans。
# uniform:每个区间的长度范围大致相同。
# quantile:每个区间包含的元素个数大致相同。
# kmeans:使用一维kmeans方式进行分箱。
k = KBinsDiscretizer(n_bins=[4, 5, 14, 6], encode="onehot-dense", strategy="uniform")
# 定义离散化的特征。
discretize = ["Longitude", "Temperature", "Precipitation", "Latitude"]
r = k.fit_transform(X_train_eli[discretize])
r = pd.DataFrame(r, index=X_train_eli.index)
# 获取除离散化特征之外的其他特征。
X_train_dis = X_train_eli.drop(discretize, axis=1)
# 将离散化后的特征与其他特征进行重新组合。
X_train_dis = pd.concat([X_train_dis, r], axis=1)
# 对测试集进行同样的离散化操作。
r = pd.DataFrame(k.transform(X_test_eli[discretize]), index=X_test_eli.index)
X_test_dis = X_test_eli.drop(discretize, axis=1)
X_test_dis = pd.concat([X_test_dis, r], axis=1)
# 查看转换之后的格式。
display(X_train_dis.head())
代码解析:
KBinsDiscretizerK个分箱的离散器。用于将数值(通常是连续变量)变量进行区间离散化操作。
n_bins:分箱(区间)的个数。
encode:离散化编码方式。分为:onehot,onehot-dense与ordinal。
onehot:使用独热编码,返回稀疏矩阵。
onehot-dense:使用独热编码,返回稠密矩阵。
ordinal:使用序数编码(0,1,2……)。
strategy:分箱的方式。分为:uniform,quantile,kmeans。
uniform:每个区间的长度范围大致相同。
quantile:每个区间包含的元素个数大致相同。
kmeans:使用一维kmeans方式进行分箱。
结果:

这样,我们就可以对转换后的数据进行训练了。
lr.fit(X_train_dis, y_train)
print(lr.score(X_train_dis, y_train))
print(lr.score(X_test_dis, y_test))
结果:

离散化后,模型效果有了进一步的提升。
注意:
此时,x对y阶梯式的影响用分箱操作。
5.8 残差图分析
残差,就是模型预测值与真实值之间的差异。
我们可以绘制残差图,来对回归模型进行评估。
残差图的横坐标为预测值,纵坐标为残差值。
5.8.1 异方差性
对于一个好的回归模型,误差应该是随机分配的。因此,残差也应随机分布于中心线附近。如果我们从残差图中找出规律,这意味着模型遗漏了某些能够影响残差的解释信息。
异方差性,是指残差具有明显的方差不一致性。这里我们异常值处理前后的两组数据,分别训练模型,然后观察残差的效果。
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(15, 5)
data = [X_train, X_train_dis]
title = ["原始数据", "处理后数据"]
for d, a, t in zip(data, ax, title):
model = LinearRegression()
model.fit(d, y_train)
y_hat_train = model.predict(d)
residual = y_hat_train - y_train.values
a.set_xlabel("预测值")
a.set_ylabel(" 残差")
a.axhline(y=0, color="red")
a.set_title(t)
sns.scatterplot(x=y_hat_train, y=residual, ax=a)
结果:
在左图中我们发现,随着预测值的增大,模型的误差也在增大,对于此种情况,我们可以使用对目标y值取对数的方式处理。
model = LinearRegression()
y_train_log = np.log(y_train)
y_test_log = np.log(y_test)
model.fit(X_train, y_train_log)
y_hat_train = model.predict(X_train)
residual = y_hat_train - y_train_log.values
plt.xlabel("预测值")
plt.ylabel(" 残差")
plt.axhline(y=0, color="red")
sns.scatterplot(x=y_hat_train, y=residual)
结果:

此时,异方差性得到解决。同时,模型的效果也可能会得到一定的提升。
5.8.2 离群点
![]()
然而,我们可以通过绘制残差图,通过预测值和实际值之间的关系,来检测离群点。
y_hat_train = lr.predict(X_train_dis)
residual = y_hat_train - y_train.values
r = (residual - residual.mean()) / residual.std()
plt.xlabel("预测值")
plt.ylabel(" 残差")
plt.axhline(y=0, color="red")
sns.scatterplot(x=y_hat_train[np.abs(r) <= 2], y=residual[np.abs(r) <= 2], color="b", label="正常值")
sns.scatterplot(x=y_hat_train[np.abs(r) > 2], y=residual[np.abs(r) > 2], color="orange", label="异常值")
结果:

X_train_dis_filter = X_train_dis[np.abs(r) <= 2]
y_train_filter = y_train[np.abs(r) <= 2]
lr.fit(X_train_dis_filter, y_train_filter)
print(lr.score(X_train_dis_filter, y_train_filter))
print(lr.score(X_test_dis, y_test))
结果:

6、总结
