3.23 docker---内存控制,cgroup,cpu控制,磁盘控制,docker-compose,docker-swam集群,K8s控制docker
一、docker内存控制
这里还没写好
二、对cpu的控制
1、系统对cpu的控制
1)查看系统的cgroup,cpu和memory
cgroup的介绍:https://blog.csdn.net/woniu_slowly/article/details/38317973
查看cgroup
[root@foundation38 kiosk]# cd /sys/fs/cgroup/
[root@foundation38 cgroup]# ls
blkio cpu,cpuacct freezer net_cls perf_event
cpu cpuset hugetlb net_cls,net_prio pids
cpuacct devices memory net_prio systemd
查看cpu
[root@foundation38 cgroup]# cd cpu
[root@foundation38 cpu]# ls
cgroup.clone_children cpuacct.usage cpu.rt_runtime_us release_agent
cgroup.event_control cpuacct.usage_percpu cpu.shares system.slice
cgroup.procs cpu.cfs_period_us cpu.stat tasks
cgroup.sane_behavior cpu.cfs_quota_us machine.slice user.slice
cpuacct.stat cpu.rt_period_us notify_on_release
查看memory
[root@foundation38 cpu]# cd ../memory/
[root@foundation38 memory]# ls
cgroup.clone_children memory.memsw.failcnt
cgroup.event_control memory.memsw.limit_in_bytes
cgroup.procs memory.memsw.max_usage_in_bytes
cgroup.sane_behavior memory.memsw.usage_in_bytes
machine.slice memory.move_charge_at_immigrate
memory.failcnt memory.numa_stat
memory.force_empty memory.oom_control
memory.kmem.failcnt memory.pressure_level
memory.kmem.limit_in_bytes memory.soft_limit_in_bytes
memory.kmem.max_usage_in_bytes memory.stat
memory.kmem.slabinfo memory.swappiness
memory.kmem.tcp.failcnt memory.usage_in_bytes
memory.kmem.tcp.limit_in_bytes memory.use_hierarchy
memory.kmem.tcp.max_usage_in_bytes notify_on_release
memory.kmem.tcp.usage_in_bytes release_agent
memory.kmem.usage_in_bytes system.slice
memory.limit_in_bytes tasks
memory.max_usage_in_bytes user.slice
2)、在cpu目录下创建目录,会继承cpu的内容
[root@foundation38 memory]# cd ../cpu
[root@foundation38 cpu]# mkdir x1
[root@foundation38 cpu]# cd x1/
[root@foundation38 x1]# ls
cgroup.clone_children cpuacct.usage_percpu cpu.shares
cgroup.event_control cpu.cfs_period_us cpu.stat
cgroup.procs cpu.cfs_quota_us notify_on_release
cpuacct.stat cpu.rt_period_us tasks
cpuacct.usage cpu.rt_runtime_us
[root@foundation38 x1]# cat cpu.cfs_period_us ##cpu分配的周期(微秒),默认为100000份
100000
[root@foundation38 x1]# cat cpu.cfs_quota_us ##表示该control group限制占用的时间,默认-1不限制
-1
[root@foundation38 x1]# echo 20000 > cpu.cfs_quota_us
[root@foundation38 x1]# dd if=/dev/zero of=/dev/null & ##占用资源,
[1] 5071
测试
1、使用top查看,会发现占用百分百资源 ##top命令,按1显示cpu,按q退出
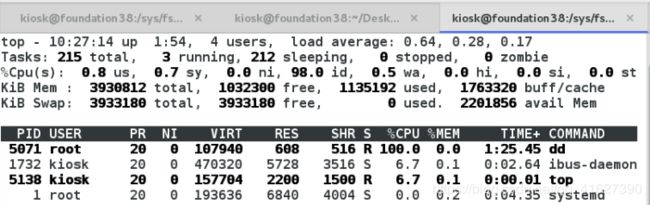
2、将限制放入任务中,会变为百分之20
[root@foundation38 x1]# echo 5071 > tasks

2、docker对cpu的控制
1)不限制
[root@foundation38 images]# docker run -it --name vm2 --rm ubuntu
root@ea19644b0ed7:/# dd if=/dev/zero of=/dev/null &
[1] 17
2)限制
