【Python】20Newsgroup文本分类(TF-IDF向量化,十种sklearn分类器)
数据集介绍
数据集链接:http://qwone.com/~jason/20Newsgroups/(比较慢,建议Science上网)
当然这里用不到这个数据集,sklearn导入会自动下载,倘若比较慢,可参考:sklearn.datasets.fetch_20newsgroups的下载速度极慢采用离线下载导入等别的方法
具体实践中,稍等了一会儿就好了的。
sklearn自带数据集datasets,划分好训练集和测试集了。
from sklearn.datasets import fetch_20newsgroups #获取数据集
通过函数封装调用skearn分类器
最开始,参考于这篇博客:
使用sklearn和tf-idf变换的针对20Newsgroup数据集做文本分类
打算通过函数调用的方式来划分清楚各个分类方法:
def SGD():#随机梯度下降
from sklearn.linear_model.stochastic_gradient import SGDClassifier
return SGDClassifier()
def MultinomialNB(): #朴素贝叶斯(naive bayes)
from sklearn.naive_bayes import MultinomialNB
return MultinomialNB()
def LogisticRegression(): #逻辑回归
from sklearn.linear_model import LogisticRegression
return LogisticRegression()
def Svm(train_x, train_y): #支持向量机
from sklearn.svm import SVC
return SVC()
def Knn(train_x, train_y): #K近邻
from sklearn.neighbors import KNeighborsClassifier
return KNeighborsClassifier()
def RandomForest(train_x, train_y): #随机森林
from sklearn.ensemble import RandomForestClassifier
return RandomForestClassifier()
def DecisionTree(train_x, train_y): #决策树
from sklearn.tree import DecisionTreeClassifier
return DecisionTreeClassifier()
认真分析下,感觉还是有点啰嗦,故有了下面更为简洁的版本:
十种sklearn常用分类方法
具体是不是大家常用的不清楚,个人感觉平时常用的应该就是这些了。
from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.neighbors import KNeighborsClassifier #K近邻
from sklearn.linear_model.logistic import LogisticRegression #逻辑回归
from sklearn.linear_model.stochastic_gradient import SGDClassifier #随机梯度下降(适合稀疏矩阵)
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.ensemble import AdaBoostClassifier #平时就是叫AdaBoost
from sklearn.ensemble import GradientBoostingClassifier #梯度提升决策树(比较慢)
from sklearn.neural_network.multilayer_perceptron import MLPClassifier #多层感知器(比较慢)
from sklearn.svm import SVC #支持向量机(比较慢)
参数均为默认值,倘若需要配置参数什么的,可参考上面提到的“函数封装”法
将文章数据向量化(TF-IDF算法)
TF-IDF可参考我这篇(建议多查查别的资料了解了解):
【Python】向量空间模型:TF-IDF实例实现(set.union())
from sklearn.feature_extraction.text import TfidfVectorizer #TF-IDF文本特征提取
vectorizer = TfidfVectorizer()
train_v=vectorizer.fit_transform(train.data)
test_v=vectorizer.transform(test.data)
选取部分数据进行分类
选取20个类中7种比较典型的类别进行实验
select = ['alt.atheism','comp.graphics','misc.forsale','rec.autos',
'sci.crypt','soc.religion.christian','talk.politics.guns']
train=fetch_20newsgroups(subset='train',categories=select)
test=fetch_20newsgroups(subset='test',categories=select)
循环遍历分类器
分类器可以直接一个list装好,遍历即可:
Classifier = [MultinomialNB(),DecisionTreeClassifier(),KNeighborsClassifier()]
但考虑到每个方法输出正确率时,还需要分类器名字,所以:
Classifier_str = ['MultinomialNB()','DecisionTreeClassifier()','KNeighborsClassifier()',
'LogisticRegression()','SGDClassifier()','RandomForestClassifier()',
'AdaBoostClassifier()','GradientBoostingClassifier()','MLPClassifier()','SVC()']
for i in Classifier_str:
model = eval(i)
model.fit(train_v,train.target)
print(i+"准确率为:",model.score(test_v,test.target))
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
输出
1、选取7种比较典型类别数据预测结果:

十种分类器的分类结果都达到了及格线
其中适合稀疏矩阵的SGD和多层感知器的预测结果最为不错
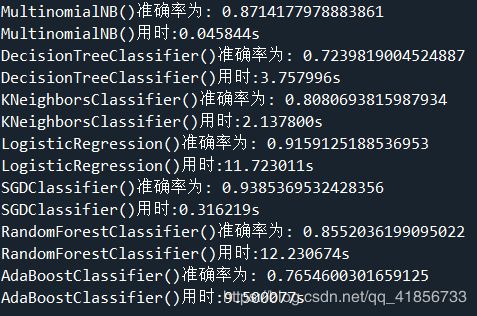
2、选取全部数据,十种分类算法结果:
或许我应该记录每种算法运行时间?

其中前7种分类方法比较快,后3种花费时间约是总时间的95%
完整代码
import time
t0=time.time()
print('程序开始的时间:',time.strftime('%H:%M:%S',time.localtime(time.time())))
import numpy as np
from sklearn.datasets import fetch_20newsgroups #获取数据集
from sklearn.feature_extraction.text import TfidfVectorizer #TF-IDF文本特征提取
#平时常用的一些分类方法
from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.neighbors import KNeighborsClassifier #K近邻
from sklearn.linear_model.logistic import LogisticRegression #逻辑回归
from sklearn.linear_model.stochastic_gradient import SGDClassifier #随机梯度下降(适合稀疏矩阵)
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.ensemble import AdaBoostClassifier #平时就是叫AdaBoost
from sklearn.ensemble import GradientBoostingClassifier #梯度提升决策树(慢)
from sklearn.neural_network.multilayer_perceptron import MLPClassifier #多层感知器(慢)
from sklearn.svm import SVC #支持向量机(慢)
#选取20个类中7种比较典型的类别进行实验
select = ['alt.atheism','comp.graphics','misc.forsale','rec.autos',
'sci.crypt','soc.religion.christian','talk.politics.guns']
train=fetch_20newsgroups(subset='train',categories=select)
test=fetch_20newsgroups(subset='test',categories=select)
#train=fetch_20newsgroups(subset='train')
#test=fetch_20newsgroups(subset='test')
#将文章数据向量化(TF-IDF算法)
vectorizer = TfidfVectorizer()
train_v=vectorizer.fit_transform(train.data)
test_v=vectorizer.transform(test.data)
Classifier = [MultinomialNB(),DecisionTreeClassifier(),KNeighborsClassifier(),
LogisticRegression(),SGDClassifier(),RandomForestClassifier()]
Classifier_str = ['MultinomialNB()','DecisionTreeClassifier()','KNeighborsClassifier()',
'LogisticRegression()','SGDClassifier()','RandomForestClassifier()',
'AdaBoostClassifier()','GradientBoostingClassifier()','MLPClassifier()','SVC()']
for i in Classifier_str:
t2=time.time()
model = eval(i)
model.fit(train_v,train.target)
print(i+"准确率为:",model.score(test_v,test.target))
print(i+'用时:%.6fs'%(time.time()-t2))
#y_predict=model.predict(test_v)
#print(np.mean(y_predict==test.target))
t1=time.time()
print('程序结束的时间:',time.strftime('%H:%M:%S',time.localtime(time.time())))
print("用时:%.2fs"%(t1-t0))
部分新结果:
部分参考资料
用20 newsgroups数据来进行NLP处理之文本分类
20 newsgroups数据介绍以及文本分类实例