深度学习自学记录(2)——Keras迁移学习(升级版)+模型融合实现详解
最近时间充裕在学习深度学习,用博客记录一下自己的理解,毕竟好记性不如烂笔头。如果有错误的地方,希望大家指正,一起进步。如果这篇博客对你有帮助,点赞支持一下,码字不易。。。。。
迁移学习是深度学习中常用的一个手段,从头开始训练一个模型需要耗费大量的资源,在训练好的权重(预训练)的基础上训练自己的模型是迁移学习的重要思想。Keras 的应用模块(keras.applications)提供了带有预训练权值的深度学习模型,这些模型可以用来进行预测、特征提取和微调(fine-tuning)。关于keras.applications的详细应用可以参考博客,详细介绍了keras.applications的用法和一些具体的例子。
Keras迁移学习(升级版)实现详解
- 1、迁移学习用于图像分类(基础版)
- 2、迁移学习高级实现(升级版)
- 2.1 迁移部分模型
- 2.2 实现模型融合(多输入单输出,单输入单输出)
- 3、总结
1、迁移学习用于图像分类(基础版)
迁移学习通俗来讲就是把预训练权重当作模型的初始化权重,使得模型站在巨人的肩膀上训练。
我们通过一个例子来了解Keras中迁移学习用于图像分类的基础版实现,在预训练模型InceptionV3上微调训练出自己的模型。
首先来介绍一下调用keras.applications中InceptionV3模型时各参数的意义:
keras.applications.inception_v3.InceptionV3(include_top=False,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000)
各参数的意义:
include_top:是否保留顶层的全连接网络
weights:None代表随机初始化,即不加载预训练权重。'imagenet’代表加载预训练权重
input_tensor:可填入Keras tensor作为模型的图像输出tensor
input_shape:可选,仅当include_top=False有效,应为长为3的tuple,指明输入图片的shape,图片的宽高必须大于197,如(200,200,3)
pooling:当include_top=False时,该参数指定了池化方式。None代表不池化,最后一个卷积层的输出为4D张量。‘avg’代表全局平均池化,‘max’代表全局最大值池化。
classes:可选,图片分类的类别数,仅当include_top=True并且不加载预训练权重时可用。
返回值:Keras 模型对象
更多不同模型加载时的参数意义可参考Keras中文文档
迁移学习实现代码如下,在代码中详细介绍了每一步的实现
#首先导入相关的包,导入applications模块中的InceptionV3预训练模型
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing import image
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras import backend as K
#
# 第二步:构建完整模型
#include_top这个参数可以控制的是,到底要不要最后的这些全连接层。构建不带分类器的预训练模型
base_model = InceptionV3(weights='imagenet', include_top=False)
x = base_model.output
x = GlobalAveragePooling2D()(x)# 添加全局平均池化层
x = Dense(1024, activation='relu')(x)# 添加一个全连接层
predictions = Dense(200, activation='softmax')(x)# 自定义自己的分类器,这是一个200分类的分类器
model = Model(inputs=base_model.input, outputs=predictions)# 构建我们需要训练的完整模型
#第三步:在构建好的完整模型上用预训练权重开始训练,我们对模型进行两个训练
# 第一次训练:我们只训练随机初始化的层
# 锁住所有 InceptionV3 的卷积层
for layer in base_model.layers:
layer.trainable = False
# 编译模型(一定要在锁层以后操作)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# 在新的数据集上训练几代
model.fit_generator(...)
#第二次训练:开始微调Inception V3的卷积层,我们会锁住 Inception V3 中底下的几层,然后训练其余的顶层。
# 让我们看看每一层的名字和层号,看看我们应该锁多少层呢:
for i, layer in enumerate(base_model.layers):
print(i, layer.name)
# 我们选择训练最上面的两个 Inception block。也就是说锁住前面249层,然后放开之后的层。
for layer in model.layers[:249]:
layer.trainable = False
for layer in model.layers[249:]:
layer.trainable = True
# 我们需要重新编译模型,才能使上面的修改生效
# 让我们设置一个很低的学习率,使用 SGD 来微调
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy')
# 我们继续训练模型,这次我们训练最后两个 Inception block
# 和两个全连接层
model.fit_generator(...)
