Session-basedRecommendationwithGraphNeuralNetworks论文笔记
摘要
基于会话的推荐问题旨在预测基于匿名会话的用户行为.以前的算法不能保证获得准确的向量,在保证嵌入精度的基础上,考虑到项目的复杂转换,提出了一种新的嵌入方法,SR-GNN/该方法将会话序列建模为图结构数据。基于会话图,GNN可以捕获复杂的项目转换,这是传统顺序方法难以揭示的。然后,使用注意力网络将每个会话表示为全局偏好和该会话当前兴趣的组成。
传统方法的局限性
- 首先,由于在一个会话中没有足够的用户行为,这些方法难以估计用户表示。通常将这些RNN方法的隐藏向量作为用户表示,然后根据这些表示生成推荐,例如NARM的全局推荐。在基于会话的推荐系统中,会话大多是匿名的,而且数量众多,而会话点击所涉及的用户行为往往是有限的。因此,很难准确地估计每个会话中每个用户的表示形式
- 之前的工作揭示了项目转换的模式是重要的,可以用作局部因素(Li et al. 2017a;Liu等人(2018)在基于会话的推荐中,但是这些方法总是对连续项之间的单向转换建模,而忽略了上下文之间的转换。因此,这些方法常常忽略了遥远项目之间的复杂转换
为了克服上述局限性,我们提出了一种新的基于会话的基于图神经网络的推荐方法SR-GNN,探索了项目之间丰富的转换,并生成了准确的项目潜在向量。
- 我们首先从历史会话序列构造有向图。基于会话图,GNN能够捕获项目的转换,并相应地生成精确的项目嵌入向量,这是传统的序列方法难以显示的
- 基于精确的项目嵌入向量,提出的SR-GNN构造了更可靠的会话表示,可以推断出下一步单击的项目
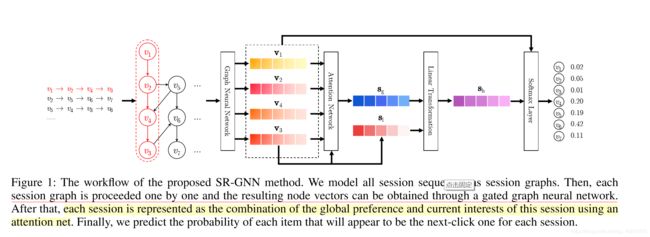
首先,将所有会话序列建模为前向session 图,其中每个会话序列都可以被视为一个ubgraph。然后依次进行每个会话图,通过门控图神经网络得到每个图中所有节点的潜在向量。然后,我们将每个会话表示为全局首选项和用户当前对该会话的兴趣的组合,其中这些全局和本地会话嵌入向量都由节点的潜在向量组成。最后,对于每个会话,我们预测每个条目成为下一个cli的概率
主要贡献:
- 我们将分离的会话序列建模为图结构数据,并使用图神经网络捕获复杂的项目转换。据我们所知,它为基于会话的推荐场景中的建模提供了一个新的视角。
- 为了生成基于会话的建议,我们不依赖于用户表示,而是使用会话嵌入,它仅可以根据每个会话中涉及的项的潜在向量获得。
model
notations
令V = {v1,v2,…表示由所有会话中涉及的所有惟一项组成的集合。
匿名会话序列s可以用列表s = [vs,1,vs,2,…,vs,n]按时间戳排序,其中vs,i∈V表示会话s内用户点击的项。基于会话的推荐的目标是预测下一个点击,即会话s的序列标签vs,n+1。在一个基于会话的推荐模式下,对于一个特定的session s,我们为所有可能的输出概率ˆy项目,其中的元素值向量ˆy是推荐相应条目的得分。y 值的前K个条目是推荐项目的候选项。
construction session graphs 类 PageRank
每一个session 序列可以被建模成一个有向图,在这个session 图中,每个节点表示一个item,每一个边(vs,i−1,vs,i) ∈Es 意味着用户在 vs,i−1后点击 vs,i 。由于序列中可能出现多个重复项,所以我们给每条边分配一个归一化加权,计算为该边的出现次数除以该边的起始节点的输出次数,也就是从这个点引出的边的总数。我们将每一项v∈v嵌入到一个统一的嵌入空间中,节点向量v∈Rd表示通过图神经网络学习到的项v的潜在向量,其中d为维数。基于节点向量,每个会话s可以表示为一个嵌入向量s,该嵌入向量由该图中使用的节点向量组成。
implementing graph neural networks with session graphs
我们提出了一种利用图神经网络获取节点潜在向量的方法。图神经网络能够在考虑丰富节点连接的情况下自动提取会话图的特征,非常适合基于会话的推荐。我们首先演示了会话图中节点向量的学习过程。形式上,对于graphGs的节点vs,i,更新函数如下:
。
连接矩阵As∈Rn×2n决定了图中节点之间如何通信,As,i:∈Rn×2是As中对应于节点vs,i的两列块。这里As定义为两个邻接矩阵a (out) s和a (in) s的连接,它们分别表示会话图中传出和传入边的加权连接。请注意sr - gnn可以支持不同的连接矩阵A用于各种构造的会话图,如果使用不同的构造会话图的策略,连接矩阵As也会随之改变。当节点存在描述和分类信息等内容特征时,该方法可以进一步推广。具体来说,我们可以将nodevector的特性连接起来来处理这些信息。
第一个等式用来在不同的节点之间信息传播,在矩阵a给出的条件下。具体来说,它提取邻域的潜在向量,并将其作为输入输入到图神经网络中。然后,两个门,即更新和重置门,分别决定保存和丢弃哪些信息。然后,我们按照式(4)中描述的前一个状态、当前状态和复位门构造候选状态。最后的状态是之前隐藏状态和候选状态的组合,由更新门控制。通过对会话图中所有节点进行更新直至收敛,得到最终的节点向量。
generating session embedding vectors
以前基于会话的推荐方法总是假定每个会话都有一个用户的不同潜在表示形式,正相反,SR-GNN没有对这个向量做任何假设。相反,会话直接由会话中涉及的节点表示。为了更好地预测用户的下一次点击量,我们计划开发一种策略,将长期偏好和当前会话兴趣结合起来,并使用这个组合embedding作为会话embedding。
将所有会话图输入门控图神经网络后,得到所有节点的向量。然后,为了将每个会话表示为一个嵌入向量s∈Rd,我们首先考虑会话的局部embedding s1。对于session s = [vs,1,vs,2,…,vs,n],,局部的embedding可以便是为vsn的最后一个点击项vn,. sl = vn
然后,我们通过聚合所有的函数来全局嵌入分解图的sg,考虑到这些嵌入的信息可能有不同的优先级,我们进一步采用soft- attention 机制 来更好地表示全局会话偏好。

