机器学习实战(五) kaggle练习赛 泰坦尼克获救预测
这道题的主页:https://www.kaggle.com/c/titanic
目录
一、 读取数据,观察数据分布
二、 数据预处理
1. 填充缺失值
2. 文字到数值的映射
三、模型
1. 用线性回归预测
2. 用逻辑回归预测
3. 用随机森林改进模型
四、特征工程示例
1. 如何自己构造特征
2. 随机森林特征重要性分析
一、 读取数据,观察数据分布
import numpy as np
import pandas as pd
import matplotlib as plt
import math
titanic=pd.read_csv('train.csv')
print(titanic.describe())#查看每一列的情况
titanic.head()
print(titanic.shape)#(891, 12)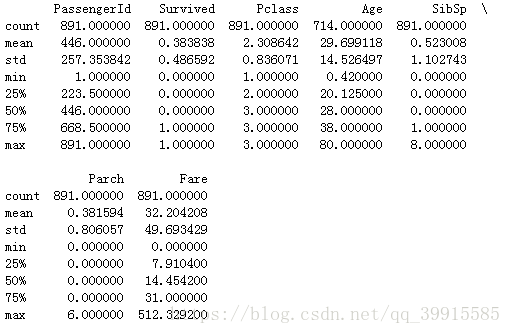


分析:survived这一列,1-存活,0-死亡
sex:是文字形式,不利于分析,故可能需要映射到数值的值
age:这一列空缺了一百多个值,从逻辑上考虑年龄还是很重要的,所以缺失值需要填补
Ticket:这列船票号,看起来没啥规律。。。
Fare:船票费用和船舱等级(Pclass)以及航程长短(Embarked)有关,先不处理
Cabin:这个缺失值太多了,先忽略
Embarked:上船港口,有三个取值,C/S/Q,是文字形式,不利于分析,故可能需要映射到数值的值,而且有2个缺失值
二、 数据预处理
1. 填充缺失值
可以采取:平均值/中值/众数等填充方式。
Age这列平均值和中值都可以考虑一下(看具体效果决定),Embarked就缺了俩,而且取值就3个离散值,故用众数比较合理。
(1)Age
titanic['Age']=titanic['Age'].fillna(titanic['Age'].mean()) #用均值(29.69911764705882)填充,如果是中值的话,就是median()
# titanic['Age']=titanic['Age'].fillna(titanic['Age'].median()) #用中值( 28.0)填充
print(titanic['Age'].describe())#查看每一列的情况
(2)Embarked
# 将上船港口映射到数值
print(titanic['Embarked'].unique()) #取值可能的结果:['S' 'C' 'Q' nan]
print(titanic['Embarked'].mode()) #'众数'是s,那就用s
titanic['Embarked']=titanic['Embarked'].fillna('S')
print(titanic['Embarked'].describe())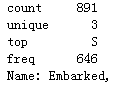
可以看到已经将缺失值填充上了,其实在.describe()的top中就可以看到众数的取值了,top:S
2. 文字到数值的映射
(1)性别:male-0, female-1
# 将Sex这一栏,男用0表示,女用1表示
titanic.loc[titanic['Sex']=='male','Sex']=0
titanic.loc[titanic['Sex']=='female','Sex']=1
print(titanic['Sex'].describe())
(2)港口:S-0, C-1, Q-2
titanic.loc[titanic['Embarked']=='S','Embarked']=0
titanic.loc[titanic['Embarked']=='C','Embarked']=1
titanic.loc[titanic['Embarked']=='Q','Embarked']=2
print(titanic['Embarked'].describe())
三、模型
1. 用线性回归预测
(1)线性回归:找到一条直线(超平面)来拟合数据点
(2)本案例中,找到拟合平面之后求解每个人的存活概率,若大于0.5 则存活,survived预测值=1,好残忍
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
# print(help(KFold))
predictors=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked'] #用于预测的项,【有改进的空间】
alg=LinearRegression()
kf=KFold(titanic.shape[0],n_folds=3, random_state=1)
# print(help(np.concatenate))
predictions=[]
for train,test in kf:
train_predictors=(titanic[predictors].iloc[train,:])
train_target=titanic['Survived'].iloc[train]
alg.fit(train_predictors,train_target)
test_predictions=alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)
predictions=np.concatenate(predictions,axis=0) #在行的方向拼接两个数组
# print(help(np.concatenate))
predictions[predictions>0.5]=1