至此,就可以实现在InceptionV3预训练权重上训练一个符合自己数据特征的200分类的分类模型。
2、迁移学习高级实现(升级版)
我们已经实现了迁移学习,将整个InceptionV3的网络用于特征提取网络,但有时根据任务的需要,我们不需要将整个网络用特征提取,只需要迁移部分模型。有的时候还需要进行不同模型的融合。
2.1 迁移部分模型
我们已经实现了迁移学习,将整个InceptionV3的网络用于特征提取网络,但有时根据任务的需要,我们不需要将整个网络用特征提取,从网络的任意中间层中抽取特征用于迁移学习;这时候就只需要迁移部分模型。
首先,我们要先了解如何获得指定层的输出。有两种方法可以获得指定层的输出
第一种:自定义用于输出中间层的model
from keras.models import Model
base_model = InceptionV3(weights='imagenet', include_top=False)
layer_name = 'my_layer' # 给定待输出的层的名字
#自定义用于输出中间层的model
model = Model(inputs=base_model.input, outputs=base_model.get_layer(layer_name).output)
#获得指定层的输出
layer_name_features = model.predict(input_data)
第二中:通过定义Keras函数实现,用于输出指定层的输出
from keras import backend as K
# with a Sequential model
get_3rd_layer_output = K.function([model.layers[0].input],
[model.layers[3].output])
layer_output = get_3rd_layer_output([x])[0]
了解了如何获得指定层输出,下面看迁移部分模型用来训练的代码:与基础版相比只更改了第二步的代码。
# 第二步:构建完整模型
#include_top这个参数可以控制的是,到底要不要最后的这些全连接层。构建不带分类器的预训练模型
Inp = Input((224,224,3)) #定义一个输入层,输入图片尺寸为224x224
base_model = InceptionV3(weights='imagenet', include_top=False)
intermediate_layer_model = Model(inputs=base_model.input,outputs=base_model.get_layer('Layer_Name').output)
x = intermediate_layer_model(Inp)
x = GlobalAveragePooling2D()(x)# 添加全局平均池化层
x = Dense(1024, activation='relu')(x)# 添加一个全连接层
predictions = Dense(200, activation='softmax')(x)# 自定义自己的分类器,这是一个200分类的分类器
model = Model(inputs=base_model.input, outputs=predictions)# 构建我们需要训练的完整模型
Layer_Name可以根据自己的需要指定任意中间层,将代码与基础版的第二步换一下,就可以实现模型部分的迁移训练,灵活运用预训练模型。
2.2 实现模型融合(多输入单输出,单输入单输出)
不同的模型对同一张图片提取到的特征是不同的,在单独一个模型不能满足任务需求时,不妨试试模型融合,因为迁移训练不会增加太多的训练量,所以多个模型融合的训练量也在可以接受的范围内。
这里一共介绍3中模型融合方式,如下图所示。
第一种融合方式的实现和2.1迁移部分模型类似,将平均池化层和全连接层看作模型2特征提取器,最后的一层(Softmax层)看作分类器就可以实现了。
第二种为单输入单输出的模型融合,我们依然使用Keras的applications模块来实现,这里我们将VGG16和Resnet50两个模型的特征提取网络融合。模型1为Resnet50并加载预训练权重。
def model1():
base_model1 = choice_model(weights='imagenet',
include_top=False,
input_shape=(norm_size, norm_size, 3))
model = Model(inputs=base_model1.input, outputs=base_model1.get_layer('activation_43').output)
return model
模型2为VGG16并加载预训练权重。
def model2():
base_model2 = VGG16(weights='imagenet',
include_top=False,
input_shape=(norm_size, norm_size, 3))
model = Model(inputs=base_model2.input, outputs=base_model2.get_layer('block5_pool').output)
return model
将模型1和模型2提取到的特征进行融合,输入为224x224大小的图片,得到的model即为融合后的模型。
def merge_model( ):
inp = Input((224,224,3))
model_2 = model2()
model_1 = model1()
r1 = model_1(inp)
r2 = model_2(inp)
x = concatenate([r1,r2], axis=-1)
model = Model(inputs=inp, outputs=x)
return model
融合后的特征提取网络结构如图:

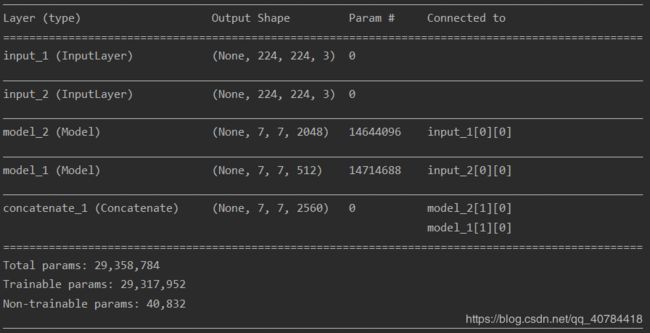
第三种为多输入单输出的模型融合,首先也是定义两个加载预训练权重的模型,不同的是在merge_model( )函数中定义了两个输入
##多输入单输出
def merge_model_2( ):
inp1 = Input((224,224,3))
inp2 = Input((224, 224, 3))
model_2 = model2()
model_1 = model1()
r1 = model_1(inp1)
r2 = model_2(inp2)
x = concatenate([r1,r2], axis=-1)
model = Model(inputs=[inp1,inp2], outputs=x)
return model
融合后的特征提取网络结构如图:
3、总结
(1)Keras内置的applications模块可以实现迁移学习,该模块的详细介绍见博客
(2)Keras有两种方法可以输出指定层的特征图,
第一种:自定义用于输出中间层的model
第二种:通过定义Keras函数实现,用于输出指定层的输出(我没用过。。。)
(3)Keras利用applications模块中自带的权重可以实现模型融合。
如果这篇博客对你有帮助,点赞支持一下,码字不易。。。。。