字符串的模式匹配算法
首先,什么是模式匹配?
所谓模式匹配就是子串的定位操作,同时,该子串成为模式串。
注:下面的字串从下标1开始的,下标0存储字串的长度
简单算法(蛮力算法)
算法思想:
将s1第pos个字符起和模式串s2的第一个字符开始比较,如果相等,继续逐个比较后续字符;否则从主串s1的下一个字符起重新和模式串s2的第一个字符比较。直到模式串s2的每个字符都和主串s1中的连续的字符序列相等,成为匹配成功;否则不成功。
int Index (char× s1, char *s2, int pos)
//从s1[pos]开始和s2匹配,如果匹配,返回首次匹配的下标,如果不匹配返回-1
{
int l1 = (int) s1[0];
int l2 = (int) s2[0];
int i = pos, j = 1;
//i是s1中的下标,j是s2中的下标
while (i <= l1 && j <= l2)
{
if (s1[i] == s2[j])
{
i++;
j++;
}
else
{
i = i - j + 1;
j = 0;
}
}
if (j > l2)
return (i - j);
else
return -1;
}虽然上面的算法中只有一个while循环,但是由于i回溯的原因,在有些情况下效率很低。
在什么情况下效率比较低呢?
例如:模式串是”00001”,主串是”000000000000000000001”,在这种情况下,每次都会在模式串走到最后一位的时候,和主串不匹配,然后主串i回溯到刚才起始比较位置的下一位,模式串回到开头重新比较。while循环的次数执行了((index + 1) × m)次。n是主串长度,m是模式串长度。
通过这个极端例子,我们可以看到,这个算法在i的回溯上有很大的问题,如果和模式串匹配到靠后的位置的时候,遇到不相等的字符再回溯i会浪费很大的效率。
在最坏情况下复杂度很高,O(n * m)
改进1:首尾匹配算法
具体算法思路:就是每次匹配的时候,主串第i位字符和模式串第一个字符相等的时候,去比较一下它们的最后一个字符是否相等。相等的话,就进行上面算法过程;否则,从主串s1的下一个字符起重新和模式串s2的第一个字符比较。
这个改进主要解决上面的例题中的极端情况,可以看出来,这个算法并没有特别好的改变i回溯的这个问题,只是排除了一种极端情况,注意,只是一种,想象一下,如果我开始和结束的字符都相同,并且只有倒数第二个字符不相同,这种情况也是很浪费效率的。
算法具体实现不在这里写出了。
改进2:KMP算法
由以上两个算法的过程,我们都看到了i回溯会造成极大的效率浪费,我们就希望有一种算法能够让i不回溯,这就是KMP算法的思想。
算法思想:每当遇到不匹配的时候,i保持不动,将模式串向右滑动一段尽可能距离继续比较。
模式串又具体怎么移动?如何保证中间没有能够匹配的子串?
原理
模式串怎么移动?
首先解决第一个问题,模式串怎么移动?
当模式串的j在第k个字符处不匹配,那么模式串的前k-1个字符中,存在一个最大的m,使得前面从1到m的字符串和k-m-2到k-1字符串相同,这时只要将模式串的j移动到m+1和s2[i]比较就好。
例如:模式串是abac,当模式串中第4个字符’c’和主串不匹配的时候,我们将模式串的下标j移动到第2个字符’b’这里,让b去和主串比较,如果’b’也不匹配,就让j移动到第1个字符处比较,还不匹配,就让主串下标后移1位,和第1个字符比较。
如何保证中间没有能够匹配的子串?
第二个问题,如何保证在这中间没有能够其他匹配的子串?
图一:

图一说明:上面的是主串,下面的是模式串,其中标红部分为相等的字串,长度为m。而且主串从区域1到A之前的字串和模式串区域3到B之前的字串完全匹配。
由图一知道,上面的主串中1,2还有模式串中的3,4都是相等的字串(当然1,2和3,4可以有重叠)每个红色区域长度都是满足相等字串这个条件的那个最大的m了。
图二:
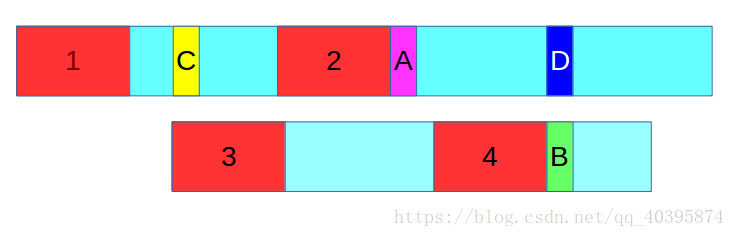
我们假设从中间蓝色部分的某个位置C开始到位置D的字串,是和模式串从头到B之前完全匹配的子串。
如图二,设从C到A这之间的子串长度为x(包括C不包括A),显然这个x是比m大的,因为红色区域2的长度等于m,而C到A的长度显然是大于红色区域2的长度。
那么模式串前x字符和C到A之间的字串相同的,
因为
我们的假设是让C到D位置的字串和模式串到B之前完全匹配的,那么C到A的字串是和模式串中前x个字符组成的字串完全匹配的(C到A是在C到D中的)。
由图一我们知道模式串从头到B之前的字串和主串从头到A之前的字串是相同的,也就是说,C到A之间的字串也等于B之前长度为x的字串,这就说明了,B这个字符前面有长度为x的前后相匹配的字串,而x>m,这样就得到了一个长度大于m的串,这和m是最大的矛盾,所以能够保证中间没有匹配的子串。
如下面图三,紫色小框框起来的是相同的子串。
图三:
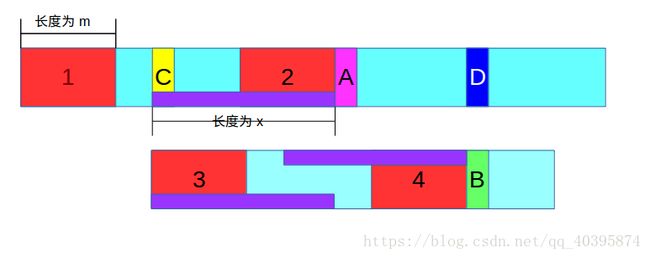
这里还是很重要的,一定要理解!!!