predictions[predictions<=0.5]=0
accuracy=len(predictions[predictions==titanic['Survived']])/(len(predictions)) #预测的情况与实际情况一致的数目/所有样本数
print(accuracy) #结果:0.78338945005611672. 用逻辑回归预测
# 逻辑回归
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
predictors=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
alg=LogisticRegression(random_state=1)
scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=3)
print(scores.mean()) #0.79012345679012343. 用随机森林改进模型
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
predictors=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked'] #用于预测的项,【有改进的空间】
#n_estimators 森林中树的数目
rf_alg=RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2)
kf=cross_validation.KFold(titanic.shape[0],n_folds=3, random_state=1)
scores=cross_validation.cross_val_score(rf_alg,titanic[predictors],titanic['Survived'],cv=kf)
print(scores) #[0.78114478 0.82491582 0.84175084]
print(scores.mean()) #0.8159371492704826对比可以发现,平均分数有所提高,说明预测得准一些了
四、特征工程示例
1. 如何自己构造特征
目的是演示一下怎么构造特征,别当真。。。
(1)FamilySize = SibSp + ParCh
(2)NameLength = len (Name)
titanic['FamilySize']=titanic['SibSp']+titanic['Parch']
titanic['Namelength']=titanic['Name'].apply(lambda x:len(x)) #匿名函数,允许快速定义单行函数(3)Titles = 一些特殊的称号。例如:miss / doctor / professor......
import re #re 模块使 Python 语言拥有全部的正则表达式功能。
def get_title(name):
title_search=re.search(' ([A-Za-z]+)\.',name) #re.search 扫描整个字符串并返回第一个成功的匹配。name是要进行检索的,前面是要匹配的
if title_search:
return title_search.group(1) #查看匹配的情况
return ""
titles=titanic['Name'].apply(get_title)
print(pd.value_counts(titles))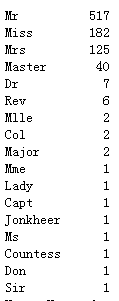
提取出的title有这么多种,而且都是文字信息,为了便于分析,要将其映射到数值,这次采用一种批量的方法:
title_mapping={'Mr':1,'Miss':2,'Mrs':3,'Master':4,'Dr':5,'Rev':6,'Major':7,'Mlle':7,'Col':7,'Jonkheer':8,'Capt':8,'Don':8,'Mme':8,'Sir':8,'Lady':8,'Ms':8,'Countess':8}
for k,v in title_mapping.items():
titles[titles==k]=v
print(pd.value_counts(titles))
titanic['Titles']=titles结果:

2. 随机森林特征重要性分析
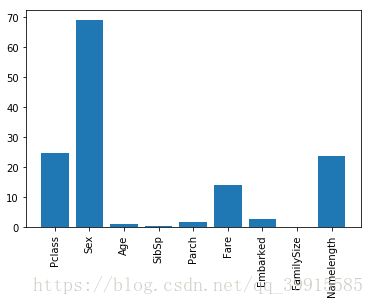
from sklearn.feature_selection import SelectKBest, f_classif
import matplotlib.pyplot as plt
predictors2=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked','FamilySize','Namelength'] #'Titles',放里面会有麻烦
selector=SelectKBest(f_classif,k=5)
selector.fit(titanic[predictors2],titanic['Survived'])
scores=-np.log10(selector.pvalues_)
plt.bar(range(len(predictors2)),scores)
plt.xticks(range(len(predictors2)),predictors2,rotation='vertical')
plt.show()