q ∈Rd and W1,W2 ∈Rd×d ,控制权重。
最后,通过对局部和全局嵌入向量的串联进行线性变换,计算混合嵌入sh:
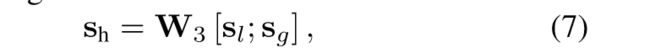
其中矩阵W3∈Rd×2d将两个组合嵌入向量压缩到潜在空间 ** d** 中。
推荐
获得每个会话的嵌入后,我们计算每个候选项的得分ˆ,通过每个首选item vi∈V 与 嵌入vi会话表示sh相乘,可以定义为:

最后加入一个softmax/函数来得到最后输出向量

最后使用cross entropy 损失函数。
其中groundtruth y 是一个one-hot向量。
为了训练模型,首先聚合领域的信息,然后使用GRUs更新节点状态。
在实际部署方面,推荐人可以分为线下和线上两部分。离线部分学习项目嵌入,不需要实时更新,而在线部分只负责预测,可以实时完成
。
评测指标
P@20 (Precision)被广泛用作预测精度的度量。它表示前20个项目中正确推荐的项目所占的比例
MRR@20(平均倒数排名)是正确推荐项目倒数排名的平均值。超过20该值将会设置为0。TheMRR度量考虑推荐排名的顺序,其中较大的MRR值表示正确的推荐位于排名列表的顶部。