[root@foundation38 images]# docker run -it --name vm1 --cpu-quota=20000 ubuntu
root@bfc257073173:/# dd if=/dev/zero of=/dev/null &
[1] 17
三、磁盘的控制
1、容器权限的提供
1)、原始的容器是没有权限的
[root@foundation38 images]# docker run -it --rm ubuntu
root@c628b3f55ce4:/# fdisk -l
root@9469fd2074da:/# ip addr
1: lo:
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
31: eth0@if32:
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
root@9469fd2074da:/# ip addr add 172.17.0.3/24 dev eth0
RTNETLINK answers: Operation not permitted
2)给与所有权限
[root@foundation38 images]# docker run -it --rm --privileged=true ubuntu
root@03a147043820:/# fdisk -l
Disk /dev/sda: 320.1 GB, 320072933376 bytes
255 heads, 63 sectors/track, 38913 cylinders, total 625142448 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk identifier: 0x000d7490
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 617275391 308636672 83 Linux
/dev/sda2 617275392 625141759 3933184 82 Linux swap / Solaris
3)只给与网络权限
[root@foundation38 images]# docker run -it --rm --cap-add=NET_ADMIN ubuntu
root@9718a15093f6:/# ip addr add 172.17.0.3/24 dev eth0
root@9718a15093f6:/# ip addr
1: lo:
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
33: eth0@if34:
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.17.0.3/24 scope global eth0
valid_lft forever preferred_lft forever
root@9718a15093f6:/#
2、磁盘写入速度的限制
[root@foundation38 dev]# docker run -it --rm --device-write-bps /dev/sda:30MB ubuntu
root@539fb0318ea2:/# dd if=/dev/zero of=file bs=1M count=100 oflag=direct
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 3.31911 s, 31.6 MB/s
3、实现磁盘的分离
1)、安装软件
yum install -y lxcfs-2.0.5-3.el7.centos.x86_64.rpm
[root@server1 ~]# cd /var/lib/lxcfs/
[root@server1 lxcfs]# ls
[root@server1 lxcfs]# cd
2)、创建目录
[root@server1 ~]# lxcfs /var/lib/lxcfs/ &
[1] 2733
[root@server1 ~]# hierarchies:
0: fd: 5: devices
1: fd: 6: cpuset
2: fd: 7: memory
3: fd: 8: hugetlb
4: fd: 9: cpuacct,cpu
5: fd: 10: perf_event
6: fd: 11: blkio
7: fd: 12: pids
8: fd: 13: freezer
9: fd: 14: net_prio,net_cls
10: fd: 15: name=systemd
[root@server1 ~]# cd /var/lib/lxcfs/
[root@server1 lxcfs]# ls
cgroup proc
3)、运行容器并挂载目录,发现容器的磁盘与主机的磁盘隔离
[root@server1 ~]# docker run -it --name vm1 -m 200m -v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo -v /var/lib/lxcfs/proc/diskstats:/proc/diskstats -v /var/lib/lxcfs/proc/meminfo:/proc/meminfo -v /var/lib/lxcfs/proc/stat:/proc/stat -v /var/lib/lxcfs/proc/swaps:/proc/swaps -v /var/lib/lxcfs/proc/uptime:/proc/uptime ubuntu
root@33b59e1f219f:/# free -m
total used free shared buffers cached
Mem: 200 5 194 8 0 0
-/+ buffers/cache: 5 194
Swap: 200 0 200
root@33b59e1f219f:/#
