爬虫|爬取微博动态

爬取微博是爬虫新手入门项目,相对简单。但没想到还是遇到了些问题。。
0 踩点
老规矩第一步先踩点。某个用户的微博网址为:https://weibo.com/u/id,其中id是一长串数字,每个用户都有一个唯一的id对应。
打开网址后,右键-检查,切换到Network面板。往下滑,可以发现在微博加载出来的同时,Network也加载出来一些东西。推测这两者是有关系的。
在这个网址摸索一番之后没有任何收获,找不到有用的信息。
后来查阅资料发现,我打开的这个网址是PC端的,信息比较多,结构也比较复杂。一般来说,都是选择m端即mobile端也即手机端的页面进行爬取,虽然有时候信息会少一些,但是爬取难度低。
那要怎么打开m端页面呢?直接在PC端的网址前加个m.就行了!其实真正的m端网址是:https://m.weibo.cn/p/id2,但是加个m.就行了,会自动跳转到正确的m端网址去。id2和前面的PC端的id不一样,不过id2不重要,不需要研究他。
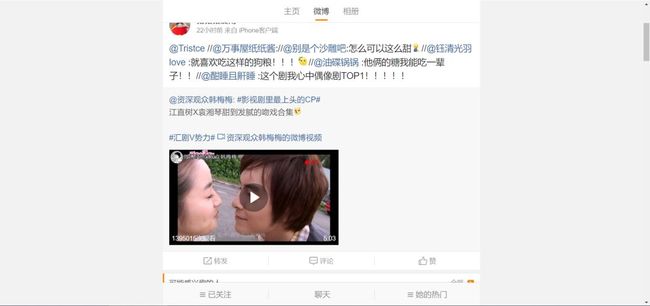
看起来就比PC端页面清爽多了啊...
接下来还是相同套路,右键-检查,切换到Network面板。往下滑,在加载出的文件中寻找可能有用的信息。耐心查找之后就可以发现:
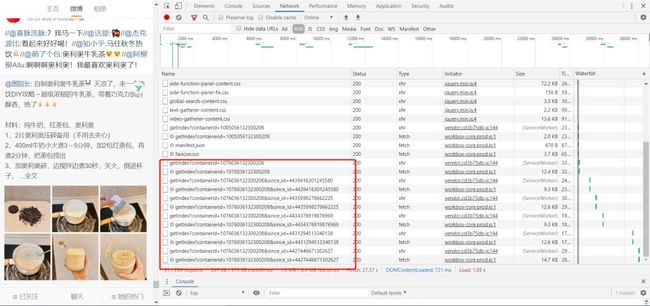
这一堆数据就是和微博动态相关的,随便打开一个就看到了相关信息。当然要想知道具体和微博中的什么信息对应,还要经过细心比对。

但是任务依然没有完成,因为我们没有发现前后数据的关系。
containerid是固定的,但是since_id却没有规律,或者说我们没有发现这个参数的规律,那么我们就无法实现自动爬取。
卡在这里挺久的,去往上查了资料发现不久(可能就几个月)前,还有一个参数page来表示是第几页的动态。
page=1就得到第1页的动态,page=2就得到page第2页的动态。page这个参数显然比since_id好用得多。
经过测试,我发现page参数还是能用的。
但是我认为我并没有解决问题,因为我没有自己从微博网页发现page参数!所以我继续寻找。
1 继续寻找
经过很多次且很随意的测试,我发现了一个更简洁的页面。先点击主页,然后划到最下面,再点击查看全部微博。

跳转到另一个页面:

这个页面又比刚刚的页面少了很多花里胡哨的东西。所以呢,还是那个套路。。
这次就发现了page参数,发现了有规律的网址!

又经过多次测试,发现只有containerid和page这两个参数是有用的,其他参数不影响,可以删除!我们现在终于知道微博动态所在的网址了。
2 代码
现在就可以开始写代码了。
包导入和变量定义。
import requestsfrom pyquery import PyQuery as pqfrom wordcloud import WordCloudfrom PIL import Imageimport jiebaimport numpy as npweibo_id = '' # 微博用户idbase_url = 'https://m.weibo.cn/api/container/getIndex?containerid=230413' + weibo_id + '&page='headers = {'Accept': 'application/json, text/plain, */*','MWeibo-Pwa': '1','Referer': 'https://m.weibo.cn/u/6132300208','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '+ 'Chrome/75.0.3770.100 Safari/537.36','X-Requested-With': 'XMLHttpRequest'}FILE_NAME = 'weibo.txt' # 保存微博文本内容IMG_PATH = 'love2.jpg' # 词云的形状
获得json格式的数据。
def get_content(page_num):url = base_url + str(page_num)response = requests.get(url, headers=headers)if response.status_code == 200: # 200表示正常,没被限制content_json = response.json()return content_jsonelse:return [] # 返回空列表
解析json,提取需要的文本内容。
def parse_json(content_json):text = ''if content_json:items = content_json.get('data').get('cards')for item in items:item = item.get('mblog')# 找到文本内容temp = pq(item.get('text')).text()pos = temp.find('/')# 把之前转发此微博的人发的文本内容去掉if pos != -1:temp = temp[:pos]text = text + temp# 找到转发的微博的文本内容# 如果此微博是本人发的,retweeted_status就不存在item = item.get('retweeted_status')if item:text = text + pq(item.get('text')).text() + '\n'return text
制作词云所需的函数。
def transform(text):word_list = jieba.cut(text)# 分词后在单独个体之间加上空格text = ' '.join(word_list)return textdef get_word_cloud():with open(FILE_NAME, 'r', encoding='utf-8') as f:img_matrix = Image.open(IMG_PATH)mask = np.array(img_matrix)wc = WordCloud(mask=mask, scale=4, font_path=r'C:\Windows\Fonts\simhei.ttf', background_color='white',max_font_size=40, min_font_size=2)text = f.read()text = transform(text)wc.generate(text)wc.to_file(weibo_id + 'wc.png')
词云在之前的文章介绍过,这里不再重复说了。移步B站爬虫。
主函数。
if __name__ == '__main__':all_text = '' # 保存所有的文本for page in range(1, 11):content_json = get_content(page)text = parse_json(content_json)all_text = all_text + text# 保存到文件with open(FILE_NAME, 'w', encoding='utf-8') as f:f.write(all_text)# 生成词云get_word_cloud()
3 结果
看一下结果吧。

所以这个人是什么状况看得一清二楚了。。可以分析的还有其他内容,比如分析时间,可以知道这个人在什么时间玩微博。
4 一点感想
很早就爬过微博了,本以为会是很简单的一次实践却遇到了困难。
靠自己解决了在网上找不到方法的问题。
第一次知道了还有m站这种东西。
新技能:爬取微博并制作词云get√
往期瞎写:
多目标进化算法在求解多值逻辑网络问题的应用!
在GitHub上大热的狗屁不通文章生成器是什么原理?
用Python小数据分析bilibili鬼畜巨头波澜哥(●'◡'●)
水平有限,如有错误,欢迎交流和批评指正!转载注明出处即可。
转自公众号「小z的笔记本」
每周更新各种内容
包括但不限于Python、爬虫、其他骚操作
欢迎关注