可能讲述的有些混乱,见谅。
实现
next辅助数组
在上面我们讲解了当失配的时候,我们应该移动模式串,next数组就是来记录的,next[j]就是模式串第j个位置失配的时候,应该移动到的位置。
那么如何得到这个next数组呢?
首先,next数组只取决与模式串,与主串无关。
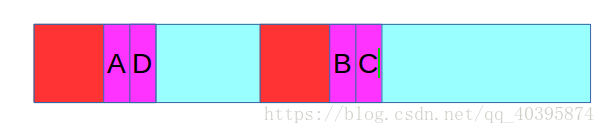
如下图四,条件:红色区域是相同字串,模式匹配时在B处不匹配,那么下标会移动到A处进行匹配。
会有两种情况
1、如果A和B处字符相等,那么我们可以知道,如果在C处不匹配,那么下标会移动到D处进行匹配。这是因为红色区域是最大长度的相同字串,如果A和B相等,对于C来说,它前面最大的长度的字串是红色区域加上B这个位置字符组成的字串。此时,C处的next值就等于B处的next值加1。
2、如果A和B处字符不相等,我们可以知道,对于C来说的m肯定比B的m小,因为如果C的m比B的m大的话,那么对于C来说的前后相等的红色区域肯定会包含B和A,但是B和A不等,这产生矛盾。这时,我们需要在红色区域里再去找前后相等的字串,然后判断前面区域下一位置的值是否和B位置的值相等,如果相等的话,C的next值就是这个下标加1,否则继续进行。
图四:
算法描述:
void Get_next (string T, int* next)
{
int l = (int) T.[0];
next[1] = 0;
int i = 1, j = next[i];
//i是前一个字符位置
while (i < l)
{
if (j == 0 || T[i] == T[j])
//j == 0 表示没有前后相同的字串,此时回到模式串开头
{
i++;
j++;
next[i] = j;
}
else
j = next[j];
}
}其实这样得到的next数组还可以进一步优化。
例如:模式串是这样的a a a a a b c,
我们的数组对应为
数组下标: 0 1 2 3 4 5 6
下标对应的值: -1 0 1 2 3 4 0
下标对应的字符:a a a a a b c
我们看到当模式串到下标为4的位置不匹配,下标会移到3,但是下标3和下标4的字符相同,所以还会移动到2,一直移动到0。所以,对于这个例题来说,下标1,2,3,4对应的值都可以直接赋值为0。
这样的数组我们称修正的next数组
void Get_nextval (string T, int* nextval)
{
int l = (int) T.[0];
next[1] = 0;
int i = 1, j = next[i]
while (i < l)
{
if (j == 0 || T[i] == T[j])
//j == 0表示没有前后相同的字串,此时回到模式串开头
{
i++;
j++;
if (T[i] != T[j])
nextval[i] = j;
else
nextval[i] = nextval[j];
}
else
j = nextval[j];
}
}KMP算法实现
有了nextval数组,我们就可以完成KMP算法的实现了
int index (string S, string T, int pos)
{
int i = pos, j = 1;
int ls = (int) S[0];
int lt = (int) T[0];
//生成辅助数组
int* nextval = new int [lt + 1];
Get_nextval(s, nextval);
while (i <= ls && j <= lt)
{
//j == 0表示模式串第一个字符和S[i]不相等
if (j == 0 || S[i] == T[j])
{
i++;
j++;
}
else
{
j = nextval[j];
}
}
if (j > lt)
return i-lt;
else
return -1;
}ACMKMP应用
补充说明
KMP算法复杂度为O(n * m),但是一般情况下,实际执行时间近似于O(n + m),因此至今仍被采用。
KMP算法仅仅在模式串和主串之间存在很多“部分匹配”的情况下才显得比蛮力算法快的多。
KMP算法最大特点是主串指针i不需要回溯,在整个匹配过程中,主串仅需从头到尾扫描一遍,这对处理从外设输入的庞大文件很有效,可以边读入边匹配,无需从头重读。