三、docker compose
一群容器的上下线

Docker Compose 将所管理的容器分为三层,工程(project),服务(service)以及容器
(contaienr)。Docker Compose 运行的目录下的所有文件(docker-compose.yml, extends 文
件或环境变量文件等)组成一个工程,若无特殊指定工程名即为当前目录名。一个工程当
中可包含多个服务,每个服务中定义了容器运行的镜像,参数,依赖。一个服务当中可包
括多个容器实例,Docker Compose 并没有解决负载均衡的问题,因此需要借助其他工具实
现服务发现及负载均衡。
Docker Compose 是一个用来创建和运行多容器应用的工具。使用 Compose 首先需要编写
Compose 文件来描述多个容器服务以及之间的关联,然后通过命令根据配置启动所有的容
器。
Dockerfile 可以定义一个容器,而一个 Compose 的模板文件(YAML 格式)可以定义一个
包含多个相互关联容器的应用。Compose 项目使用 python 编写,基于后面的实验中我们
将学习的 Docker API 实现。
1)、将docker-compose放到二进制目录下
[root@server1 ~]# ls
docker lxcfs-2.0.5-3.el7.centos.x86_64.rpm
docker-compose-Linux-x86_64-1.22.0 nginx.tar
haproxy.tar ubuntu.tar
[root@server1 ~]# mv docker-compose-Linux-x86_64-1.22.0 /usr/local/bin/docker-compose
[root@server1 compose]# chmod +x /usr/local/bin/docker-compose
2)、创建docker-compose的配置文件
[root@server1 ~]# cd /tmp/
[root@server1 tmp]# ls
[root@server1 tmp]# mkdir docker
[root@server1 tmp]# cd docker/
[root@server1 docker]# mkdir compose
[root@server1 docker]# cd compose/
[root@server1 compose]# vim docker-compose.yml
编辑如下
web1:
image: nginx
expose:
- 80
volumes:
- ./web1:/usr/share/nginx/html
web2:
image: nginx
expose:
- 80
volumes:
- ./web2:/usr/share/nginx/html
haproxy:
image: haproxy
volumes:
- ./haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro
links:
- web1
- web2
ports:
- "80:80"
expose:
- "80"
3)编辑各个服务器的目录,并编辑发布目录
web1和web2的默认发布目录
[root@server1 compose]# mkdir web1
[root@server1 compose]# mkdir web2
[root@server1 compose]# echo web1 > web1/index.html
[root@server1 compose]# echo web2 > web2/index.html
[root@server1 compose]# ls web1/
index.html
haproxy的目录
[root@server1 compose]# mkdir haproxy
[root@server1 compose]# cd haproxy/
[root@server1 haproxy]# vim haproxy.cfg
编辑如下
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
stats uri /status
frontend balancer
bind 0.0.0.0:80
default_backend web_backends
backend web_backends
balance roundrobin
server server1 web1:80 check
server server2 web2:80 check
[root@server1 haproxy]# cd ..
[root@server1 compose]# pwd
/tmp/docker/compose
[root@server1 compose]# ls
docker-compose.yml haproxy web1 web2
4)加载镜像
[root@server1 compose]# cd
[root@server1 ~]# docker load -i nginx.tar
Loaded image: nginx:latest
[root@server1 ~]# docker load -i haproxy.tar
[root@server1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest e548f1a579cf 13 months ago 109MB
westos.org/nginx latest e548f1a579cf 13 months ago 109MB
westos.org/game2048 latest 19299002fdbe 2 years ago 55.5MB
haproxy latest fbd1f55f79b3 3 years ago 139MB
ubuntu latest 07c86167cdc4 3 years ago 188MB
5)启动docker-compose
[root@server1 ~]# cd -
