声明:本文参考:
对长沙房地产数据的挖掘与分析【一】
对长沙房地产数据的挖掘与分析【二】
本文介绍:
1,抓取目标:URL="http://cs.lianjia.com/xiaoqu/rs/",如下图:
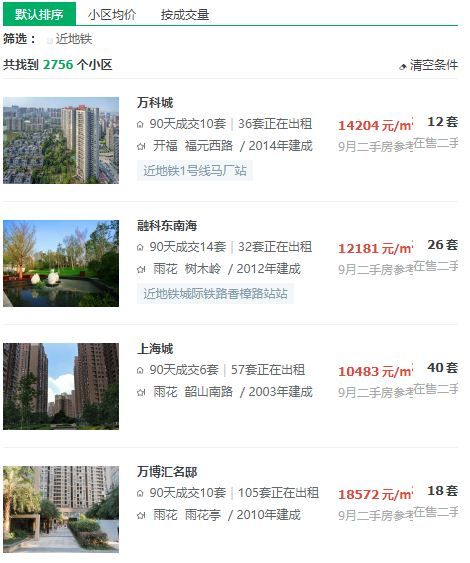
截图00.jpg
点击进入单个小区的详细信息页面,可以看到如下图:
我们抓取的信息包括:1、小区名称,2、小区均价,3,房价参考时间,4、小区地址,5、建成时间,6、建筑类型,7、物业费用,8、物业公司,9、开发商,10、楼栋总数,11、房屋总数

截图01.jpg
3,代码思路:
1)请求并解析目标主页:URL=" http://cs.lianjia.com/xiaoqu/rs/",获取每个小区名称,链接和ID,并存入MongoDB数据库。
2)访问数据库,获取每个小区的链接,请求并解析,获取目标信息
4,代码如下:
#coding=utf-8
#本代码抓取:小区名称+链接+ID
#coding=utf-8
import requests
from bs4 import BeautifulSoup
from lxml import html
from pymongo import MongoClient
import time
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
client=MongoClient()
dbName='lianjia'
dbTable='xiaoqu'
tab=client[dbName][dbTable]
def get_urls(url):
urls=[]
titles=[]
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'cs.lianjia.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
}
r=requests.get(url,headers=headers).content
soup=BeautifulSoup(r,'html.parser')
url_ul=soup.find('ul',attrs={'class':'listContent'})
url_all=url_ul.find_all('a',attrs={'class':'img'})
for i in url_all:
urls.append(i['href'])
#urls列表装的是爬取的各个小区的链接
HTML=html.fromstring(r)
title=HTML.xpath('//div[@class="content"]//li//div[@class="title"]/a/text()')# 使用text()提取标签中间的文字:爬取到小区名称列表
id=HTML.xpath('//ul[@class="listContent"]/li/@data-id')
for ii in range(0,30):
data={'url':urls[ii],'xiaoqu':title[ii],'ID':id[ii]}
tab.insert(data)
return data
main_url='http://cs.lianjia.com/xiaoqu/rs/'
get_urls(main_url)
print u'第1页爬取成功!'
## 存在问题:重复跑的话,数据库里的数据会有重复项
k=input("please enter the total page num that you want to crawl:")
for kk in xrange(2,k+1):
print u'开始爬取第%s页!'%(str(kk))
main_url2='http://cs.lianjia.com/xiaoqu/pg%s/'%(str(kk))
get_urls(main_url2)
print u'成功爬取第%s页!'%(str(kk))
time.sleep(1)
抓取结果如下:
第一列是小区链接,第二列是小区名称,第三列是小区ID(抓取小区ID的目的是为了用于后文抓取历史成交价格信息)
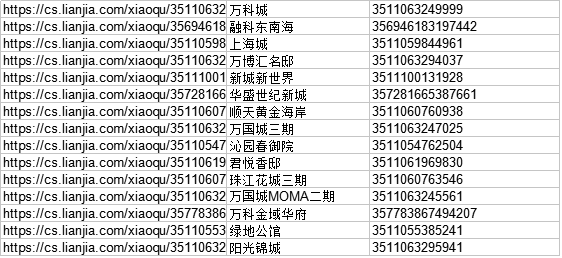
image.png
#本代码用于抓取小区的详细信息
#coding=utf-8
from lxml import html
from pymongo import MongoClient
import time
import requests
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
client = MongoClient()
dbName = 'lianjia'
dbTable = 'xiaoqu'
tab = client[dbName][dbTable] # 创建表单1用于储存抓取的各小区链接
dbTable2 = 'xiaoqu_detail_0916'
tab2 = client[dbName][dbTable2]
xiaoqus=tab.find()
for x in xiaoqus:
if x:
url=x['url']
print url
if not tab2.find_one({'url':url}):
key=dict()
info=[]
r=requests.get(url).content
HTML=html.fromstring(r)
key[u'小区名称']=HTML.xpath('//h1[@class="detailTitle"]/text()')[0]
key[u'小区地址']=HTML.xpath('//div[@class="detailDesc"]/text()')[0]
key[u'小区均价'] = HTML.xpath('//span[@class="xiaoquUnitPrice"]/text()')[0]
key[u'均价参考时间'] = HTML.xpath('//span[@class="xiaoquUnitPriceDesc"]/text()')[0]
info= HTML.xpath('//div[@class="xiaoquInfoItem"]/span[@class="xiaoquInfoContent"]/text()')
key[u'建成时间'] = info[0]
key[u'建筑类型'] = info[1]
key[u'物业费'] = info[2]
key[u'物业公司'] = info[3]
key[u'开发商'] = info[4]
key[u'楼栋总数'] = info[5]
key[u'房屋总数'] = info[6]
tab2.insert(key)
print u'抓取小区信息成功!'
time.sleep(1)
else:
print u'已爬取过该小区,无需再次爬取!'
抓取结果如下:

image.png
至此抓取各个小区的详细信息完成。接下来抓取各个小区的历史成交价格信息。
比如像万科的历史成交记录页面链接是:“https://cs.lianjia.com/chengjiao/c3511063249999/”,是利用前面抓取的小区ID构造该链接的,链接页面如下:
抓取的信息包括:1、房源名称,2、房源位置,3、成交总价(单位:万),4、成交均价(单位:元/平方米),5、成交日期,6,成交周期
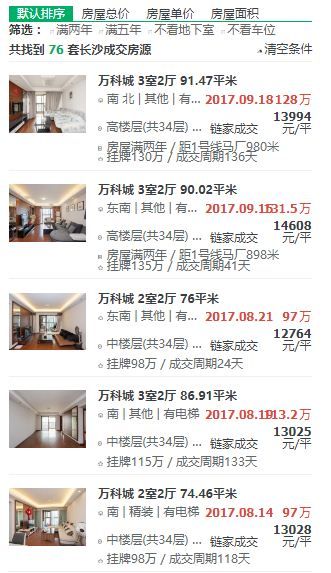
截图02.jpg
代码如下:
#本代码利用前文抓取的小区ID构造小区详细页面的链接,并存入数据库
#coding=utf-8
from lxml import html
from pymongo import MongoClient
import time
import requests
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
client = MongoClient()
dbName = 'lianjia'
dbTable = 'xiaoqu'
tab = client[dbName][dbTable] # 创建表单1用于储存抓取的各小区链接
dbTable2 = 'xiaoqu_deal_url'
tab2 = client[dbName][dbTable2]
xiaoqus=tab.find()
for x in xiaoqus:
url='https://cs.lianjia.com/chengjiao/c%s'%x['ID']
data={u'小区名称':x['xiaoqu'],u'成交页面链接':url}
tab2.insert(data)
代码运行结果如下:

image.png
#本代码利用数据库里的小区详细页面的链接,需要获取页码,构造分页链接,并请求解析获取各个小区的历史成交记录信息
#coding=utf-8
from lxml import html
from pymongo import MongoClient
import time
import requests
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
client = MongoClient()
dbName = 'lianjia'
dbTable = 'xiaoqu_deal_url' #
dbTable2= 'xiaoqu_price'
tab = client[dbName][dbTable] # 连接成交页面的链接的数据表单
tab2= client[dbName][dbTable2] # 连接用于存放历史成交信息的表单
deal_url=tab.find() # 获取数据库里全部的成交记录页面链接的字典集合
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'cs.lianjia.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
}
def get_page_num(url):#此函数用于获取页码,用于构造分页的链接
r=requests.get(url).content
HTML=html.fromstring(r)
page=HTML.xpath('//div[@class="contentBottom clear"]/div[@class="page-box fr"]/div[@class="page-box house-lst-page-box"]/@page-data')[0]#获取页码所在字符串
return page[13]#页码在字符串的第14位
def con_url():# 该函数利用页码,构造分页链接,抓取数据存入数据库
for url in deal_url: #url同样为字典
url_1=url[u'成交页面链接'] # 索引取出链接
page_num=get_page_num(url_1) # 调用函数,取出页码
url_11=url_1[0:33]#将链接分为两部分url_11和url_12,再链接构造起来
url_12=url_1[33:]
print url[u'小区名称'],page_num
for num in range(1,int(page_num)+1):# page_num是字符串,需int转化为数值型
URL=url_11+'pg'+'{}'.format(num)+url_12 #URL为构造的分页链接,接下来利用该链接进行抓取
r=requests.get(URL,headers=headers).content
HTML=html.fromstring(r)
title=HTML.xpath('//ul[@class="listContent"]/li/div[@class="info"]/div[@class="title"]/a/text()')
#title为成交房源名称
deal_date=HTML.xpath('//ul[@class="listContent"]/li/div[@class="info"]/div[@class="address"]/div[@class="dealDate"]/text()')
#deal_date为成交日期
total_price=HTML.xpath('//ul[@class="listContent"]/li/div[@class="info"]/div[@class="address"]/div[@class="totalPrice"]/span/text()')
#total_price为成交总价(单位:万)
position=HTML.xpath('//ul[@class="listContent"]/li/div[@class="info"]/div[@class="flood"]/div[@class="positionInfo"]/text()')
#position为成交房源位置
unit_price=HTML.xpath('//ul[@class="listContent"]/li/div[@class="info"]/div[@class="flood"]/div[@class="unitPrice"]/span/text()')
#unit_price为成交单价(单位:元/平方米)
deal_cycle=HTML.xpath('//ul[@class="listContent"]/li/div[@class="info"]/div[@class="dealCycleeInfo"]/span[@class="dealCycleTxt"]/span[last()]/text()')
#deal_cycle为成交周期(单位:天)
for i in range(0,len(title)): # len计算总共几个成交记录
data={'titel':title[i],'deal_date':deal_date[i],'total_price':total_price[i],'position':position[i],'unit_price':unit_price[i],'deal_cycle':deal_cycle[i]}
tab2.insert(data)
con_url()
抓取的结果如下:

image.png
本文结束。