四种归一化方法BN,LN,IN,GN的比较
1.计算方法的不同
BatchNorm:batch方向做归一化,算NHW的均值
LayerNorm:channel方向做归一化,算CHW的均值。为了能够在只有当前一个训练实例下,找到一个合理的统计范围,一个直接的想法是:把同一个卷积层作为集合,求均值和方差;对于RNN,就是把同层隐层神经元的响应值(不同时刻)作为集合,再求均值和方差。
InstanceNorm:一个channel内做归一化,算H*W的均值。LN是对所有的通道,那对一个通道做归一化就是IN,单个通道的feature map作为集合,并在此集合上求均值和方差,这种像素级上的操作,使得IN对于一些图片生成类的任务效果明显优于BN,比如图片风格转换。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值。LN是对于所有的通道,IN是对于单个通道,如果把所有通道分组,再各个组上做归一化,这就是GN。通道分组也是CNN常用的优化技巧。GN在mini-batch比较小的场景或者物体检测、视频分类等场景下效果优于BN。
2.各个归一化方法在pytorch里的函数
- class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
- class torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
- class torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
- class torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
3.实验验证各个方法的效果
在cifar10数据集,用VGG16网络,只改变batchsize和归一化的函数,各个归一化方法的效果(时间单位是秒):
BN :
BatchSize=128时,epoch = 10,train acc = 88.378%,test acc = 84.810%,每个epoch时间= 12.721679000000002
BatchSize=32时,epoch = 20,train acc = 85.792%,test acc = 84.470%,每个epoch时间= 26.749455000000125
BatchSize=16时,epoch = 20,train acc = 80.408%,test acc = 79.260%,每个epoch时间= 44.35883400000057
BatchSize=8时,epoch = 20,train acc = 71.272%,test acc = 73.980%,每个epoch时间= 44.35883400000057
BatchSize=2时,epoch = 10,train acc = 10.206%,test acc = 10.000%,每个epoch时间= 252.75724199999968
LN :
BatchSize=128时,epoch = 20,train acc = 39.910%,test acc = 40.640%,每个epoch时间= 14.66833500000007
BatchSize=32时,epoch = 20,train acc = 42.656%,test acc = 45.210%,每个epoch时间= 28.20246999999995
BatchSize=16时,epoch = 20,train acc = 45.124%,test acc = 47.940%,每个epoch时间= 45.411011000000144
BatchSize=8时,epoch = 20,train acc = 10.106%,test acc = 10.000%,每个epoch时间= 44.35883400000057
IN :
BatchSize=128时,epoch = 20,train acc = 78.782%,test acc = 78.580%,每个epoch时间= 24.77383199999997
BatchSize=32时,epoch = 20,train acc = 9.916%,test acc = 10.000%,每个epoch时间= 36.15033500000004
BatchSize=16时,epoch = 20,train acc = 10.206%,test acc = 10.000%,每个epoch时间= 45.411011000000144
BatchSize=8时,epoch = 20,train acc = 9.132%,test acc = 10.000%,每个epoch时间= 44.35883400000057
GN:
BatchSize=128时,epoch = 25,train acc = 80.814%,test acc = 79.170% ,每个epoch时间= 17.03963599999952
BatchSize=32时,epoch = 20,train acc = 76.910%,test acc = 76.350%,每个epoch时间= 33.00318700000025
BatchSize=16时,epoch = 20,train acc = 70.296%,test acc = 69.810% ,每个epoch时间= 49.40261599999985
BatchSize=8时,epoch = 20,train acc = 9.736%,test acc = 10.000%,每个epoch时间= 44.35883400000057
BatchSize=2时,epoch = 20,train acc = 10.206%,test acc = 10.000%,每个epoch时间= 279.5916789999992
4.总结
在每个方法内,一般是batch越大,相同的epoch内正确率越高(层归一化LN不是这个规律),相同的batchsize下,批归一化BN效果最好,按理说batchsize为个位数时,组归一化GN的效果应该比BN好,但在我的实验过程中,由于数据自身原因,在10%左右有一段平台期,而GN比较难以跨过这段平台期,猜测一旦跨过平台期,GN的效果就会优于BN,由于batch size为个位数时,每个epoch的训练时间过长,因此这一猜测还有待后续验证
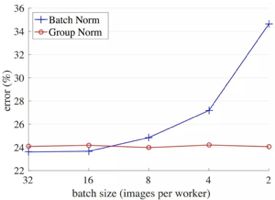
GN的论文中和BN的比较图:
5.实验代码
import torch
import torch.nn as nn
from torch.autograd import Variable
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
}
# 模型需继承nn.Module
class VGG(nn.Module):
# 初始化参数:
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 10)
# 模型计算时的前向过程,也就是按照这个过程进行计算
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
size = 32
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
size = int(size/2)
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
#nn.GroupNorm(int(x/2), x),
#nn.LayerNorm([x,size,size]),
#nn.InstanceNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
from __future__ import print_function
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
import os
import argparse
from torch.autograd import Variable
# 获取参数
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--lr', default=0.02, type=float, help='learning rate')
args = parser.parse_args(args=[])
use_cuda = torch.cuda.is_available()
best_acc = 0 # best test accuracy
start_epoch = 0 # start from epoch 0 or last checkpoint epoch
# 获取数据集,并先进行预处理
print('==> Preparing data..')
# 图像预处理和增强
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
print('==> Building model..')
net = VGG('VGG16')
# 如果GPU可用,使用GPU
if use_cuda:
# move param and buffer to GPU
net.cuda()
# speed up slightly
cudnn.benchmark = True
# 定义度量和优化
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
# 训练阶段
def train(epoch):
print('\nEpoch: %d' % epoch)
# switch to train mode
net.train()
train_loss = 0
correct = 0
total = 0
# batch 数据
for batch_idx, (inputs, targets) in enumerate(trainloader):
# 将数据移到GPU上
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
# 先将optimizer梯度先置为0
optimizer.zero_grad()
# Variable表示该变量属于计算图的一部分,此处是图计算的开始处。图的leaf variable
inputs, targets = Variable(inputs), Variable(targets)
# 模型输出
outputs = net(inputs)
# 计算loss,图的终点处
loss = criterion(outputs, targets)
# 反向传播,计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 注意如果你想统计loss,切勿直接使用loss相加,而是使用loss.data[0]。因为loss是计算图的一部分,如果你直接加loss,代表total loss同样属于模型一部分,那么图就越来越大
train_loss += loss.data.item()
# 数据统计
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
if batch_idx == len(trainloader)-1:
print(batch_idx,'/', len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
# 测试阶段
def test(epoch):
global best_acc
# 先切到测试模型
net.eval()
test_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(testloader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs, volatile=True), Variable(targets)
outputs = net(inputs)
loss = criterion(outputs, targets)
# loss is variable , if add it(+=loss) directly, there will be a bigger ang bigger graph.
test_loss += loss.data.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
if batch_idx == len(testloader)-1:
print(batch_idx,'/', len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*correct/total, correct, total))
for epoch in range(start_epoch, start_epoch+200):
import time
start = time.clock()
train(epoch)
end = time.clock()
print(str(end-start))
test(epoch)
# 清除部分无用变量
torch.cuda.empty_cache()