/tmp/docker/compose
[root@server1 compose]# docker-compose up -d
Creating compose_web1_1 ... done
Creating compose_web2_1 ... done
Creating compose_haproxy_1 ... done
查看日志
[root@server1 compose]# docker-compose logs
Attaching to compose_haproxy_1, compose_web2_1, compose_web1_1
haproxy_1 | <7>haproxy-systemd-wrapper: executing /usr/local/sbin/haproxy -p /run/haproxy.pid -f /usr/local/etc/haproxy/haproxy.cfg -Ds
测试:
1、访问172.25.38.1,实现论寻


2、访问172.25.38.1/status 查看状态

3、关闭,删除与重新设定
[root@server1 compose]# docker-compose stop
Stopping compose_haproxy_1 ... done
Stopping compose_web2_1 ... done
Stopping compose_web1_1 ... done
[root@server1 compose]# docker-compose rm
Going to remove compose_haproxy_1, compose_web2_1, compose_web1_1
Are you sure? [yN] y
Removing compose_haproxy_1 ... done
Removing compose_web2_1 ... done
Removing compose_web1_1 ... done
[root@server1 compose]# docker-compose up -d
Creating compose_web1_1 ... done
Creating compose_web2_1 ... done
Creating compose_haproxy_1 ... done
五、docker swam 集群
docker公司的三剑客:
- Docker Machine
- Docker Compose
- Docker Swarm
1、集群搭建实现论寻
1)初始化swarm
[root@server1 ~]# docker swarm init
Swarm initialized: current node (ww7t8yqzki2y98lbt4uu3ccoc) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-4yt97m3e0pax24k4bz31cvngcxkpekjz1d07m68dt1oyiao8h6-4mf26myoh7d6f5pvfte92vadb 172.25.38.1:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
2)加入节点
[root@server2 ~]# docker swarm join --token SWMTKN-1-4yt97m3e0pax24k4bz31cvngcxkpekjz1d07m68dt1oyiao8h6-4mf26myoh7d6f5pvfte92vadb 172.25.38.1:2377
This node joined a swarm as a worker.
[root@server3 ~]# docker swarm join --token SWMTKN-1-4yt97m3e0pax24k4bz31cvngcxkpekjz1d07m68dt1oyiao8h6-4mf26myoh7d6f5pvfte92vadb 172.25.38.1:2377
This node joined a swarm as a worker.
查看节点
[root@server1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
ww7t8yqzki2y98lbt4uu3ccoc * server1 Ready Active Leader 18.06.1-ce
ow4ovviw59r7atnwy0aibin5i server2 Ready Active 18.06.1-ce
j2dw9g4kbuw5ttf91i48ffhtj server3 Ready Active 18.06.1-ce
yum install -y bridge-utils
[root@server1 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024288de750f no
docker_gwbridge 8000.0242ce2f3f24 no veth19e11d1
veth5c13cf6
3)创建server集群
创建自己使用的网络
[root@server1 ~]# docker network create -d overlay my_net1
xhvxuojeoj70ce4lk7bwgqz09
创建集群
[root@server1 ~]# docker service create --name web --network my_net1 --publish 80:80 --replicas 3 nginx
image nginx:latest could not be accessed on a registry to record
its digest. Each node will access nginx:latest independently,
possibly leading to different nodes running different
versions of the image.
4hjwk703scdph55pyhmzsqa7f
overall progress: 3 out of 3 tasks
1/3: running
2/3: running
3/3: running
verify: Service converged
[root@server1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
87ac069e074a nginx:latest "nginx -g 'daemon of…" 37 seconds ago Up 31 seconds 80/tcp web.3.jf1vo5t6dtn7alx392augzpvl
[root@server1 ~]vim index.html
[root@server1 ~]# docker cp index.html 87ac069e074a:/usr/share/nginx/html
[root@server2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ce594e709682 nginx:latest "nginx -g 'daemon of…" About a minute ago Up About a minute 80/tcp web.1.lvdauqh8es80uyztenlawfcmt
[root@server2 ~]vim index.html
[root@server2 ~]# docker cp index.html ce594e709682:/usr/share/nginx/html
[root@server3 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
acf39493ac1b nginx:latest "nginx -g 'daemon of…" About a minute ago Up About a minute 80/tcp web.2.akmftvlbc02m3kjl19m1agplq
[root@server3 ~]vim index.html
[root@server3 ~]# docker cp index.html acf39493ac1b:/usr/share/nginx/html
测试:
注意关闭防火墙
[root@foundation38 images]# for i in {1..10}; do curl 172.25.38.1; done
server1
server3
server2
server1
server3
server2
server1
server3
server2
server1
2、对集群的监控
1)载入镜像
[root@server1 ~]# docker load -i visualizer.tar
5bef08742407: Loading layer 4.221MB/4.221MB
5f70bf18a086: Loading layer 1.024kB/1.024kB
0a19bde117a5: Loading layer 60.01MB/60.01MB
f7e883283ebc: Loading layer 3.942MB/3.942MB
dfd8ee95c7e7: Loading layer 1.536kB/1.536kB
300a6cad969a: Loading layer 8.704kB/8.704kB
d1627040da6d: Loading layer 489kB/489kB
00ed018016c5: Loading layer 2.56kB/2.56kB
d5aa1ab1b431: Loading layer 4.096kB/4.096kB
2d6a463420f7: Loading layer 4.608kB/4.608kB
53888d7f4cca: Loading layer 2.56kB/2.56kB
ea93ed99abca: Loading layer 2.598MB/2.598MB
fa467b43abc0: Loading layer 4.096kB/4.096kB
94cd25765710: Loading layer 96.48MB/96.48MB
Loaded image: dockersamples/visualizer:latest
2)创立监控容器
[root@server1 ~]# docker service create \
> --name=viz \
> --publish=8080:8080/tcp \
> --constraint=node.role==manager \
> --mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
> dockersamples/visualizer
image dockersamples/visualizer:latest could not be accessed on a registry to record
its digest. Each node will access dockersamples/visualizer:latest independently,
possibly leading to different nodes running different
versions of the image.
6xyuht1m47qecekwsxzf9nlxm
overall progress: 1 out of 1 tasks
1/1: running
verify: Service converged
3)查看容器
[root@server1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5344c9353ebf dockersamples/visualizer:latest "npm start" About a minute ago Up About a minute (healthy) 8080/tcp viz.1.poim25hfey3doplbaq4drp8sp
87ac069e074a nginx:latest "nginx -g 'daemon of…" 10 minutes ago Up 10 minutes 80/tcp web.3.jf1vo5t6dtn7alx392augzpvl
测试:
1、访问:172.25.38.1:8080

2、修改服务的规模为6
[root@server1 ~]# docker service scale web=6
web scaled to 6
overall progress: 6 out of 6 tasks
1/6: running
2/6: running
3/6: running
4/6: running
5/6: running
6/6: running
verify: Service converged
查看监控
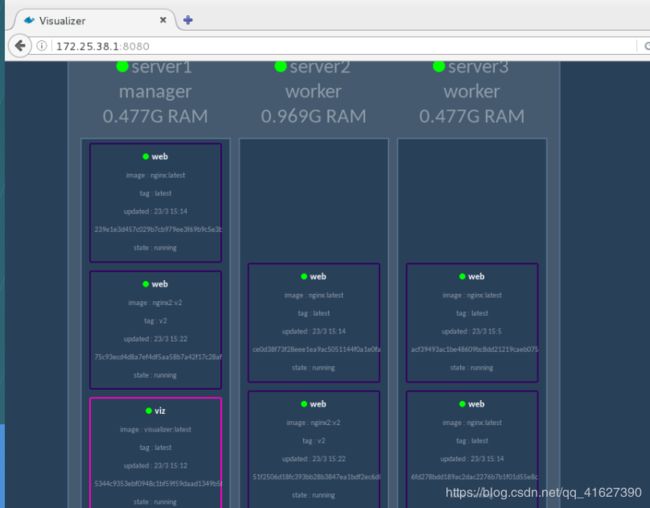
3、更新服务内容
1)重命名镜像,模拟新的服务
[root@server1 ~]# docker tag nginx:latest nginx2:v2
2)更新服务
--update-delay 5s ##每5秒更新一次
--update-parallelism 2 web ##每次更新两个
[root@server1 ~]# docker service update --image nginx2:v2 --update-delay 5s --update-parallelism 2 web
image nginx2:v2 could not be accessed on a registry to record
its digest. Each node will access nginx2:v2 independently,
possibly leading to different nodes running different
versions of the image.
web
overall progress: 6 out of 6 tasks
1/6: running
2/6: running
3/6: running
4/6: running
5/6: running
6/6: running
verify: Service converged
在服务中查看监控:


~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
六、k8s
kubernetes,简称K8s,是用8代替8个字符 “ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高 效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。 [1]
传统的应用部署方式是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容 器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地, 容器比虚拟机轻量、更“透明”,这更便于监控和管理。
实验环境:删除源先的docker swarm
[root@server2 anzhuangbao]# docker swarm leave
Node left the swarm.
[root@server3 anzhuangbao]# docker swarm leave
Node left the swarm.
[root@server1 ~]# docker swarm leave --force
Node left the swarm.
[root@server3 tar]# docker container prune
1、server1,2,3.安装 kubeadm
[root@server1 ~]# yum install -y kubeadm-1.12.2-0.x86_64.rpm kubelet-1.12.2-0.x86_64.rpm kubectl-1.12.2-0.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm cri-tools-1.12.0-0.x86_64.rpm
2、server1,2,3.关闭swapoff,开机启动,载入镜像
[root@server1 ~]# swapoff -a
[root@server1 ~]# vim /etc/fstab ##
#/dev/mapper/rhel-swap swap swap defaults 0 0
[root@server1 ~]# df -h
[root@server1 ~]# systemctl enable kubelet.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /etc/systemd/system/kubelet.service.
[root@server1 ~]# systemctl start kubelet.service
[root@server1 ~]# kubeadm config images list
I0323 16:50:43.447921 16529 version.go:93] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
I0323 16:50:43.448006 16529 version.go:94] falling back to the local client version: v1.12.2
k8s.gcr.io/kube-apiserver:v1.12.2
k8s.gcr.io/kube-controller-manager:v1.12.2
k8s.gcr.io/kube-scheduler:v1.12.2
k8s.gcr.io/kube-proxy:v1.12.2
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.2.24
k8s.gcr.io/coredns:1.2.2
加载镜像
11 docker load -i coredns.tar
12 docker load -i kube-apiserver.tar
13 docker load -i kube-scheduler.tar
14 docker load -i etcd.tar
15 docker load -i kube-controller-manager.tar
16 docker load -i pause.tar
17 docker load -i kube-proxy.tar
18 docker load -i flannel.tar
3、初始化
[root@server1 ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=172.25.38.1
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 172.25.85.1:6443 --token fkpqn8.1ws2abhq7qrakw59 --discovery-token-ca-cert-hash sha256:aa71b8de1a85d55f884b29544e2cf7f76387e0b25b4dc8a3eca22d1988d48269
4、创建用户,添加用户
[root@server1 k8s]# useradd k8s
[root@server1 k8s]# vim /etc/sudoers
91 root ALL=(ALL) ALL
92 k8s ALL=(ALL) NOPASSWD: ALL
5、按照kubeadm初始化后的指令来做
[root@server1 k8s]# su k8s
[k8s@server1 k8s]$ cd
[k8s@server1 ~]$ mkdir -p $HOME/.kube
[k8s@server1 ~]$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[k8s@server1 ~]$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
[k8s@server1 ~]$ echo " source < (kubectl completion bash)" >> ./.bashrc
[k8s@server1 ~]$ vim .bashrc
source <(kubectl completion bash)
6、复制并运行.yml文件
[root@server1 k8s]# cp *.yml /home/k8s/
[k8s@server1 ~]$ kubectl apply -f kube-flannel.yml
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.extensions/kube-flannel-ds-amd64 created
daemonset.extensions/kube-flannel-ds-arm64 created
daemonset.extensions/kube-flannel-ds-arm created
daemonset.extensions/kube-flannel-ds-ppc64le created
daemonset.extensions/kube-flannel-ds-s390x created
发现多了几个容器
[k8s@server1 ~]$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d53a57cf8108 k8s.gcr.io/pause:3.1 "/pause" 7 seconds ago Up 2 seconds k8s_POD_coredns-576cbf47c7-f8lqt_kube-system_7aa9ab95-4d69-11e9-86e8-5254007c8875_0
133a87918ec7 k8s.gcr.io/pause:3.1 "/pause" 7 seconds ago Up 2 seconds k8s_POD_coredns-576cbf47c7-b7lp7_kube-system_7a794351-4d69-11e9-86e8-5254007c8875_0
7、server2和3添加节点
server2
[root@server2 tar]# kubeadm join 172.25.85.1:6443 --token fkpqn8.1ws2abhq7qrakw59 --discovery-token-ca-cert-hash sha256:aa71b8de1a85d55f884b29544e2cf7f76387e0b25b4dc8a3eca22d1988d48269
[root@server2 tar]# modprobe ip_vs_wrr ip_vs_sh
server3
[root@server3 tar]# modprobe ip_vs_wrr
[root@server3 tar]# modprobe ip_vs_sh
[root@server3 tar]# kubeadm join 172.25.85.1:6443 --token fkpqn8.1ws2abhq7qrakw59 --discovery-token-ca-cert-hash sha256:aa71b8de1a85d55f884b29544e2cf7f76387e0b25b4dc8a3eca22d1988d48269
测试
1、查看节点
[k8s@server1 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 26m v1.12.2
server2 Ready
server3 Ready
2、查看命名空间
[k8s@server1 ~]$ kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-server1 1/1 Running 0 34m
kube-system kube-apiserver-server1 1/1 Running 0 35m
kube-system kube-controller-manager-server1 1/1 Running 3 35m
kube-system kube-flannel-ds-amd64-5hx9c 1/1 Running 1 10m
kube-system kube-flannel-ds-amd64-m74vx 1/1 Running 0 15m
kube-system kube-flannel-ds-amd64-nvdtx 1/1 Running 0 13m
kube-system kube-proxy-2cv2c 1/1 Running 0 35m
kube-system kube-proxy-6q7cn 1/1 Running 0 10m
kube-system kube-proxy-mklts 1/1 Running 0 13m
kube-system kube-scheduler-server1 1/1 Running 4 34m
注意
这里要保证有网络,如果出现如下,可以删除节点,自动添加查看
[k8s@server1 ~]$ kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-576cbf47c7-b7lp7 0/1 CrashLoopBackOff 5 26m
kube-system coredns-576cbf47c7-f8lqt 0/1 CrashLoopBackOff 5 26m
kube-system etcd-server1 1/1 Running 0 25m
kube-system kube-apiserver-server1 1/1 Running 0 26m
kube-system kube-controller-manager-server1 1/1 Running 1 26m
kube-system kube-flannel-ds-amd64-5hx9c 1/1 Running 1 95s
kube-system kube-flannel-ds-amd64-m74vx 1/1 Running 0 7m
kube-system kube-flannel-ds-amd64-nvdtx 1/1 Running 0 4m36s
kube-system kube-proxy-2cv2c 1/1 Running 0 26m
kube-system kube-proxy-6q7cn 1/1 Running 0 95s
kube-system kube-proxy-mklts 1/1 Running 0 4m36s
kube-system kube-scheduler-server1 1/1 Running 1 25m
[k8s@server1 ~]$ kubectl describe pod coredns-576cbf47c7-b7lp7 -n kube-system ##查看信息
[k8s@server1 ~]$ kubectl logs coredns-576cbf47c7-b7lp7 -n kube-system ##查看日志
[k8s@server1 ~]$ kubectl delete pod coredns-576cbf47c7-b7lp7 -n kube-system ##删除节点